在Elasticsearch中,每个查询请求都被发送到索引中的每个分片,然后分别扫描这些分片中的每个段(segment)。 Elasticsearch以每个段为基础缓存查询,以加快响应时间。
在Elasticsearch中,文档中的每个字段可以以两种形式存储:精确值或全文。 精确值(如时间戳或年份)的存储与其索引的方式完全相同,因为您不希望收到查询1/1/16为“2016年1月1日”。如果字段以全文形式存储 ,这意味着它将被分析 - 基本上,它被分解成分词,根据分析器的类型,标点符号和停用词如“是”或“the”可能被删除。 分析器将字段转换为规范化的格式,使其能够匹配更广泛的查询。
看这样一个例子,假设您有一个类型(type)名为location的索引, location的每个文档都包含一个字段city,它被存储为经过分析(analyzed)的字符串。 你索引两个文档:一个在city字段包含“St. Louis”,另一个包含“St. Paul”。 每个字符串将被转成小写,并去掉标点符号,变成词项。 这些词项(terms)被存储在一个倒排索引里,看起来像这样:
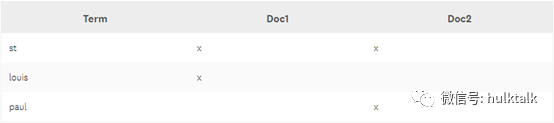
分析(analysis)的好处就是当你检索“st.”的时候,所有包含这个词项的文档都会被检索出来。如果您将city这个字段存储为精确值,只有检索“St. Louis”或者“St. Paul”这样的精确值,才能匹配到结果。
Elasticsearch使用两种主要类型的缓存来更快地提供搜索请求:Fielddata和Filter。










