这是 Python 进阶课的第三节 - Pandas 上,进阶课的目录如下:
NumPy 上
NumPy 下
之前基础版的 11 节的目录如下:
编程概览
元素型数据
容器型数据
流程控制:条件-循环-异常处理
函数上:低阶函数
-
函数下:高阶函数
类和对象:封装-继承-多态-组合
字符串专场:格式化和正则化
解析表达式:简约也简单
生成器和迭代器:简约不简单
装饰器:高端不简单
学习任何东西 (这回以 Pandas 举例) 先来谈谈我的学习思路,主干线是 WHY-WHAT-HOW-HOW WELL,看这种思路是不是符合你的胃口:
WHY
下图左边的「二维 NumPy 数组」 仅仅储存了一组数值 (具体代表什么意思却不知道),而右边的「数据帧 DataFrame」一看就知道这是平安银行和茅台从 2018-1-3 到 2019-1-3 的价格。
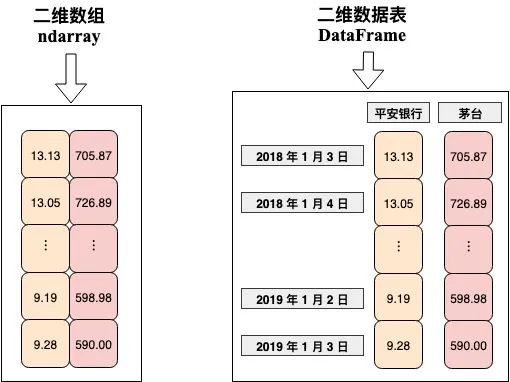
Pandas 的数据结构在每个维度上都有可读性强的标签,比起 NumPy 的数据结构涵盖了更多信息。
此外 Pandas 主要是为异质 (heterogeneous) 的表格 (tabular) 数据而设计的,而 NumPy 主要是为同质 (homogeneous) 的数值 (numerical) 数据而设计的。
WHAT
Pandas DataFrame 是一种数据结构 (Series 可不严谨的看成一维的 DataFrame,而 Panel 已经被废弃)。DataFrame 数据帧可以看成是
数据帧 = 二维数组 + 行索引 + 列索引
在 Pandas 里出戏的就是行索引和列索引,它们
HOW
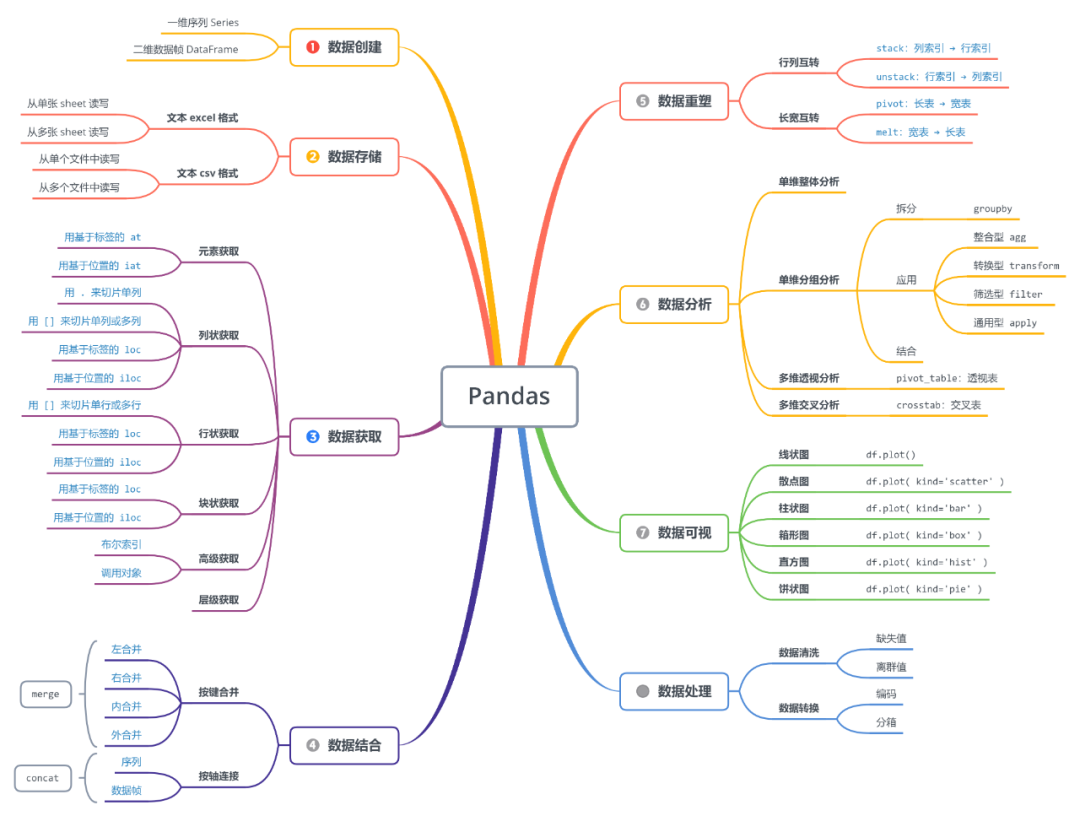
了解完数据帧本质之后,我们可从 Pandas 功能角度来学习它:
数据创建 (不会创建那还学什么)
数据存载 (存为了下次载,载的是上回存)
数据获取 (基于位置、基于标签、层级获取)
数据结合 (按键合并、按轴结合)
数据重塑 (行列互转、长宽互转)
数据分析 (split-apply-combine, pivot_table, crosstab)
数据可视 (df.plot( kind='type') )
-
数据处理 (处理缺失值和离群值、编码离散值,分箱连续值)
总体内容用思维导图来表示。
HOW WELL
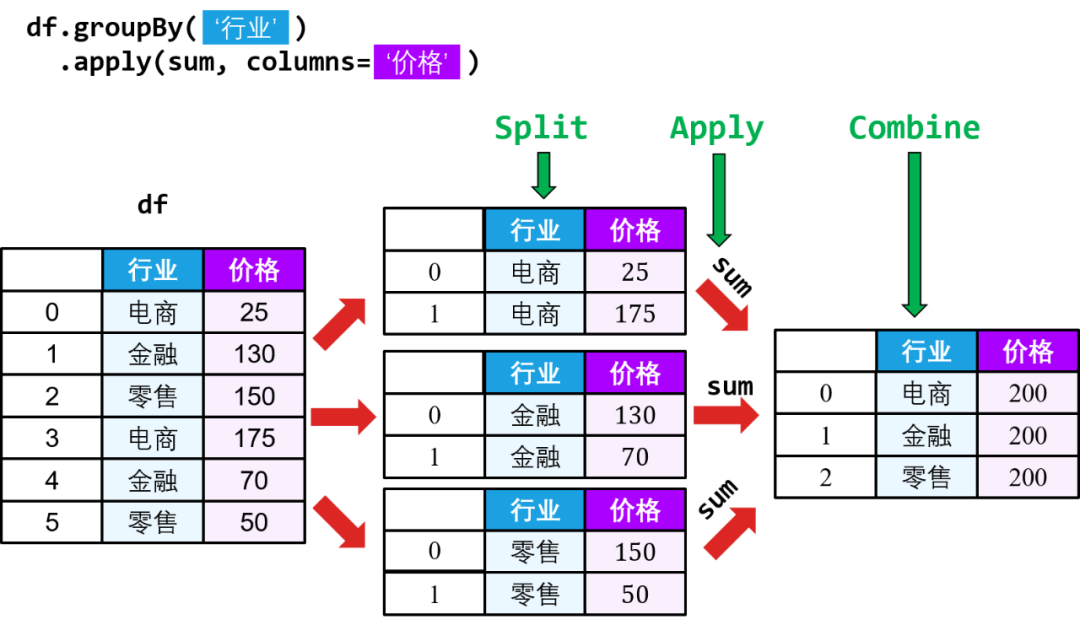
比如在讲拆分-应用-结合 (split-apply-combine) 时,我会先从数据帧上的 sum() 或 mean() 函数引出无条件聚合,但通常希望有条件地在某些标签或索引上进行聚合。这时数据会根据某些规则分组 (split),然后应用 (apply) 同样的函数在每个组,最后结合 (combine) 成整体。
这波操作称被 Hadley Wickham 称之为拆分-应用-结合,具体而言,该过程有三步:
在 split 步骤:将数据帧按照指定的“键”分组
在 apply 步骤:在各组上平行执行四类操作:
整合型 agg() 函数
转换型 transform() 函数
筛选型 filter() 函数
通用型 apply() 函数
在 combine 步骤:操作之后的每个数据帧自动合并成一个总体数据帧
一图胜千言:
付费用户(付 1 赠 1)可以获得:








