
我在Twitter做Ads Measurement广告测量相关的工作。这份工作,是用Python爬虫找到的。
故事是这样开始的
那是个Memorial Day假日的晚上,朋友们都出去浪了,而我正在肾上腺素爆发地趴在电脑前做一件我觉得酷毙了的事。

我12月刚毕业,需要一份工作。但我每天要花大量的时间精力在招聘搜索上,所以我决定加速我的工作搜索流程,毕竟在找工作这件事上,谁快谁就赢了。
从Craigslist开始
我想做一个程序,帮我收集并回复在Craigslist上招软件工程师的人。很多人也许只知道Craigslist能找房子和服务,但他们也许不清楚Craigslist上也能找工作吧!
先做一个最简单的原型
首先我要知道如何方便地获得Craigslist的数据。
我查了下Craigslist想看看他们是不是已经有了公开的REST API,但令我失望的是他们没有。
但是,我发现了另一个东西。
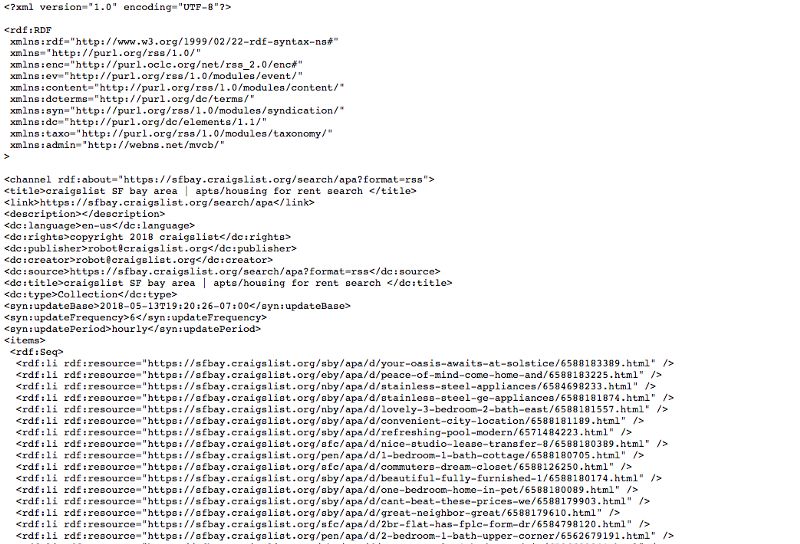
Craigslist有一个RSS feed是公开给个人使用的。一个RSS feed就是一个电脑可读的、对网站发出的所有更新的总结。在我的这个例子里,只要有人在Craigslist上挂出招聘帖,我就能通过RSS feed看到。这就是我想要的!
RSS feed就是长这样的:
接下来,我需要想个办法来读取这些RSS feeds。我可不想人工去一条一条读这么多RSS feeds,不然这和我直接浏览Craigslist有什么区别呢?
就在这时,我意识到了Google的强大。有一个笑话说的是,软件工程师的大多数时间是花在Google上找答案的......说实话我觉得这太真实了
在谷歌了一阵后,我在StackOverflow上发现了一个超有用的帖子,关于怎么来搜索Craigslist RRS feed。它本质就是Craigslist免费提供的一个筛选功能。我只要把我感兴趣的关键词加进特定的参数里就行了。
我当时主要在找西雅图的软件相关的工作,所以只要是关键词里包含“software”的西雅图招聘帖我都能爬到。下面就是我爬取的帖子的链接:
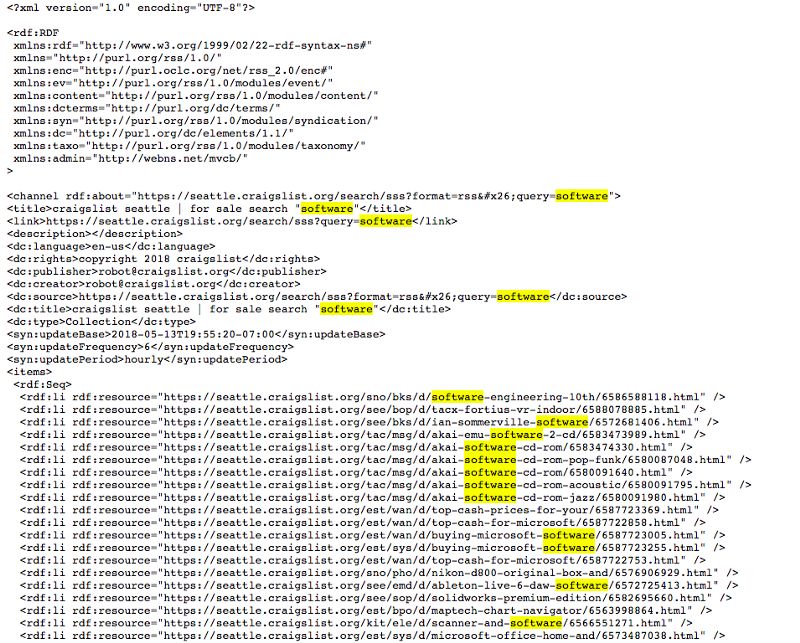
我喝过的最美味的汤(Beautiful Soup)
不过到目前为止,我的方法还是漏洞百出。
首先,帖子数量是有限的。我的数据并不包含所有西雅图正在招聘的工作。返回来的结果只是所有招聘帖中的一小部分。我需要知道所有在招聘的帖子。
第二,我意识到RRS feed爬取的结果只有原帖标题,不包括任何联系人信息,除非我手动地去点开帖子。
我是一个有很多技能和兴趣的人,但做重复的手动工作并不是我的爱好之一。我完全可以雇人来帮我做,但我当时还是刚刚毕业的穷学生,我不能在这个side project上乱花钱。
这看起来是个死结。不过这并不是结局。
持续迭代
怎么打开这个死结呢?
目前我们已知,Craigslist的RSS feed是可以用关键词来筛选帖子的,且RSS feed每一个帖子都有超链接可以连回原帖。
那,如果我可以找到原帖,也许我可以从帖子上爬取我要的电子邮件?
这意味着我需要找到一个办法来从原始帖子中获取电子邮箱。
又一次,我打开了我最爱的Google,搜索“解析一个网页的办法”。
我找到了一个很酷的Python工具包叫做Beautiful Soup。它妙极了,你可以用来解析网页并且帮你理解一个网页有着怎样的结构。
我的需求很简单:我需要一个方便使用的工具,并能让我们从网页上收集数据。Beautiful Soup可以完美地解决这两个需求。与其花更多的时间选出最好的工具,我决定就选择这个“美味的汤”继续前进了!
用了这个“美味的汤”,我的工作流程就确定了:

我现在准备好解决下一个任务了:从原帖中爬取email地址。
开源技术有一个很酷的地方就是,它们是免费的而且用起来很方便!就像在炎热的夏天有人送了你一根免费的冰淇淋。
Beautiful Soup让你可以在一个网页上搜索具体的HTML标签或者记号。Craigslist的网页结构让我很容易就能找到邮件地址,而邮件回复链接前后就是我可以用来提取邮箱信息的HTML标签。
从这一步起,一切就简单了。我靠着Beautiful Soup提供的内置功能,只要稍加简单的操作,我就能方便地从Craigslist的帖子里截取邮件地址。
把所有步骤拼在一起
我花了一个小时左右的时间,做出了我的第一个最简可行产品(MVP)——一个网页爬虫,让我可以收集并回复那些在西雅图100迈半径内寻找软件工程师的人。
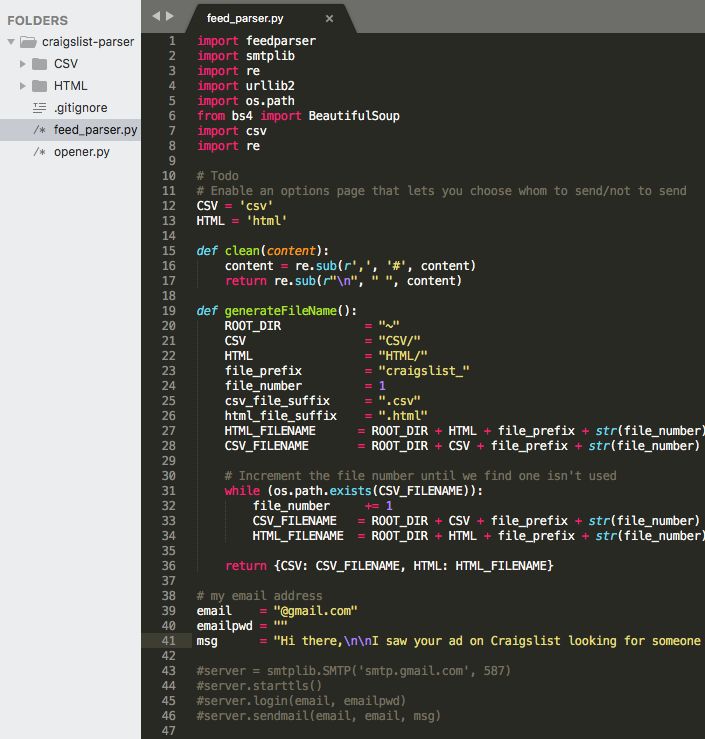
我在原来的代码上又加了一些附加设备,来让整个流程更方便高效。比如,我把结果保存斤CSV以及HTML网页,以便我更快地解析它们。
当然也有很多不完善的地方,比如:
不过最后一条不是太重要,因为如果一个帖子已经存在一段时间,那很有可能这个职位已经找到人了。
整个经历就像一个拼图游戏。我知道我的终极目标,我的挑战是把所有拼图拼到一起来达到这个终极目标。每一片拼图都带我走上了不同的旅程。过程很难,但让人很享受离答案越来越近的每一步。
Takeaways
这次的经历打开了我的眼界,我对Craigslist是如何工作的更加了解了,而且我用了不同的工具合力解决了一个问题,另外,我还有了一个很酷的故事可以和别人分享。
其实这很像当今科技是如何运作的。你找到一个需要解决的大问题,但你看不到任何马上可用的、明显的解决方案。于是你把这个大问题分解成一个一个小问题,然后一一攻破。
现在回想起来,如果笼统地描述我遇到的问题,那就是:我怎样可以用这个很酷互联网目录来快速触达有着某个特定兴趣的人群?
而这个问题,不仅仅能概括“自动化找工作”这个流程,还能概括很多其他商业问题。比如,怎么在Twitter上找到并触达某个特征的人群?而这,就是我后来找到的工作——在Twitter的Ads Measurement团队。
可以提高的地方
有很多领域是我可以提高的:
我选了一个我并不是非常熟悉的语言来开始,所以一开始有一个learning curve。但不是太糟糕,因为Python是很容易学会的语言。我非常推荐编程初学者来把Python当作第一门编程语言学习。
过度依赖开源科技。开源软件也有它自己的问题。比如,有很多我用的工具包已经很久没有更新过了,所以我刚开始遇到了一些问题。比如,我无法导入一个工具包,或者工具包因为一些很小的原因报错了。
自己搞定一个项目是很有趣的,但也可能造成很多压力。这个项目虽然比较简单的,但也花了我好几个周末来改善。之后我就越来越没有动力去改善我的项目了,在我找到工作后,我彻底放下了这个项目。
想要和作者一样,用Python爬虫敲开dream company大门吗?如果你想通过Python来学习数据分析,掌握Python最实用、最有工作场景的功能,提升自己在面试和工作中的表现,那就报名《Python数据分析》吧!
第一课 Python数据分析的一般概念、操作界面、常用数据包
这节课我们会讲Python的数据类型、操作界面Jupyter Notebook、常用的数据分析的应用包,比如:NumPy
Pandas
Matplotlib
Seaborn
Scikit-learn
第二课 如何用Python进行Data Review & QA对于一个数据分析师来说,工作中大量的时间都花在了Data Review和Quality Assurance/Control(数据检查)上,也就是常说的QA。QA相当重要,但是又异常繁琐。第二课,我们会学习如何用Python高效快速QA
数据处理是数据分析中最重要的环节,它是从数据中整理、得出有意义的洞察的前提。这节课中我们会学习用Python进行:Data Manipulation
Conditional Filtering
Indexing
Aggregration
Grouping
工作中,经常需要我们对数据进行二维表处理,Pivot就是一个常见的转化横表、竖表的方法。这节课我们会学习Stack的概念,学会用Python进行快速的数据结构转化。Stack & Unstack
Pivot Table
Format table
这节课我们讲学习Loop的概念,以及如何利用loop用Python进行纵向、横向查找。
第六课 用matplotlip以及seaborn进行数据可视化这节课我们将学习如何用Python的数据可视化程序包制作出精美绝伦的数据图,亮瞎你挑剔的老板!
尽管Python自带了各种很有价值的程序包,但我们也难免会遇到需要自己设定函数解决问题的时候。这节课我们会学习如何自己创造解决特定问题的程序包,也就是自定义函数。
最后一节课,我们将全面应用前七节课的所有知识点,面对实际工作场景中几乎每天都遇到的数据案例进行实际操作。由于Python是一门操作性的数据工具课,因此我们特别邀请了两位老师来授课,分别负责概念讲解和练习。
主讲老师:Effie老师,在Code&Theory担任高级数据编程分析师,有着营销和商业背景的她,深知日常工作中数据分析师们面临的实际问题,她摒弃市面上其他Python课程的偏数理、偏理论的作风,从实用主义出发,用案例教学来让大家真正学会用Python解决日常天天遇到的数据分析问题!
习题老师:Henry老师,在Wayfair担任机器学习工程师。具有8年数据科学背景,熟悉各类数据分析工具和算法。Henry老师精心设计了各类实操练习题,帮你巩固所学知识!
若扫码过程遇到问题,可直接点击本文底部“阅读原文”,进入课程页面









