点击上方 IT牧场 ,选择 置顶或者星标技术干货每日送达!

Nginx全程是什么?Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。
daemon守护线程
nginx在启动后,在unix系统中会以daemon的方式在后台运行,后台进程包含一个master进程和多个worker进程。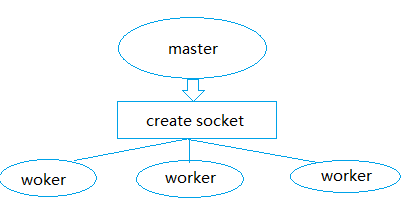
当然nginx也是支持多线程的方式的,只是我们主流的方式还是多进程的方式,也是nginx的默认方式。 master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。 worker进程则是处理基本的网络事件。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。 worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致。更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,具有cpu绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效。 惊群现象
每个worker进程都是从master进程fork过来。在master进程里面,先建立好需要listen的socket之后,然后再fork出多个worker进程,这样每个worker进程都可以去accept这个socket(当然不是同一个socket,只是每个进程的这个socket会监控在同一个ip地址与端口,这个在网络协议里面是允许的)。一般来说,当一个连接进来后,所有在accept在这个socket上面的进程,都会收到通知,而只有一个进程可以accept这个连接,其它的则accept失败。相对于线程,采用进程的优点
进程之间不共享资源,不需要加锁,所以省掉了锁带来的开销。
采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快重新启动新的worker进程。
编程上更加容易。
多线程的问题
而多线程在多并发情况下,线程的内存占用大,线程上下文切换造成CPU大量的开销。想想apache的常用工作方式(apache也有异步非阻塞版本,但因其与自带某些模块冲突,所以不常用),每个请求会独占一个工作线程,当并发数上到几千时,就同时有几千的线程在处理请求了。这对操作系统来说,是个不小的挑战,线程带来的内存占用非常大,线程的上下文切换带来的cpu开销很大,自然性能就上不去了,而这些开销完全是没有意义的。
异步非阻塞
异步的概念和同步相对的,也就是不是事件之间不是同时发生的。 非阻塞的概念是和阻塞对应的,阻塞是事件按顺序执行,每一事件都要等待上一事件的完成,而非阻塞是如果事件没有准备好,这个事件可以直接返回,过一段时间再进行处理询问,这期间可以做其他事情。但是,多次询问也会带来额外的开销。 淘宝tengine团队说测试结果是“24G内存机器上,处理并发请求可达200万”。
connection
在src/core文件夹下包含有connection的源文件,Ngx_connection.h/Ngx_connection.c中可以找到SOCK_STREAM,也就是说Nginx是基于TCP连接的。连接过程
对于应用程序,首先第一步肯定是加载并解析配置文件,Nginx同样如此,这样可以获得需要监听的端口和IP地址。之后,Nginx就要创建master进程,并建立socket,这样就可以创建多个worker进程来,每个worker进程都可以accept连接请求。当通过三次握手成功建立一个连接后,nginx的某一个worker进程会accept成功,得到这个建立好的连接的socket,然后创建ngx_connection_t结构体,存储客户端相关内容。
这样建立好连接后,服务器和客户端就可以正常进行读写事件了。连接完成后就可以释放掉ngx_connection_t结构体了。 同样,Nginx也可以作为客户端,这样就需要先创建一个ngx_connection_t结构体,然后创建socket,并设置socket的属性( 比如非阻塞)。然后再通过添加读写事件,调用connect/read/write来调用连接,最后关掉连接,并释放ngx_connection_t。struct ngx_connection_s { void *data; ngx_event_t *read; ngx_event_t *write;
ngx_socket_t fd;
ngx_recv_pt recv; ngx_send_pt send; ngx_recv_chain_pt recv_chain; ngx_send_chain_pt send_chain;
ngx_listening_t *listening;
off_t sent;
ngx_log_t *log;
ngx_pool_t *pool;
struct sockaddr *sockaddr; socklen_t socklen; ngx_str_t addr_text;
#if (NGX_SSL) ngx_ssl_connection_t *ssl;#endif
struct sockaddr *local_sockaddr;
ngx_buf_t *buffer;
ngx_queue_t queue; ngx_atomic_uint_t number; ngx_uint_t requests; unsigned buffered:8; unsigned log_error:3; unsigned unexpected_eof:1; unsigned timedout:1; unsigned error:1; unsigned destroyed:1;
unsigned idle:1; unsigned reusable:1; unsigned close:1;
unsigned sendfile:1; unsigned sndlowat:1; unsigned tcp_nodelay:2; unsigned tcp_nopush:2;
#if (NGX_HAVE_IOCP) unsigned accept_context_updated:1;#endif
#if (NGX_HAVE_AIO_SENDFILE) unsigned aio_sendfile:1; ngx_buf_t *busy_sendfile;
#endif
#if (NGX_THREADS) ngx_atomic_t lock;#endif};
连接池
在linux系统中,每一个进程能够打开的文件描述符fd是有限的,而每创建一个socket就会占用一个fd,这样创建的socket就会有限的。在Nginx中,采用连接池的方法,可以避免这个问题。 Nginx在实现时,是通过一个连接池来管理的,每个worker进程都有一个独立的连接池,连接池的大小是worker_connections。这里的连接池里面保存的其实不是真实的连接,它只是一个worker_connections大小的一个ngx_connection_t结构的数组。并且,nginx会通过一个链表free_connections来保存所有的空闲ngx_connection_t,每次获取一个连接时,就从空闲连接链表中获取一个,用完后,再放回空闲连接链表里面(这样就节省了创建与销毁connection结构的开销)。 所以对于一个Nginx服务器来说,它所能创建的连接数也就是socket连接数目可以达到worker_processes(worker数)*worker_connections。竞争问题
对于多个worker进程同时accpet时产生的竞争,有可能导致某一worker进程accept了大量的连接,而其他worker进程却没有几个连接,这样就导致了负载不均衡,对于负载重的worker进程中的连接响应时间必然会增大。很显然,这是不公平的,有的进程有空余连接,却没有处理机会,有的进程因为没有空余连接,却人为地丢弃连接。 nginx中存在accept_mutex选项,只有获得了accept_mutex的进程才会去添加accept事件,也就是说,nginx会控制进程是否添加accept事件。nginx使用一个叫ngx_accept_disabled的变量来控制进程是否去竞争accept_mutex锁。ngx_accept_disabled = ngx_cycle->connection_n / 8 - ngx_cycle->free_connection_n;
if (ngx_use_accept_mutex) { if (ngx_accept_disabled > 0) { //当disabled的值大于0时,禁止竞争,但每次-1 ngx_accept_disabled--; } else { if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) { return; } if (ngx_accept_mutex_held) { flags |= NGX_POST_EVENTS; } else { if (timer == NGX_TIMER_INFINITE || timer > ngx_accept_mutex_delay) { timer = ngx_accept_mutex_delay; } }
}}
request
在nginx中,request是http请求,具体到nginx中的数据结构是ngx_http_request_t。ngx_http_request_t是对一个http请求的封装。 struct ngx_http_request_s { uint32_t signature;
ngx_connection_t *connection;
void **ctx; void **main_conf; void **srv_conf; void **loc_conf;
ngx_http_event_handler_pt read_event_handler; ngx_http_event_handler_pt write_event_handler;
#if (NGX_HTTP_CACHE) ngx_http_cache_t *cache;#endif
ngx_http_upstream_t *upstream; ngx_array_t *upstream_states;
ngx_pool_t *pool; ngx_buf_t *header_in;
ngx_http_headers_in_t headers_in; ngx_http_headers_out_t headers_out;
ngx_http_request_body_t *request_body;
time_t lingering_time; time_t start_sec; ngx_msec_t start_msec;
ngx_uint_t method; ngx_uint_t http_version;
ngx_str_t request_line; ngx_str_t uri; ngx_str_t args; ngx_str_t exten; ngx_str_t unparsed_uri;
ngx_str_t method_name; ngx_str_t http_protocol;
ngx_chain_t *out; ngx_http_request_t *main; ngx_http_request_t *parent; ngx_http_postponed_request_t *postponed; ngx_http_post_subrequest_t *post_subrequest; ngx_http_posted_request_t *posted_requests;
ngx_int_t phase_handler; ngx_http_handler_pt content_handler; ngx_uint_t access_code;
ngx_http_variable_value_t *variables;
#if (NGX_PCRE) ngx_uint_t
ncaptures; int *captures; u_char *captures_data;#endif
size_t limit_rate;
size_t header_size;
off_t request_length;
ngx_uint_t err_status;
ngx_http_connection_t *http_connection;#if (NGX_HTTP_SPDY) ngx_http_spdy_stream_t *spdy_stream;#endif
ngx_http_log_handler_pt log_handler;
ngx_http_cleanup_t *cleanup;
unsigned subrequests:8; unsigned count:8; unsigned blocked:8;
unsigned aio:1;
unsigned http_state:4;
unsigned complex_uri:1;
unsigned quoted_uri:1;
unsigned plus_in_uri:1;
unsigned space_in_uri:1;
unsigned invalid_header:1;
unsigned add_uri_to_alias:1; unsigned valid_location:1; unsigned valid_unparsed_uri:1; unsigned uri_changed:1; unsigned uri_changes:4;
unsigned request_body_in_single_buf:1; unsigned request_body_in_file_only:1; unsigned request_body_in_persistent_file:1; unsigned request_body_in_clean_file:1; unsigned request_body_file_group_access:1; unsigned request_body_file_log_level:3;
unsigned subrequest_in_memory:1; unsigned waited:1;
#if (NGX_HTTP_CACHE)
unsigned cached:1;#endif
#if (NGX_HTTP_GZIP) unsigned gzip_tested:1; unsigned gzip_ok:1; unsigned gzip_vary:1;#endif
unsigned proxy:1; unsigned bypass_cache:1; unsigned no_cache:1;
unsigned limit_conn_set:1; unsigned limit_req_set:1;
#if 0 unsigned cacheable:1;#endif
unsigned pipeline:1; unsigned chunked:1; unsigned header_only:1; unsigned keepalive:1;
unsigned lingering_close:1; unsigned discard_body:1; unsigned internal:1; unsigned error_page:1; unsigned ignore_content_encoding:1; unsigned filter_finalize:1; unsigned post_action:1; unsigned request_complete:1; unsigned request_output:1; unsigned header_sent:1; unsigned expect_tested:1; unsigned root_tested:1; unsigned done:1; unsigned logged:1;
unsigned buffered:4;
unsigned main_filter_need_in_memory:1; unsigned filter_need_in_memory:1; unsigned filter_need_temporary:1; unsigned allow_ranges:1;
#if (NGX_STAT_STUB) unsigned stat_reading:1; unsigned stat_writing:1;#
endif
ngx_uint_t state;
ngx_uint_t header_hash; ngx_uint_t lowcase_index; u_char lowcase_header[NGX_HTTP_LC_HEADER_LEN];
u_char *header_name_start; u_char *header_name_end; u_char *header_start; u_char *header_end;
u_char *uri_start; u_char *uri_end; u_char *uri_ext; u_char *args_start; u_char *request_start; u_char *request_end; u_char *method_end; u_char *schema_start; u_char *schema_end; u_char *host_start; u_char *host_end; u_char *port_start; u_char *port_end;
unsigned http_minor:16; unsigned http_major:16;};
HTTP
http请求是典型的请求-响应类型的的网络协议,需要一行一行的分析请求行与请求头,以及输出响应行与响应头。 Request 消息分为3部分,第一部分叫请求行requset line, 第二部分叫http header, 第三部分是body. header和body之间有个空行。 Response消息的结构, 和Request消息的结构基本一样。同样也分为三部分,第一部分叫response line, 第二部分叫response header,第三部分是body. header和body之间也有个空行。 分别为Request和Response消息结构图:
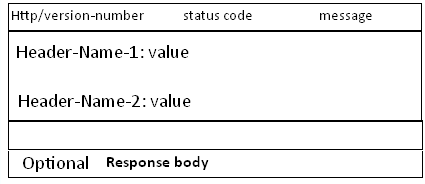
处理流程
worker进程负责业务处理。在worker进程中有一个函数ngx_worker_process_cycle(),执行无限循环,不断处理收到的来自客户端的请求,并进行处理,直到整个nginx服务被停止。- 初始化HTTP Request(读取来自客户端的数据,生成HTTP Requst对象,该对象含有该请求所有的信息)。
- 如果有的话,调用与此请求(URL或者Location)关联的handler
这里直接上taobao团队的给出的Nginx流程图了。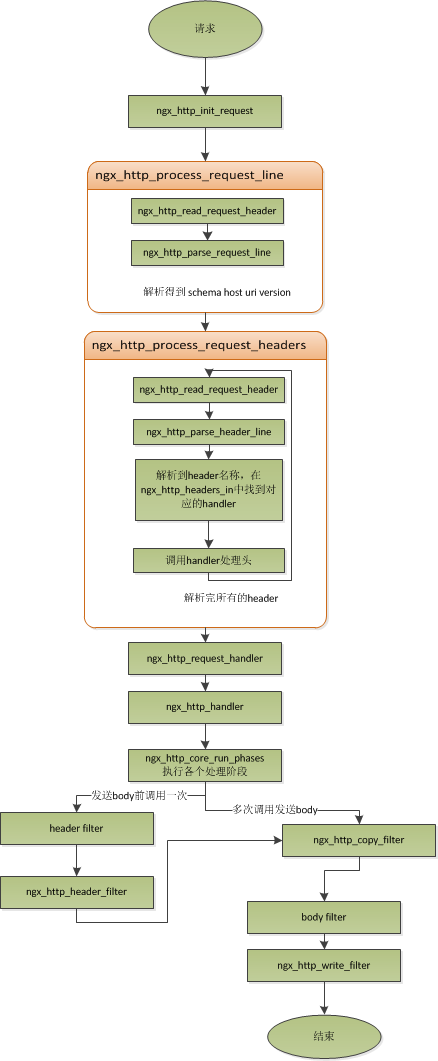
从这个图中可以清晰的看到解析http消息每个部分的不同模块。
keepalive长连接
长连接的定义:所谓长连接,指在一个连接上可以连续发送多个数据包,在连接保持期间,如果没有数据包发送,需要双方发链路检测包。
在这里,http请求是基于TCP协议之上的,所以建立需要三次握手,关闭需要四次握手。而http请求是请求应答式的,如果我们能知道每个请求头与响应体的长度,那么我们是可以在一个连接上面执行多个请求的,这就需要在请求头中指定content-length来表明body的大小。在http1.0与http1.1中稍有不同,具体情况如下:
对于http1.0协议来说,如果响应头中有content-length头,则以content-length的长度就可以知道body的长度了,客户端在接收body时,就可以依照这个长度来接收数据,接收完后,就表示这个请求完成了。而如果没有content-length头,则客户端会一直接收数据,直到服务端主动断开连接,才表示body接收完了。而对于http1.1协议来说,如果响应头中的Transfer-encoding为chunked传输,则表示body是流式输出,body会被分成多个块,每块的开始会标识出当前块的长度,此时,body不需要通过长度来指定。如果是非chunked传输,而且有content-length,则按照content-length来接收数据。
否则,如果是非chunked,并且没有content-length,则客户端接收数据,直到服务端主动断开连接。
当客户端的一次访问,需要多次访问同一个server时,打开keepalive的优势非常大,比如图片服务器,通常一个网页会包含很多个图片。打开keepalive也会大量减少time-wait的数量。pipeline管道线
管道技术是基于长连接的,目的是利用一个连接做多次请求。 keepalive采用的是串行方式,而pipeline也不是并行的,但是它可以减少两个请求间的等待的事件。nginx在读取数据时,会将读取的数据放到一个buffer里面,所以,如果nginx在处理完前一个请求后,如果发现buffer里面还有数据,就认为剩下的数据是下一个请求的开始,然后就接下来处理下一个请求,否则就设置keepalive。lingering_close延迟关闭
当Nginx要关闭连接时,并非立即关闭连接,而是再等待一段时间后才真正关掉连接。目的在于读取客户端发来的剩下的数据。 如果服务器直接关闭,恰巧客户端刚发送消息,那么就不会有ACK,导致出现没有任何错误信息的提示。 Nginx通过设置一个读取客户数据的超时事件lingering_timeout来防止以上问题的发生。
Nginx中的数组
ngx_array_s是Nginx中的数组,原型为ngx_array_t。
typedef struct { void *elts; ngx_uint_t nelts; size_t size; ngx_uint_t nalloc; ngx_pool_t *pool; } ngx_array_t;
这里的数组已经远远超出了C语言中数据的概念,类似于Vector。
具体操作参见源码。
Nginx中的队列
ngx_queue_t是Nginx中的队列元素,原型为ngx_queue_s.
struct ngx_queue_s { ngx_queue_t *prev; ngx_queue_t *next;};
具体操作参见源码。
Nginx中的链表
ngx_list_t是Nginx中的list结构。
typedef struct { ngx_list_part_t *last; ngx_list_part_t part; size_t size; ngx_uint_t nalloc; ngx_pool_t *pool; } ngx_list_t;
ngx_list_part_t是Nginx中的List的元素结构。
struct ngx_list_part_s { void *elts; ngx_uint_t nelts; ngx_list_part_t *next;};
具体操作参见源码。
Nginx中的string--ngx_str_t
ngx_str_t为Nginx自身实现的string结构,与c中的字符串不同。
typedef struct { size_t len; u_char *data; } ngx_str_t;
ngx_str_t包括两部分,一部分是字符串的长度,另外一部分是数据。注意:这里的数据是指向字符的一个指针,且这个字符串不是以“0”结尾,是通过长度来控制的。使用指针,省去了拷贝所占用的内存空间。
其他Nginx-String的操作可以看Nginx源码,还是蛮清晰的。
Ngnix中的内存分配和释放
在Ngnix中负责内存分配和释放的结构体为ngx_pool_t,它的原型为ngx_pool_s。
struct ngx_pool_s { ngx_pool_data_t d; size_t max; ngx_pool_t
*current; ngx_chain_t *chain; ngx_pool_large_t *large; ngx_pool_cleanup_t *cleanup; ngx_log_t *log;};
具体操作参考源码。
Nginx中的Hash表
ngx_hash_t是Nginx中的hash表。
typedef struct { ngx_hash_elt_t **buckets; ngx_uint_t size;} ngx_hash_t;
其中ngx_hash_elt_t为数据。
typedef struct { void *value; u_short len; u_char name[1]; } ngx_hash_elt_t;
但是ngx_hash_t的实现又有其几个显著的特点:
ngx_hash_t不像其他的hash表的实现,可以插入删除元素,它只能一次初始化,就构建起整个hash表以后,既不能再删除,也不能在插入元素了。
ngx_hash_t的开链并不是真的开了一个链表,实际上是开了一段连续的存储空间,几乎可以看做是一个数组。这是因为ngx_hash_t在初始化的时候,会经历一次预计算的过程,提前把每个桶里面会有多少元素放进去给计算出来,这样就提前知道每个桶的大小了。那么就不需要使用链表,一段连续的存储空间就足够了。这也从一定程度上节省了内存的使用。
实际上ngx_hash_t的使用是非常简单,首先是初始化,然后就可以在里面进行查找了。
Nginx中的红黑树
ngx_rbtree_node_s是Nginx中的红黑树节点。
struct ngx_rbtree_node_s { ngx_rbtree_key_t key; ngx_rbtree_node_t *left; ngx_rbtree_node_t *right;
ngx_rbtree_node_t *parent; u_char color; u_char data;};
ngx_rbtree_s是Nginx中的红黑树。
struct ngx_rbtree_s { ngx_rbtree_node_t *root; ngx_rbtree_node_t *sentinel; ngx_rbtree_insert_pt insert;};
具体操作参见源码。
参考:http://tengine.taobao.org/book/#id2
·END·
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
作者:cococo点点
来源:https://www.cnblogs.com/coder2012/p/3141469.html
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!










