
人对于Python学习创建了一个小小的学习圈子,为各位提供了一个平台,大家一起来讨论学习Python。欢迎各位私信小编进群 一起讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力及对世界的认知方式,因此,我们与时俱进,迎接变化,并不断的成长,掌握Python核心技术,才是掌握真正的价值所在。

前言
HTML文档是互联网上的主要文档类型,但还存在如TXT、WORD、Excel、PDF、csv等多种类型的文档。网络爬虫不仅需要能够抓取HTML中的敏感信息,也需要有抓取其他类型文档的能力。下面简要记录一些个人已知的基于python3的抓取方法,以备查阅。
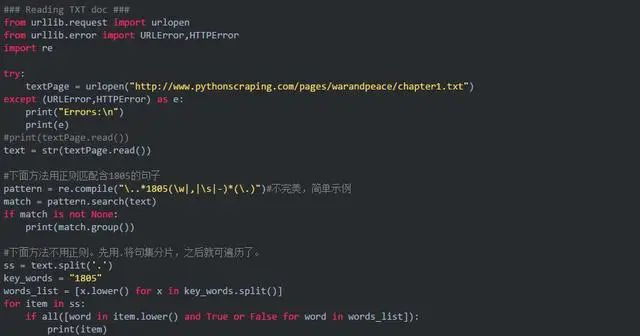
抓取TXT文档
在python3下,常用方法是使用urllib.request.urlopen方法直接获取。之后利用正则表达式等方式进行敏感词检索。
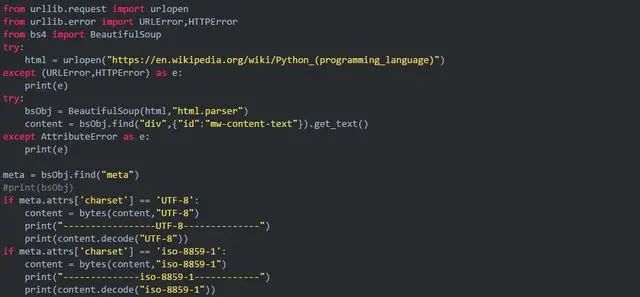
如果抓取的是某个HTML,最好先分析,例如:
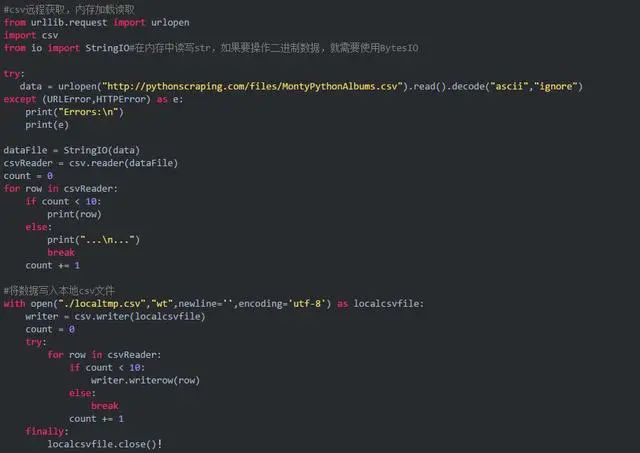
抓取CSV文档
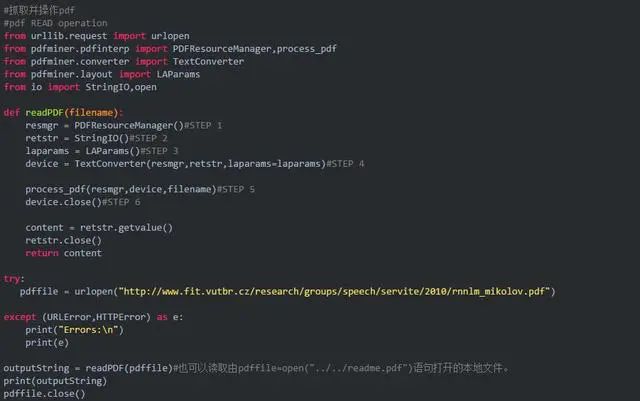
抓取PDF文档
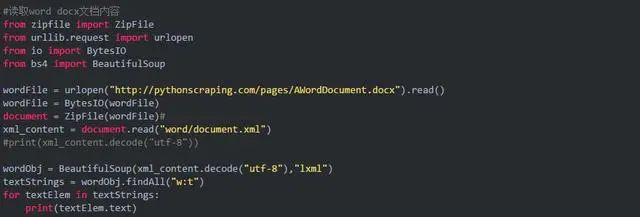
抓取word
方法:
(1)利用urlopen抓取远程word docx文件;
(2)将其转换为内存字节流;
(3)解压缩(docx是压缩后文件);
(4)将解压后文件作为xml读取
(5)寻找xml中的标签(正文内容)并处理
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
觉得不错,点个“在看”然后转发出去










