【导语】:EasyOCR 是一个用 Python 编写的 OCR 库,用于识别图像中的文字并输出为文本,支持 80 多种语言。
简介
EasyOCR 是 python 中一个不错的 OCR 库,在GitHub已有 10.3K star。目前支持80多种语言,包括中文、日文、韩文和泰文等。

下载安装
- 项目地址:https://github.com/JaidedAI/EasyOCR
- 教程地址:https://www.jaided.ai/easyocr/tutorial
- API文档:https://www.jaided.ai/easyocr/documentation
EasyOCR安装方法很简单,直接使用pip安装,有以下两种安装命令:
pip install easyocr
pip install git+git://github.com/jaidedai/easyocr.git
需要注意的是,如果在Windows下安装,需要先安装 torch 和 torchvision(安装方法详见官方网址 https://pytorch.org)。在 pytorch 网站上,一定要选择正确的CUDA版本。如果只想在CPU模式下运行,请选择 CUDA = None。
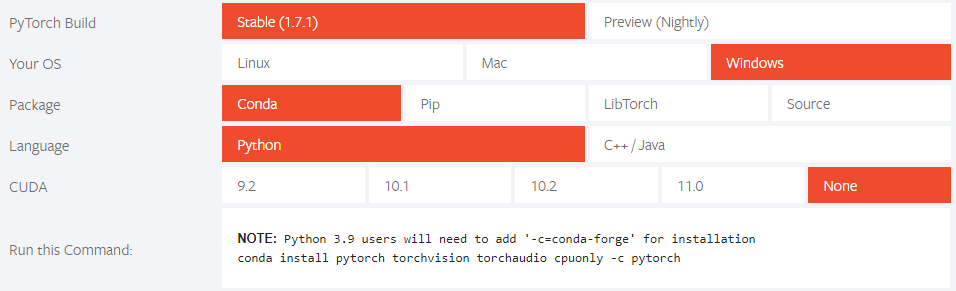
另外,开发者还提供了docker文件,详见:https://github.com/JaidedAI/EasyOCR/blob/master/Dockerfile
简单使用
安装好环境后,使用以下命令进行体验图片识别:
import easyocr
# 创建reader对象,指定语言为简写中文
# 该命令只需要运行一次就可以将model加载到内存中
reader = easyocr.Reader(['ch_sim','en'])
# 读取图像
result = reader.readtext('chinese.jpg')
其中 chinese.jpg 为

输出为列表格式,每个项目分别代表边界框、文本和自信级别:
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], '315', 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], '309', 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], 'Yuyuan Rd.', 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], 'W', 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], 'E', 0.8405593633651733)]
可以通过使用detail = 0简化输出:
reader.readtext('chinese.jpg', detail = 0)
输出结果如下:
['愚园路'
, '西', '东', '315', '309', 'Yuyuan Rd.', 'W', 'E']
如果没有GPU或者GPU内存不足,可以通过添加GPU = False在CPU模式下运行:
reader = easyocr.Reader(['ch_sim','en'], gpu = False)
另外,也可以通过命令行使用如下:
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
快速体验
不想在本地安装环境的朋友可以在开发者提供的colab地址上体验:https://colab.fan/easyocr
小秋在colab上尝试了几张图,效果如下:

识别结果:
[([[142, 232], [500, 232], [500, 361], [142, 361]],
'เส้นทางลัด',
0.10795291513204575),
([[177, 483], [385, 483], [385, 573], [177, 573]],
'เพชรบุรี',
0.5405621528625488)]

识别结果:
[([[71, 49], [489, 49], [489, 159], [71, 159]], 'ポ, 0.6339455246925354),
([[95, 149], [461, 149], [461, 235], [95, 235]],
'NOLITTER',
0.32494133710861206),
([[80, 232], [475, 232], [475, 288], [80, 288]],
'清潔できれいな港区を',
0.9784266948699951),
([[109, 289], [437, 289], [437, 333], [109, 333]],
'港 区 MINATO CITY',
0.18789240717887878)]
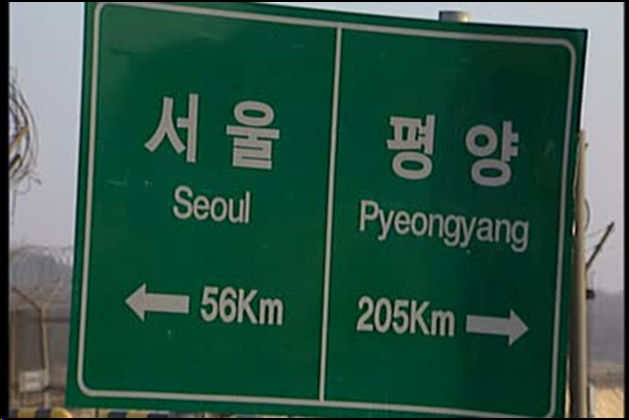
识别结果
[([[129, 79], [292, 79], [292, 183], [129, 183]], '서울', 0.9718754291534424),
([[368, 101], [531, 101], [531, 201], [368, 201]], '평양', 0.9701955914497375),
([[159, 176], [258, 176], [258, 232], [159, 232]],
'Seoul',
0.8239477872848511),
([[342, 189], [539, 189], [539, 262], [342, 262]],
'Pyeongyang',
0.3527982532978058),
([[186, 276], [289, 276], [289, 333], [186, 333]],
'56Km',
0.6299729943275452),
([[344, 288], [461, 288], [461, 344], [344, 344]],
'205Km',
0.38107678294181824)]
结语
EasyOCR 就简单介绍到这里了,感兴趣的朋友可以到项目主页了解更多详情。








