
本文约1900字,建议阅读8分钟
本文为你介绍PyMC3原理,并结合一个实际案例教你如何使用包实现计算。我们经常从天气预报中听到:明天的降水率是80%。这意味着什么?我们很难直白地解释这种说法,尤其是从概率学派的角度:无限次(或非多次)地重复下雨/不下雨实验是不现实的。贝叶斯方法可以解释这种说法。以下句子摘自《为黑客设计的概率规划与贝叶斯方法》一书,它完美地总结了贝叶斯学派的关键思想之一。
贝叶斯世界观将概率解释为事件可信度的量度,即我们对事件发生有多少信心。这意味着在贝叶斯方法中,我们永远不能绝对确定自己的“信念”,但可以肯定表达我们对于相关事件发生有多少信心。此外随着收集到更多数据,我们可以对自己的信念更加信心。作为一名科学家,我被训练着去相信数据,并且对所有事物都很谨慎。所以我认为贝叶斯推理是相当直观的。但是使用贝叶斯推断在计算和概念上通常具有挑战性。完成工作经常需要大量耗时而复杂的数学计算。即使作为数学家,我有时也觉得这些计算很乏味;特别是要快速了解待解决的问题时。幸运的是我的导师AustinRochford最近向我介绍了一个名为PyMC3的程序包,它使我们能够进行数值贝叶斯推理。本文将通过一个具体示例快速介绍PyMC3。其中0表示硬币背面向上,1表示人头向上。我们有信心说这是一个公平的硬币吗?换句话说,如果让θ为人头向上的概率,那么证据是否足以支持θ= 0.5的说法?由于除了上述实验的结果外,我们对硬币一无所知,因此很难确定地说什么。从概率学派的角度来看,θ的点估计为: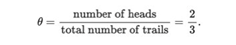
尽管这个数字是合理的,但是概率学派的方法并不能真正为它提供一定的信心置信。特别是如果我们进行更多试验,则可能会得到不同的θ点估计。这是贝叶斯方法可以提供一些改进的地方。这个想法很简单,因为我们对θ一无所知,因此可以假设θ可以是[0,1]上的任何值。在数学上,我们的先验信念是θ遵循均匀分布Uniform(0,1)分布。悄悄提醒需要复习数学的同学,Uniform(0,1)的pdf如下: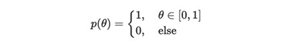
然后我们可以使用证据/观察来更新我们关于θ分布的信念。让我们正式将D称为证据(我们的例子中是抛硬币的结果。)根据贝叶斯规则,后验分布可通过以下公式计算: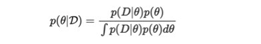
其中p(D |θ)是似然函数,p(θ)是先验分布(在这种情况下,为Uniform(0,1))从这里开始有两种方法。在这个特定示例中,我们可以手动完成所有操作。更准确地说,给定θ三个抛硬币中有2个人头向上的概率为: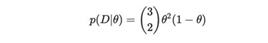
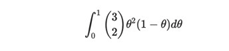
通过一些简单计算,我们可以看到上述积分等于1/4,因此: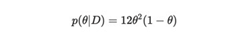
注意:通过相同的计算,我们还可以看到,如果θ的先验分布是参数为α,β的Beta分布,即p(θ)= B(α,β),并且样本大小为N,k它们是人头向上的次数,则θ的后验分布由B(α+ k,β+ N-K)给出。在我们的案例下,α=β= 1,N = 3,k = 2。在显式方法中,我们能够使用共轭先验来显式计算θ的后验分布。但有时使用共轭先验来简化计算,它们可能无法反映现实。此外找到共轭先验并不总是可行的。我们可以通过使用马尔可夫链蒙特卡洛(MCMC)方法来近似后验分布来克服此问题。这里的数学计算很多,但是出于本文目的,我们不会深入探讨。我们将侧重解释如何使用PyMC3实现此方法。import pymc3 as pmimport scipy.stats as statsimport pandas as pdimport matplotlib.pyplot as pltimport numpy as np%matplotlib inlinefrom IPython.core.pylabtools import figsize
首先我们需要初始化θ的先验分布。在PyMC3中,可以通过以下代码来实现。with pm.Model() as model:theta=pm.Uniform('theta',lower=0, upper=1)
然后我们将模型与观测数据拟合。这可以通过以下代码完成。
occurrences=np.array([1,1,0]) with model: obs=pm.Bernoulli("obs", p,observed=occurrences) step=pm.Metropolis() trace=pm.sample(18000, step=step) burned_trace=trace[1000:]
在内部计算逻辑上,PyMC3使用Metropolis-Hastings算法来近似后验分布。Trace功能确定从后验分布中抽取的样本数。最后由于该算法在开始时可能不稳定,因此在经过一定的迭代周期后,提取的样本更有用。这就是我们代码最后一行的目的。然后,我们可以绘制从后验分布获得的样本的直方图,并将其与真实密度函数进行比较。from IPython.core.pylabtools import figsizep_true=0.5figsize(12.5, 4)plt.title(r"Posterior distribution of$\theta$")plt.vlines(p_true,0, 2, linestyle='--',label=r"true $\theta$ (unknown)", color='red')plt.hist(burned_trace["theta"],bins=25, histtype='stepfilled', density=True, color='#348ABD')x=np.arange(0,1.04,0.04)plt.plot(x, 12*x*x*(1-x), color='black')plt.legend()plt.show()
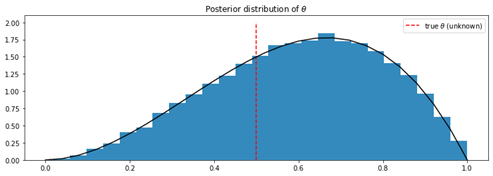
我们可以清楚地看到,数值逼近非常接近真实的后验分布。如前所述,获得的数据越多,我们对θ的真实值的信心就越大。让我们通过一个简单的模拟来检验我们的假设。我们将随机抛硬币1000次,使用PyMC3估算θ的后验分布。然后绘制从该分布获得样本的直方图。所有这些步骤都可以通过以下代码来完成:N=1000 occurences=np.random.binomial(1, p=0.5, size=N)k=occurences.sum() with pm.Model() as model1: theta=pm.Uniform('theta', lower=0,upper=1) with model1: obs=pm.Bernoulli("obs",theta, observed=occurrences) step=pm.Metropolis() trace=pm.sample(18000, step=step) burned_trace1=trace[1000:] p_true=0.5figsize(12.5, 4)plt.title(r"Posterior distribution of $\theta for sample sizeN=1000$")plt.vlines(p_true,0, 25, linestyle='--', label="true $\theta$(unknown)", color='red')plt.hist(burned_trace1["theta"], bins=25, histtype='stepfilled',density=True, color='#348ABD')plt.legend()plt.show()
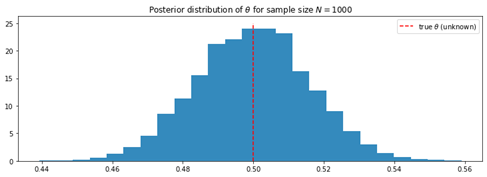
burned_trace1['theta'].mean()0.4997847718651745
PyMC3可以很好地执行统计推断任务,它使概率编程变得相当轻松。参考资料:
[1] https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
原文标题:
Introduction to PyMC3: A Python package forprobabilistic programming
原文链接:
https://towardsdatascience.com/introduction-to-pymc3-a-python-package-for-probabilistic-programming-5299278b428
编辑:黄继彦
校对:林亦霖
王雨桐,统计学在读,数据科学硕士预备,跑步不停,弹琴不止。梦想把数据可视化当作艺术,目前日常是摸着下巴看机器学习。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。








