前面(机器学习第17篇 - 特征变量筛选(1))评估显示Boruta在生物数据中具有较高的特征变量选择准确度,下面就具体看下如何应用Boruta进行特征变量选择。
Boruta算法概述
Boruta得名于斯拉夫神话中的树神,可以识别所有对分类或回归有显著贡献的变量。其核心思想是统计比较数据中真实存在的特征变量与随机加入的变量(也称为影子变量)的重要性。
初次建模时,把原始变量拷贝一份作为影子变量。
原始变量的值随机化后作为对应影子变量的值 (随机化就是打乱原始变量值的顺序)。
使用随机森林建模并计算每个变量的重要性得分。
对于每一个真实特征变量,统计检验其与所有影子变量的重要性最大值的差别。
重要性显著高于影子变量的真实特征变量定义为重要。
重要性显著低于影子变量的真实特征变量定义为不重要。
所有不重要的变量和影子变量移除。
基于新变量构成的数据集再次重复刚才的建模和选择过程,直到所有变量都被分类为重要或不重要,或达到预先设置的迭代次数。

其优点是:
同时适用于分类问题和回归问题
考虑多个变量的关系信息
改善了常用于变量选择的随机森林变量重要性计算方式
会输出所有与模型性能相关的变量而不是只返回一个最小变量集合
可以处理变量的互作
可以规避随机森林自身计算变量重要性的随机波动性问题和不能计算显著性的问题
Boruta算法实战
# install.packages("Boruta")library(Boruta)
set.seed(1)
boruta 0.01, mcAdj=T,
maxRuns=300)
boruta
## Boruta performed 299 iterations in 1.452285 mins.
## 54 attributes confirmed important: AC002073_cds1_at, D13633_at,
## D31887_at, D55716_at, D78134_at and 49 more;
## 6980 attributes confirmed unimportant: A28102, AB000114_at,
## AB000115_at, AB000220_at, AB000381_s_at and 6975 more;
## 36 tentative attributes left: D31886_at, D43950_at, D79997_at,
## HG2279.HT2375_at, HG417.HT417_s_at and 31 more;
速度还是可以的(尤其是跟后面要介绍的 RFE 的速度比起来)
boruta$timeTaken
## Time difference of 1.452285 mins
查看下变量重要性鉴定结果(实际上面的输出中也已经有体现了),54个重要的变量,36个可能重要的变量 (tentative variable, 重要性得分与最好的影子变量得分无统计差异),6,980个不重要的变量。
table(boruta$finalDecision)
##
## Tentative Confirmed Rejected
## 36 54 6980
boruta$finalDecision[boruta$finalDecision=="Confirmed"]
## AC002073_cds1_at D13633_at D31887_at D55716_at
## Confirmed Confirmed Confirmed Confirmed
## D78134_at D82348_at D87119_at HG2874.HT3018_at
## Confirmed Confirmed Confirmed Confirmed
## HG4074.HT4344_at HG4258.HT4528_at J02645_at J03909_at
## Confirmed Confirmed Confirmed Confirmed
## K02268_at L17131_rna1_at L27071_at L42324_at
## Confirmed Confirmed Confirmed Confirmed
## M10901_at M57710_at M60830_at M63138_at
## Confirmed Confirmed Confirmed Confirmed
## M63835_at U14518_at U23143_at U28386_at
## Confirmed Confirmed Confirmed Confirmed
## U37352_at U38896_at U56102_at U59309_at
## Confirmed Confirmed Confirmed Confirmed
## U63743_at U68030_at X01060_at X02152_at
## Confirmed Confirmed Confirmed Confirmed
## X14850_at X16983_at X17620_at X56494_at
## Confirmed Confirmed Confirmed Confirmed
## X62078_at X67155_at X67951_at X69433_at
## Confirmed Confirmed Confirmed Confirmed
## Z11793_at Z21966_at Z35227_at Z96810_at
## Confirmed Confirmed Confirmed Confirmed
## U16307_at HG3928.HT4198_at V00594_s_at X03689_s_at
## Confirmed Confirmed Confirmed Confirmed
## M14328_s_at X91911_s_at X12530_s_at X81836_s_at
## Confirmed Confirmed Confirmed Confirmed
## HG1980.HT2023_at M94880_f_at
## Confirmed Confirmed
## Levels: Tentative Confirmed Rejected
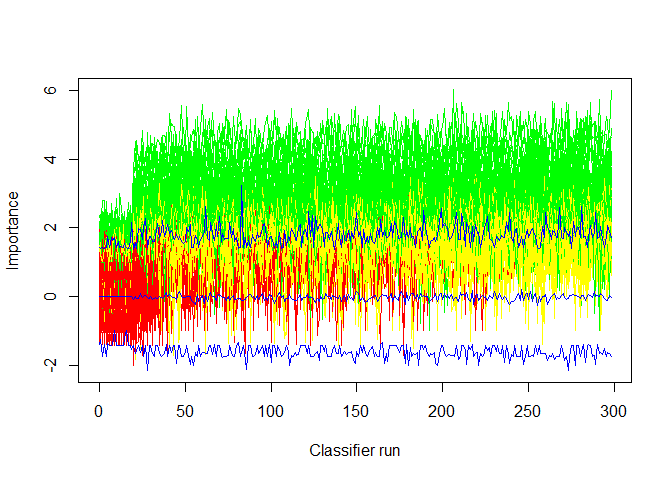
绘制Boruta算法运行过程中各个变量的重要性得分的变化 (绿色是重要的变量,红色是不重要的变量,蓝色是影子变量,黄色是Tentative变量)。
这个图也可以用来查看是否有必要增加迭代的次数以便再次确认Tentative变量中是否有一部分为有意义的特征变量。从下图来看,黄色变量部分随着迭代还是有部分可能高于最高值,可以继续尝试增加迭代次数。
Boruta::plotImpHistory(boruta)
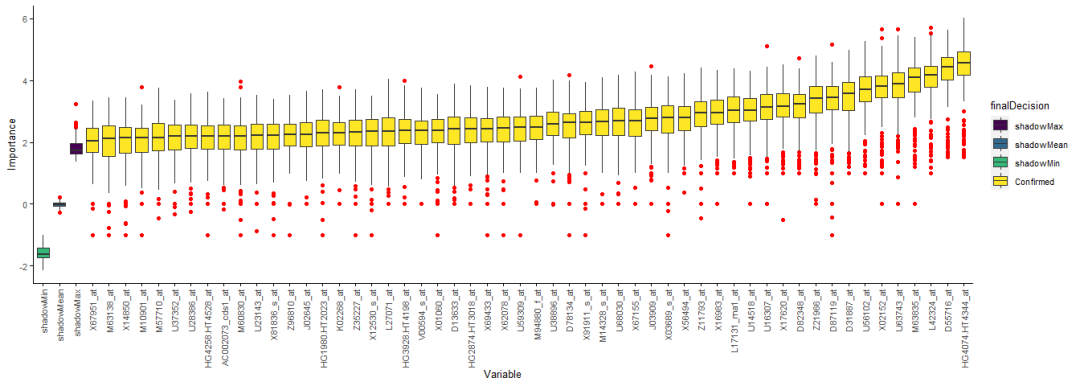
绘制鉴定出的变量的重要性。变量少了可以用默认绘图,变量多时绘制的图看不清,需要自己整理数据绘图。
# ?plot.Boruta# plot(boruta)
定义一个函数提取每个变量对应的重要性值。
library(dplyr)
boruta.imp function(x){
imp 1]
colnames(imp) "Variable","Importance")
imp
variableGrp finalDecision=x$finalDecision)
showGrp "shadowMax", "shadowMean", "shadowMin"),
finalDecision=c("shadowMax", "shadowMean", "shadowMin"))
variableGrp
boruta.variable.imp
sortedVariable % group_by(Variable) %>%
summarise(median=median(Importance)) %>% arrange(median)
sortedVariable
boruta.variable.imp$Variable
invisible(boruta.variable.imp)
}
boruta.variable.imp
head(boruta.variable.imp)
## Variable Importance finalDecision
## 1 A28102 0 Rejected
## 2 A28102 0 Rejected
## 3 A28102 0 Rejected
## 4 A28102 0 Rejected
## 5 A28102 0 Rejected
## 6 A28102 0 Rejected
只绘制Confirmed变量。
library(YSX)
sp_boxplot(boruta.variable.imp, melted=T, xvariable = "Variable", yvariable = "Importance",
legend_variable = "finalDecision", legend_variable_order = c("shadowMax", "shadowMean", "shadowMin", "Confirmed"),
xtics_angle = 90)
提取重要的变量 (可能重要的变量可提取可不提取)
boruta.finalVars "Boruta")
也可以使用TentativeRoughFix函数进一步计算。这一步的计算比较粗糙,根据重要性的值高低判断Tentative类型的变量是否要为Confirmed或Rejected。
Tentative.boruta
机器学习系列教程
从随机森林开始,一步步理解决策树、随机森林、ROC/AUC、数据集、交叉验证的概念和实践。
文字能说清的用文字、图片能展示的用、描述不清的用公式、公式还不清楚的写个简单代码,一步步理清各个环节和概念。
再到成熟代码应用、模型调参、模型比较、模型评估,学习整个机器学习需要用到的知识和技能。
机器学习算法 - 随机森林之决策树初探(1)
机器学习算法-随机森林之决策树R 代码从头暴力实现(2)
机器学习算法-随机森林之决策树R 代码从头暴力实现(3)
机器学习算法-随机森林之理论概述
随机森林拖了这么久,终于到实战了。先分享很多套用于机器学习的多种癌症表达数据集 https://file.biolab.si/biolab/supp/bi-cancer/projections/。
机器学习算法-随机森林初探(1)
机器学习 模型评估指标 - ROC曲线和AUC值
机器学习 - 训练集、验证集、测试集
机器学习 - 随机森林手动10 折交叉验证
一个函数统一238个机器学习R包,这也太赞了吧
基于Caret和RandomForest包进行随机森林分析的一般步骤 (1)
Caret模型训练和调参更多参数解读(2)
机器学习相关书籍分享
基于Caret进行随机森林随机调参的4种方式
送你一个在线机器学习网站,真香!
UCI机器学习数据集
机器学习第17篇 - 特征变量筛选(1)






