自编码器介绍
自编码器(AE,autoencoder)通常包括两部分:编码器和解码器。编码器将高维输入样本映射到低维抽象表示,实现样本压缩与降维;解码器则将抽象表示转换为期望输出,实现输入样本的复现。
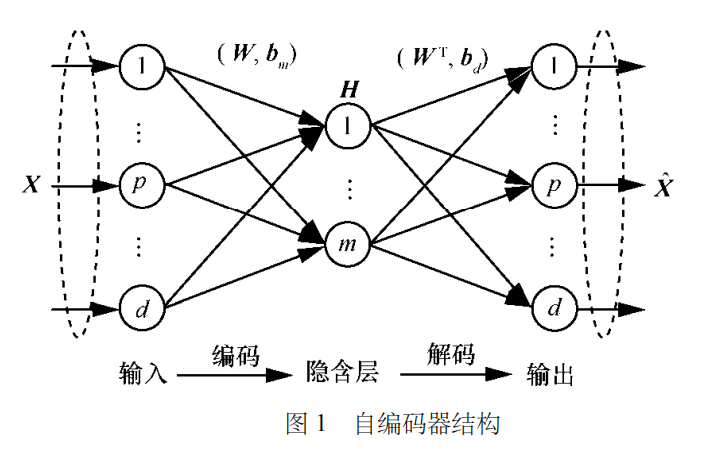
网络结构
与全连接神经网络相同,自编码器节点连接方式也为全连接,但由于采用无监督学习范式,自编码器的输入输出均为无标签样本,不需要标签信息,旨在学习样本的内在结构,提取抽象特征。传统全连接网络采用有监督学习范式,其输出为样本标签,旨在完成特征到标签的映射。
训练过程
自编码器的训练过程包括编码、解码和损失计算3个阶段:
- 调整网络参数使重构误差达到最小值,以获得输入特征的最优抽象表示。
自编码器的改进方法
稀疏自编码器
稀疏自编码器(SAE, sparse autoencoder)在自编码器中添加稀疏性限制,以发现样本中的特定结构,避免网络对恒等函数的简单学习。
稀疏性限制需要在损失函数上添加关于激活度的正则化项,对过大的激活度加以惩罚,以降低隐含层节点激活度。通常采用 L1 范数或 KL 散度正则化项。
稀疏自编码器能够有效学习重要特征,抑制次要特征,提取的抽象特征维度更低,更具稀疏性。
降噪自编码器
为避免传统自编码器学习到无编码功能的恒等函数,降噪自编码器引入了退化过程。
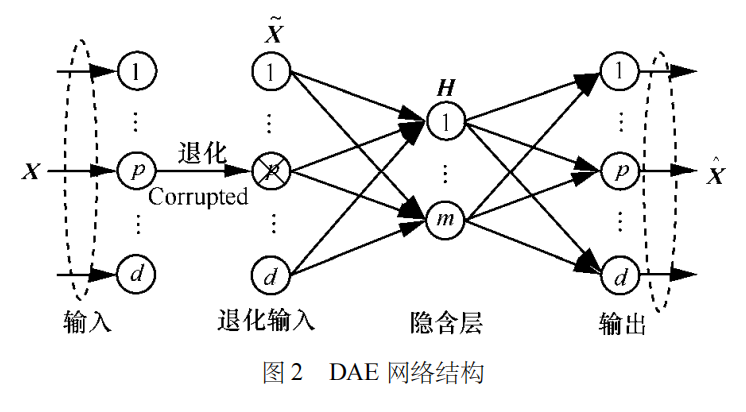
在退化过程中对输入样本添加噪声,以改变输入样本的数据分布,而后通过训练重构无噪声的样本,防止自编码器简单地将输入复制到输出,迫使提取的抽象特征更加反映样本本质、更具稳健性。
收缩自编码器
收缩自编码器在传统自编码器的基础上,通过在损失函数上添加收缩正则化项,迫使编码器学习到有更强收缩作用的特征提取函数,提升对输入样本小扰动的稳健性,防止对恒等函数的学习。
收缩自编码器能够抵抗输入样本存在的一定扰动,提取到的抽象特征具有更强的稳健性。收缩自编码器通过内部因素提升特征提取稳健性,而降噪自编码器则是通过外部因素提高特征提取稳健性。
变分自编码器
变分自编码器旨在通过对样本分布的学习,采用估计分布近似逼近样本真实分布,进而由估计分布生成原始样本的类似样本。
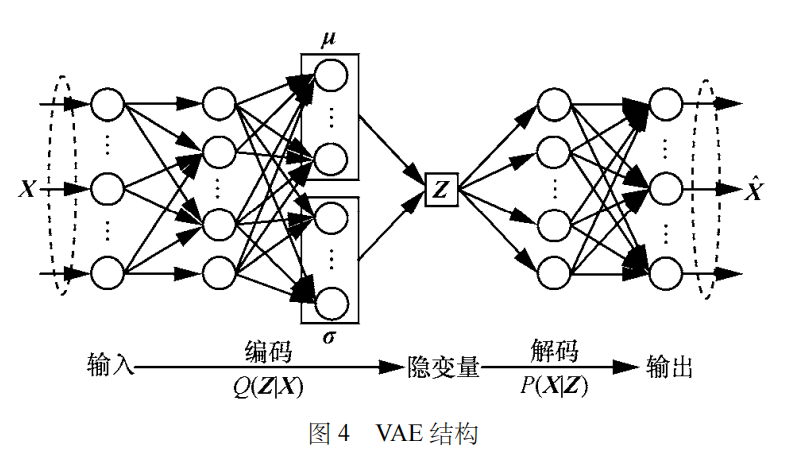
变分自编码器属于生成模型,能够估计样本的真实分布,进而生成类似样本,但也因此不能直接应用于分类与回归任务中。
其他算法
除上述算法以外,研究者还提出了其他自编码器改进算法,包括区分自编码器、范数自编码器、对抗自编码器。
这些改进算法主要通过 3 种方式对自编码器进行创新:
- 对损失函数增加特定的正则化约束,改善所提取特征的特定性质;
自编码器与竞赛
在结构化 & 非结构化数据竞赛中自编码器主要用于以下场景:
缺失值填充
在有监督 & 无监督任务中,自编码器可对数据进行恢复并进行填充。自编码器的填充效果比常规方法有效,具体的流程也可以参考MICE流程。
模型预训练
参考BERT模型的Mask LM或者表格预训练任务,在训练有监督任务之前使用预训练方法进行训练。
特征提取
在结构化数据集中,特别是匿名数据集中可以使用降噪自编码器来进行训练。先使用自编码进行训练,然后进行有监督训练。
△长按添加竞赛小助手
添加Coggle小助手微信(ID : coggle666)
每天Kaggle算法竞赛、干货资讯汇总
与 24000+来自竞赛爱好者一起交流~











