



>>> import pandas as pd>>> import numpy as np


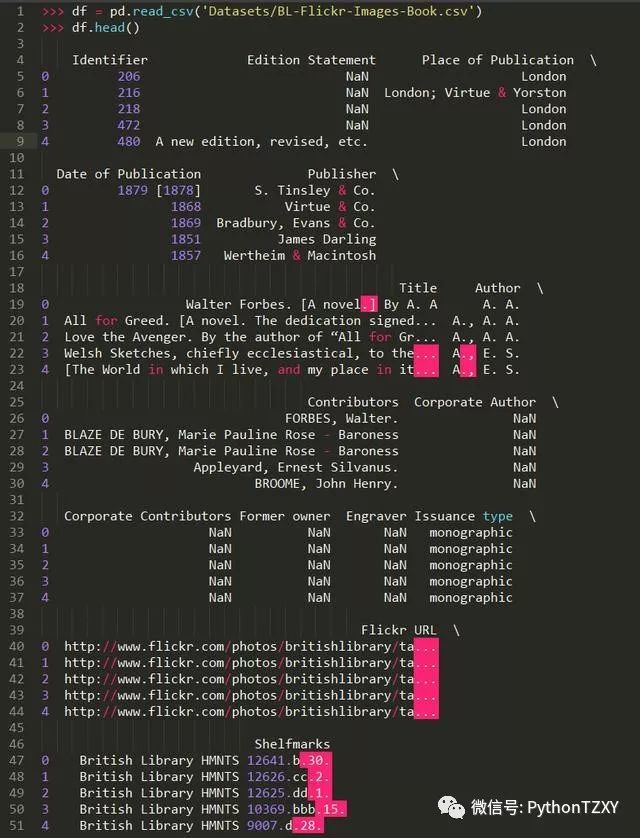



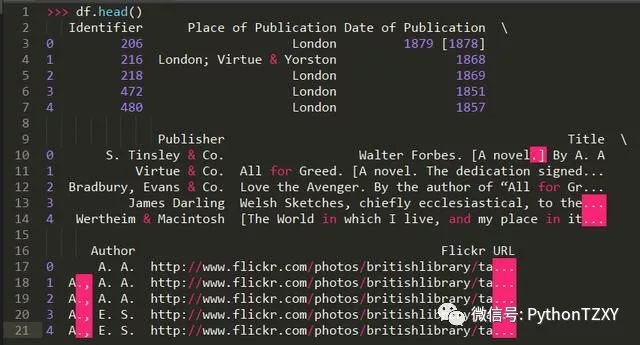

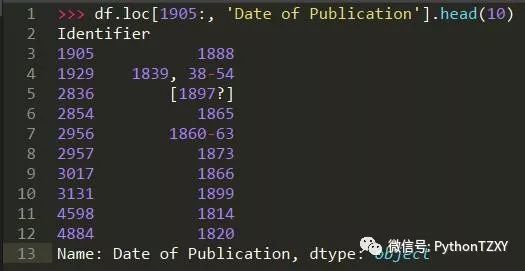
例如,在上一节使用的数据集中,可以想象到,图书管理员如果需要搜索记录,他也许输入的是书籍的唯一标识符( Identifier 列):
>>> df['Identifier'].is_uniqueTrue
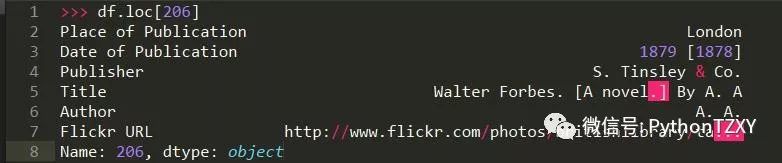
让我们用 set_index 来替换现有的索引
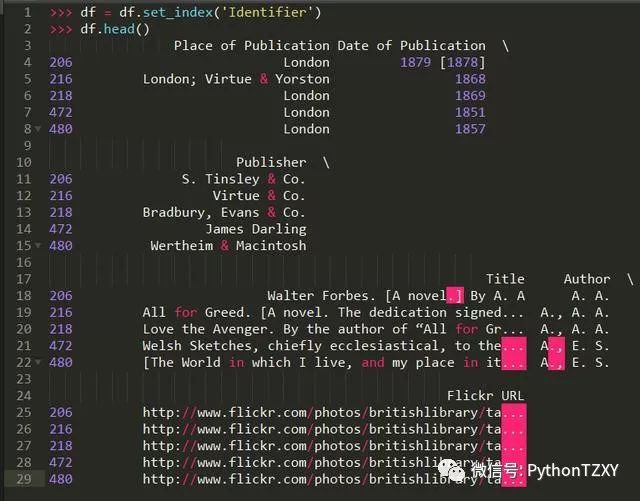



>>> df.get_dtype_counts()object 6
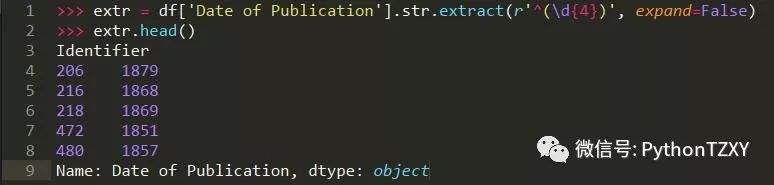
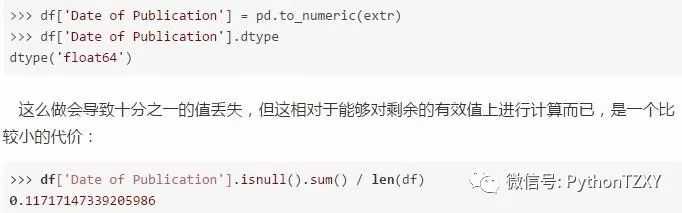
其中出版日期一列,如果将其转化为数字类型更有意义,所以我们可以进行如下计算:


很好!本节完成了!


我们将用这两个函数来清理 Place of Publication 一列,因为此列包含字符串。以下是该列的内容:

我们发现某些行中,出版地被其他不必要的信息包围着。如果观察更多值,我们会发现只有出版地包含 ‘London’ 或者 ‘Oxford’ 的行才会出现这种情况。
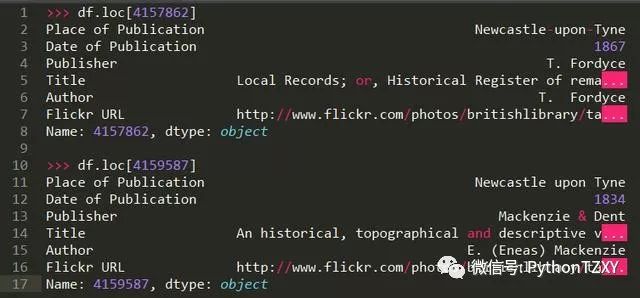
我们来看看两条特定的数据:


与 np.where 结合:




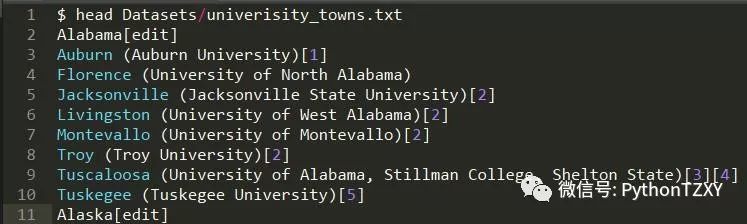




管我们可以使用 for 循环来清理上面的字符串,但是使用 Pandas 会更加方便。我们只需要州名和城镇名字,其他都可以删除。虽然这里也可以再次使用 .str() 方法,但我们也可以使用 applymap() 方法将一个 Python 可调用方法映射到 DataFrame 的每个元素上。
我们一直在使用 元素 这个术语,但实际上到底是指什么呢?看一下以下这个 DataFrame 例子:
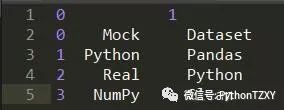






然后,将它读入 Pandas 的 DataFrame 中:







Python 数据清理:回顾以及其他资源
在本教程中,你学习了如何使用 drop()函数删除不必要的信息,以及如何给你的数据集设置索引以便更加方便的引用其他的项。










