来源:AMiner科技
作者:戚路北
【新智元导读】在Medium上,一位名为Prabhu Prakash Kagitha的博主,根据NeurIPS 2020上的论文发表了一篇题为“NeurIPS 2020 Papers: Takeaways for a Deep Learning Engineer”的文章,阅读了NeurIPS 2020中的175篇论文的摘要,汇总了与深度学习有关的见解。
1、加速基于Transformer的语言模型的逐层下降训练
与标准翻译器相比,可切换翻译器(ST)的预训练速度快2.5倍。
配备可切换门(G在fg。下面),一些层是根据伯努利分布抽样0或1随机跳过的,每个抽样的时间效率为25%。
(a)标准变压器(b)重新排序,使其PreLN (c)开关门(G)决定是否包含层。结果表明,该方法在减少了53%的训练样本的情况下,达到了与基线相同的验证误差。结合时间和样本效率,预训练的速度比下游任务快2.5倍,有时甚至更好。小贴士:当你想要预训练或finetune一个转换器时,试着使用可切换的转换器,以获得更快的训练和低推理时间。
2、用于神经网络抗噪声标签的Robust训练的核心集
前面已经证明,神经网络权值(W)和干净数据(X)的雅可比矩阵经过一定的训练后会近似为一个低秩矩阵,有一些较大的奇异值和大量非常小的奇异值。同样,归纳(即从干净的数据中)的学习是在一个叫做信息空间(I)的低维空间中,而不归纳(即从嘈杂的标签中,主要是记忆)的学习是在一个叫做讨厌的空间(N) Nuisance space的高维空间中。目前的工作引入了一种技术,该技术可以创建一组大部分干净的数据(Coresets)来训练模型,并显示在有噪声的数据集上的性能显著提高,即与最先进的技术相比,在带有50%噪声标签的迷你Webvision上性能提高了7%。在这篇论文中介绍的方法,CRUST,表现明显优于最先进的。小贴士:当你怀疑你收集的数据集有噪声/错误标记的数据点时,使用CRUST只在干净的数据上训练模型,提高性能和稳定性。
在训练过程相同的情况下,存在一个表现出与原始完整网络相当性能的子网络。这些子网被称为彩票,并由掩码定义,掩码告诉哪些权重在原始网络中被置零。目前的工作采用迭代幅度修剪(IMP),对一个子网进行一定时间的训练,并对k%较小幅度的权重进行修剪。这个过程重复多次,直到稀疏度达到目标稀疏度。重要的是,在每次迭代训练之后,模型将以初始参数重新开始,而不是更新权重直到那时,这被称为倒带。这里,预先训练的BERT的权值是我们开始IMP时的初始化。彩票是预先训练的BERT的子网络也包含相同的预先训练的权值,其中一些被置零。这项工作表明彩票假设对预先训练的BERT模型同样适用。并发现在一系列下游任务中,子网的稀疏度为40%到90%。最后一行对应于本文所介绍的方法。即使它是40%-90%的稀疏,性能可与完整的Bert base相媲美。此外,作者还发现了一个预训练的具有70%稀疏性的BERT票,它可以转移到许多下游任务中,并且执行得至少与为特定下游任务发现的70%稀疏票一样好或更好。
小贴士:研究NLP的深度学习工程师必须经常对BERT进行下游任务的预先训练。不是从全尺寸的BERT开始,而是从在MLM下游任务(倒数第一行)上找到的70%稀疏彩票开始fine-tuning,以更快地训练并减少推理时间和内存带宽,而不损失性能。MPNet是隐藏语言建模(MLM)和自回归排列语言建模(PLM)的混合,采用了各自的优点,并避免了它们的局限性。屏蔽语言建模,就像BERT风格的模型一样,屏蔽掉约15%的数据,并试图预测那些屏蔽标记。由于掩蔽令牌之间的依赖关系没有建模,导致了预训练-微调差异,这被称为输出依赖。另一方面,自回归建模交换语言,如XLNet,没有完整的信息输入句子,即当预测说第五元素8-element序列模型并不知道有8序列中的元素,因此导致pre train-finetune差异(模型看到整个输入句子/段下游任务),称为输入一致性。MPNet将两者结合起来。通过在句子末尾添加额外的掩码来修改类似xlnet的体系结构,以便在任何位置的预测将涉及N个标记,其中N是序列的长度,其中一些是掩码。说明了MPNet是如何将传销和PLM结合在一起的。他们使用XLNet中引入的双流自我注意来支持自回归类型预测,在这一步,任何位置的内容都应该被掩盖以进行预测,但在后面的步骤中,预测应该是可见的。与之前最先进的预训练方法(如BERT、XLNet、RoBERTa)相比,MPNet比MLM和PLM表现更出色,在GLUE、SQUAD等任务上的表现也更好。小贴士:如果你曾经想要在你的领域特定数据上预先训练一个语言模型,或者使用更多的数据,可以使用MPNet,它已经被证明具有最好的MLP和PLM世界。在大规模数据集中,错误标记的数据是常见的,因为它们是“众包”或从互联网上抓取的,容易产生噪声。这项工作形成了一个简单直观的想法。假设有100张狗的图片,但其中20张被标记为“鸟”。同样的,100只鸟的图片,但其中20只被贴上了“狗”的标签。经过一些训练后,对于一张错误标记为“鸟”的狗的图像,模型给出了相当大的概率标记为“狗”,因为从80张正确标记的图像中归纳出来。这个模型也给出了“鸟”这个标签的相当大的可能性,因为它记住了那20个错误标记的图像。现在,“狗”的概率和“鸟”的概率之间的差异被称为“边缘区域”(AUM)。本研究建议,如果AUM低于某个预先定义的阈值,我们应该将其视为错误标记的数据样本,并将其从训练中删除。如果我们不能确定一个阈值,我们可以故意填充错误标记的数据,看看这些例子的AUM是什么,这就是我们的临界值。在WebVision50分类任务中,该方法删除了17%的训练数据,测试错误减少了1.6%(绝对)。在CIFAR100上删除13%的数据会导致误差下降1.2%。小贴士:在创建数据集时,噪声/错误标记的数据样本大多是不可避免的。然后,使用AUM方法找到错误标记的数据样本,并将其从最终的训练数据集中删除。
当现有的标签是不平衡的类(有些类比其他类有更多的带标签的例子),并且我们有很多未带标签的数据时,我们还需要标签吗?积极的(positive)。是的,我们需要标签。对未标记的数据进行自我训练,你将会获得成功。(自我训练是一个过程,中间模型是在人类标记的数据上训练的,用来创建“标签”(或伪标签),然后最终模型是在人类标记和中间模型标记的数据上训练的)。
消极的(negative)。我们可以把标签去掉。可以对所有可用数据使用自我监督的预训练,以学习有意义的表示,然后学习实际的分类任务。结果表明,该方法提高了性能小贴士:如果你有类别不平衡的标签和更多的未标记数据,那么就进行自我训练或自我监督的预训练吧。(尽管CIFAR-10-LT显示了自我训练胜过自我监督学习)。
标准翻译器的自注意是二次复杂度(存储和计算)wrt序列长度。因此,训练较长的序列是不可行的。在Big Bird中,它使用稀疏注意,其中一个特定位置只关注几个随机选择的token和一些邻近的token。但这并不是它工作的原因。Big Bird有多个用于处理整个序列的CLS标记。任何位置的标记都会处理这些CLS标记给它们相关的上下文、依赖关系,谁知道自我注意层还能学到什么呢。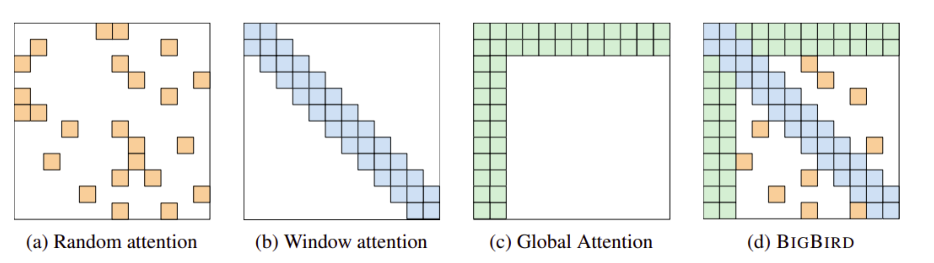
 不同类型的注意在稀疏注意(a)随机注意(b)窗口邻域注意(c)添加CLS令牌后的全局注意。(图片摘自本论文的pdf版本。)“Big Bird稀疏的注意力可以处理长达8倍于之前使用类似硬件的序列。由于能够处理更长的上下文,Big Bird大大提高了各种NLP任务的性能,如回答问题、总结和基因组数据的新应用。”小贴士:如果你要处理较长的句子或序列,比如摘要或基因组数据的应用,请使用Big Bird进行可行的训练和合理的推理时间。即使是更小的句子,也要用Big Bird。
不同类型的注意在稀疏注意(a)随机注意(b)窗口邻域注意(c)添加CLS令牌后的全局注意。(图片摘自本论文的pdf版本。)“Big Bird稀疏的注意力可以处理长达8倍于之前使用类似硬件的序列。由于能够处理更长的上下文,Big Bird大大提高了各种NLP任务的性能,如回答问题、总结和基因组数据的新应用。”小贴士:如果你要处理较长的句子或序列,比如摘要或基因组数据的应用,请使用Big Bird进行可行的训练和合理的推理时间。即使是更小的句子,也要用Big Bird。
为特定任务选择一系列转换及其大小进行数据扩展是特定领域的,而且很耗时。自动增强是一种学习最佳转换序列的技术,其回报是否定验证损失。通常使用RL来学习该策略。学习这个最优策略的一次迭代需要完全训练一个模型,因此是一个非常昂贵的过程。因此,目前的工作试图使这个过程更有效。这是基于之前所展示的洞察力,当训练有一系列的转换时,转换的效果只在训练的后期阶段突出。在当前的工作中,对于评估特定策略(转换序列)的每次迭代,大部分的培训都使用共享策略完成,只有培训的最后一部分是使用要评估的当前策略完成的。这被称为增广加权共享。当使用共享策略的训练在所有迭代中只进行一次时,该方法可以有效地学习最优策略。在CIFAR-10上,该方法的错误率最高为1.24%,是目前在没有额外训练数据的情况下表现最好的单一模型。在ImageNet上,该方法的错误率最高,为ResNet-50的20.36%,这导致了比基线增强的绝对错误率减少3.34%。”小贴士:当你有资源使用最优的数据增强序列来提高模型的性能时,使用这种方法来训练RL代理,它学习最优策略,这更有效,也使自动增强在大型数据集上可行。
和上面的Big Bird一样,快速翻译近似于标准的自我关注,使其从二次依赖性变为线性。为了做到这一点,不是对所有的注意力进行计算(O(sequence_length*sequence_length)),而是对查询进行聚类,并且只对centroids计算注意力值。
一个特定集群中的所有查询都将获得相同的关注值。这使得整体计算的自我注意线性wrt序列长度。O (num_clusters * sequence_length)。
“这篇论文表明,Fast transformer可以用最少的集群来近似任意复杂的注意力分布,方法是在GLUE和SQUAD基准上近似预训练的BERT模型,只有25个集群,并且没有性能损失。”小贴士:这并不像我们在上面看到的Big Bird那样优雅,但一个人必须尝试所有的选择,把自我关注的二次复杂性变成线性的。
在缩放转换器时,经验表明增加宽度(内部表示的维度)与增加深度(自我注意层数)同样有效。相反,更具体地说,这项工作表明,我们可以将转换器缩放到“深度阈值”,即以宽度的3为底的对数。如果深度低于此深度阈值,则增加深度比增加宽度更有效。这被称为深度效率。如果深度高于这个深度阈值增加深度会比增加宽度造成伤害。这被称为深度无效率。小贴士:当你想为下一个大型语言模型扩展翻译架构时,请记住,如果宽度不够大,增加深度也无济于事。深度应该总是小于“深度阈值”,即以3为底的宽度的对数。所以,在增加深度之前先增加宽度,以使你的转换器达到近乎疯狂的深度。综上,正如小贴士所呈现的那样,通过阅读NeurIPS2020论文,我们获得了这些模型训练技巧,在深度学习的路上越走越远。







