这是 Python 进阶课的第四节 - Pandas 下,进阶课的目录如下:
NumPy 上
NumPy 下
Pandas 上
之前基础版的 11 节的目录如下:
编程概览
元素型数据
容器型数据
流程控制:条件-循环-异常处理
函数上:低阶函数
函数下:高阶函数
类和对象:封装-继承-多态-组合
字符串专场:格式化和正则化
解析表达式:简约也简单
生成器和迭代器:简约不简单
装饰器:高端不简单
本次课程主要从数据分析、数据可视和数据处理来玩转 Pandas:
数据分析
Pandas 被公认为数据分析 (data analysis) 的神器,从四方面来讲解:
单维整体分析:对每个特征下的值做整合求指标
-
多维分组分析:先在一个或多个特征下分组,再对每组中其他特征下的值做整合求指标
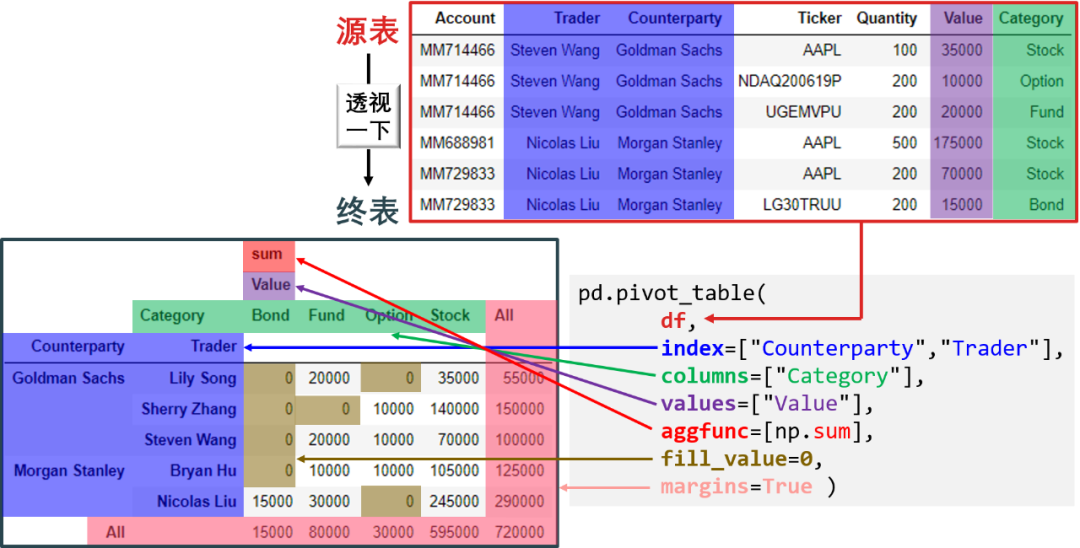
多维透视分析:透视表将源表的若干列分组作为终表的“支点”,然后在新行和新列的维度上做整合。
多维交叉分析:交叉表是透视表的特例,其默认的整合函数是计算个数或频率。
两张图就把透视表 (pivot_table) 和交叉表 (crosstab) 讲的清清楚楚。

数据可视
数据可视 (data visualization) 是本次课程第二部分的内容,提到画图那么一定会提到 matplotlib 和 seaborn 这两个最常用的工具包。但在 Pandas 直接使用
Series.plot()
DataFrame.plot()
可以快速可视化数据。注意,画出来的图不会很好看而且含信息量也不全,但能快速的展示出数据的核心关系。如要继续个性化图表,那么才使用 matplotlib, seaborn 甚至 bokeh, plotly, pyecharts 和 altair 等。
数据处理
最后一部分内容是数据处理 (data munging),前面所有的数据都是经过处理过而变得“干净”,但在实际工作做数据一开始都是“杂乱”的,因此第一步都是要做处理,主要可以归纳成两大方面:
付费用户(付 1 赠 1)可以获得:







