(给ImportNew加星标,提高Java技能)
转自:捡田螺的小男孩
前言
整理了一些 MySQL 数据库相关流程图/原理图。做一下笔记,大家一起学习。
1. MySQL 主从复制原理图
MySQL 主从复制原理是大厂后端的高频面试题,了解 MySQL 主从复制原理非常有必要。
主从复制原理简言之,就三步曲,如下:
主数据库有个 bin-log 二进制文件,记录了所有增删改 SQL 语句(binlog线程);
从数据库把主数据库的 bin-log 文件的 SQL 语句复制过来(I/O线程);
从数据库的 relay-log 重做日志文件中再执行一次这些 SQL 语句(SQL 执行线程)。
如下图所示:
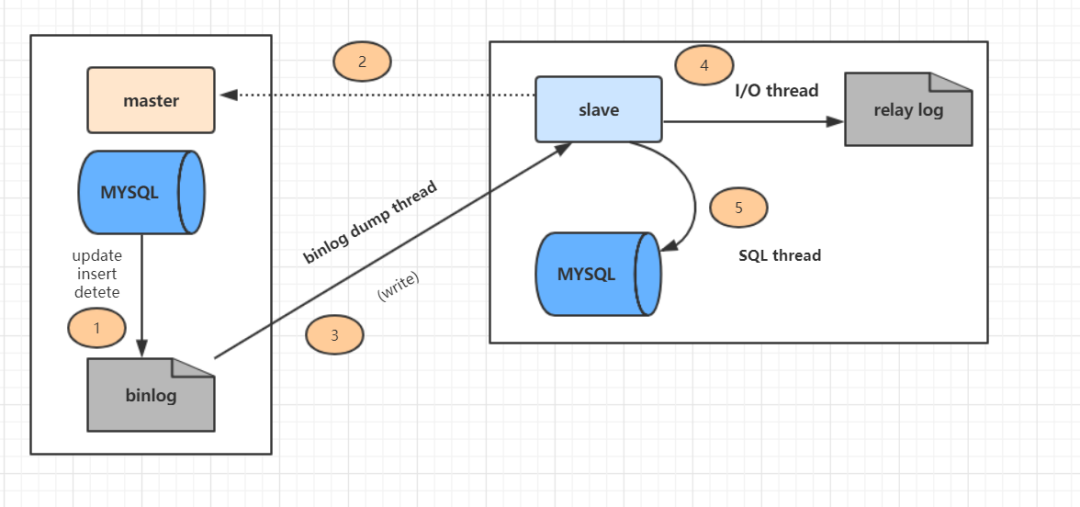
上图主从复制分了五个步骤进行:
步骤一:主库的更新事件(update、insert、delete)被写到 binlog;
步骤二:从库发起连接,连接到主库;
步骤三:此时主库创建一个 binlog dump thread,把 binlog 的内容发送到从库;
步骤四:从库启动之后,创建一个 I/O 线程,读取主库传过来的 binlog 内容并写入到 relay log;
步骤五:还会创建一个 SQL 线程,从 relay log 里面读取内容,从 Exec_Master_Log_Pos 位置开始执行读取到的更新事件,将更新内容写入到 slave 的 DB。
2. MySQL 逻辑架构图
如果能在脑海中构建出 MySQL 各组件之间如何协同工作的架构图,就会有助于深入理解 MySQL 服务器。
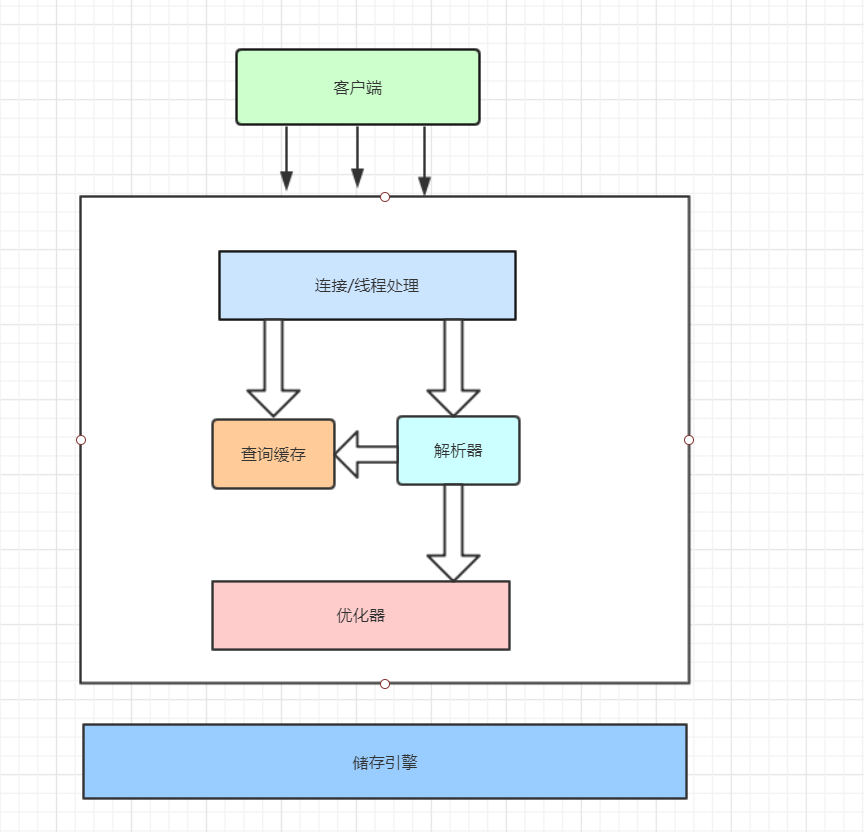
MySQL 逻辑架构图主要分三层:
第一层负责连接处理,授权认证,安全等。
每个客户端连接都会在服务器进程中拥有一个线程,服务器维护了一个线程池,因此不需要为每一个新建的连接创建或者销毁线程;
当客户端连接到Mysql服务器时,服务器对其进行认证,通过用户名和密码认证,也可以通过SSL证书进行认证;
一旦客户端连接成功,服务器会继续验证客户端是否具有执行某个特定查询的权限。
第二层负责编译并优化SQL。
这一层包括查询解析,分析,优化,缓存以及所有的的内置函数;
对于SELECT语句,在解析查询前,服务器会先检查查询缓存,如果能在其中找到对应的查询结果,则无需再进行查询解析、优化等过程,直接返回查询结果;
所有跨存储引擎的功能都在这一层实现:存储过程,触发器,视图。
第三层是存储引擎。
存储引擎负责在 MySQL 中存储数据、提取数据;
存储引擎通过 API 与上层进行通信,这些 API 屏蔽了不同存储引擎之间的差异,使得这些差异对上层查询过程透明;
存储引擎不会去解析 SQL,不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
3. InnoDB 逻辑存储结构图
从 InnoDB 存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时候也称为块(block)。
InnoDB 逻辑存储结构图如下:
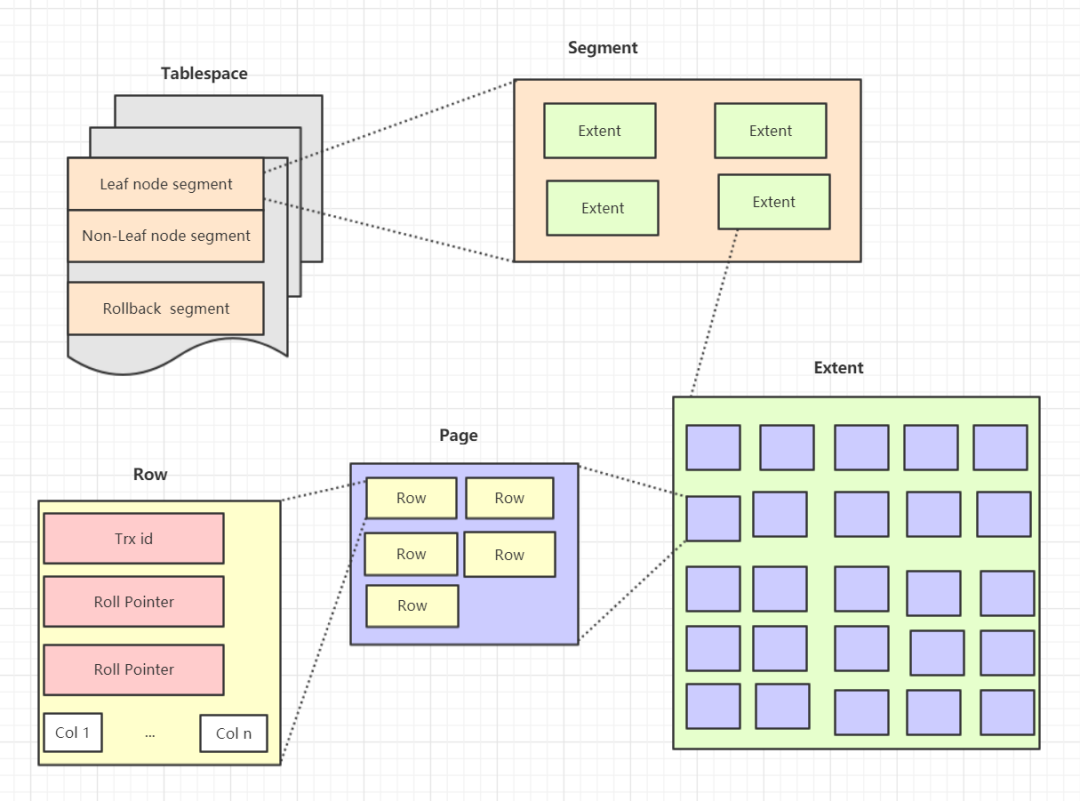
表空间(tablespace)
表空间是 Innodb 存储引擎逻辑的最高层,所有的数据都存放在表空间中;
默认情况下 Innodb 存储引擎有一个共享表空间 ibdata1,即所有数据都存放在这个表空间中内;
如果启用了 innodb_file_per_table 参数,需要注意的是每张表的表空间内存放的只是数据、索引、和插入缓冲 Bitmap,其他类的数据,比如回滚(undo)信息、插入缓冲检索页、系统事物信息,二次写缓冲等还是放在原来的共享表内的。
段(segment)
表空间由段组成,常见的段有数据段、索引段、回滚段等;
InnoDB 存储引擎表是索引组织的,因此数据即索引,索引即数据。数据段即为 B+ 树的叶子结点,索引段即为 B+ 树的非索引结点;
在 InnoDB 存储引擎中对段的管理都是由引擎自身所完成,DBA 不能也没必要对其进行控制。
区(extent)
区是由连续页组成的空间,在任何情况下每个区的大小都为 1MB;
为了保证区中页的连续性,InnoDB 存储引擎一次从磁盘申请 4~5 个区
默认情况下,InnoDB 存储引擎页的大小为 16KB,一个区中一共 64 个连续的区。
页(page)
页是 InnoDB 磁盘管理的最小单位;
在 InnoDB 存储引擎中,默认每个页的大小为 16KB;
从 InnoDB1.2.x 版本开始,可以通过参数 innodb_page_size 将页的大小设置为 4K、8K、16K;
InnoDB 存储引擎中,常见的页类型有:数据页、undo页、系统页、事务数据页、插入缓冲位图页、插入缓冲空闲列表页等。
4. InnoDB页结构相关示意图
4.1 InnoDB 页结构单体图
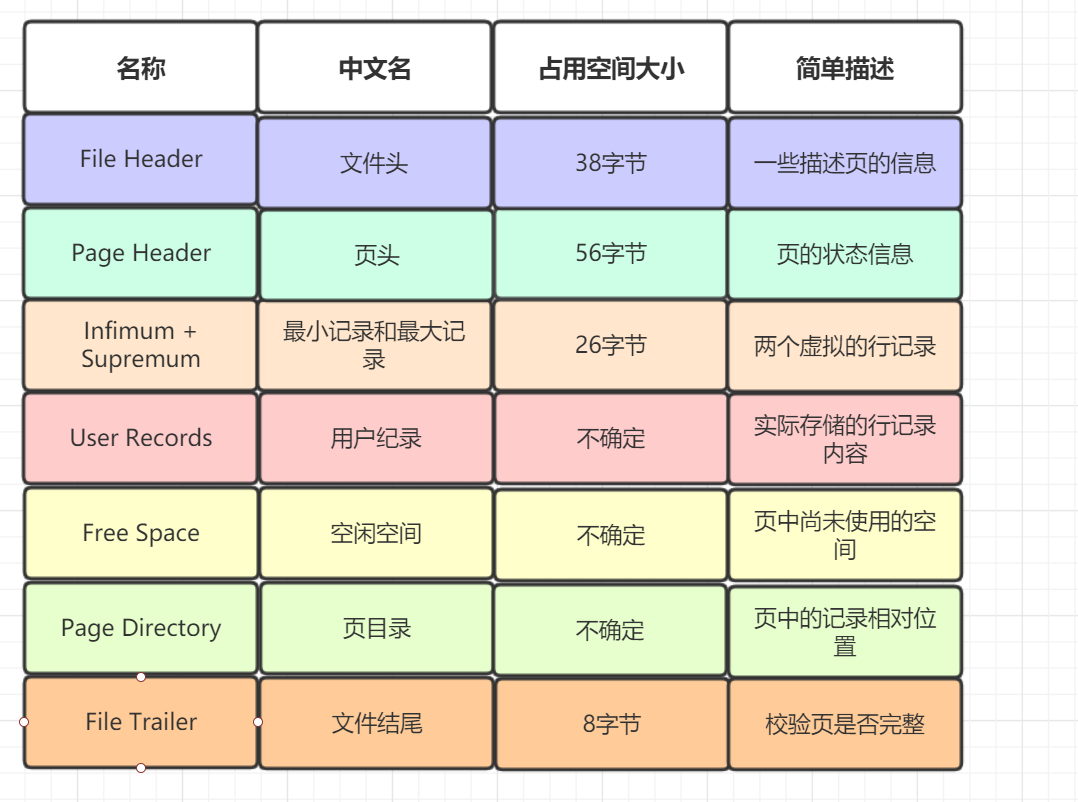
InnoDB 数据页由以下 7 部分组成,如图所示:
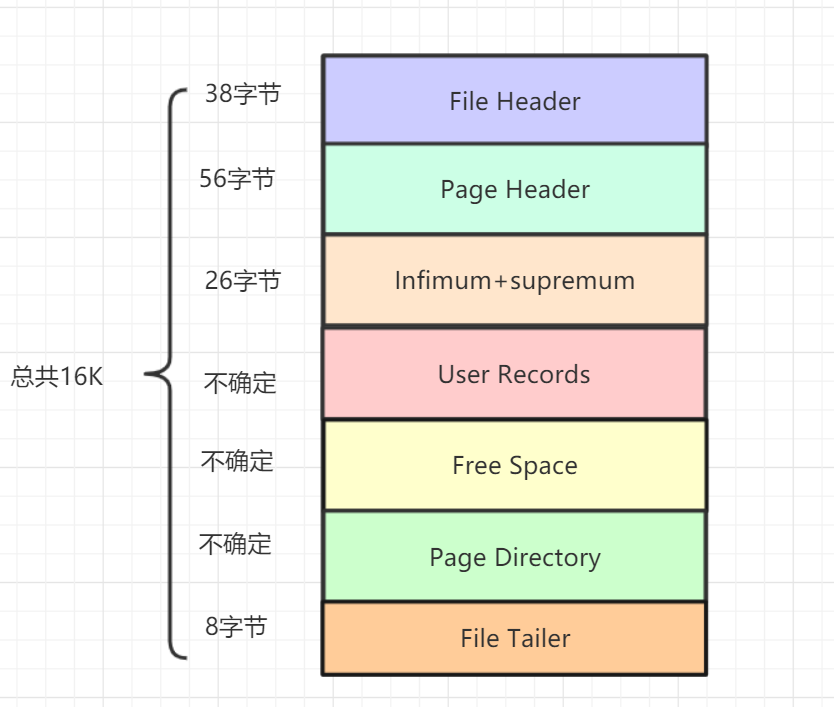
其中 File Header、Page Header、File Trailer 的大小是固定的,分别为 38、56、8 字节,这些空间用来标记该页的一些信息,如 Checksum,数据页所在 B+ 树索引的层数等。User Records、Free Space、Page Directory 这些部分为实际的行记录存储空间,因此大小是动态的。
下边我们用表格的方式来大致描述一下这 7 个部分:
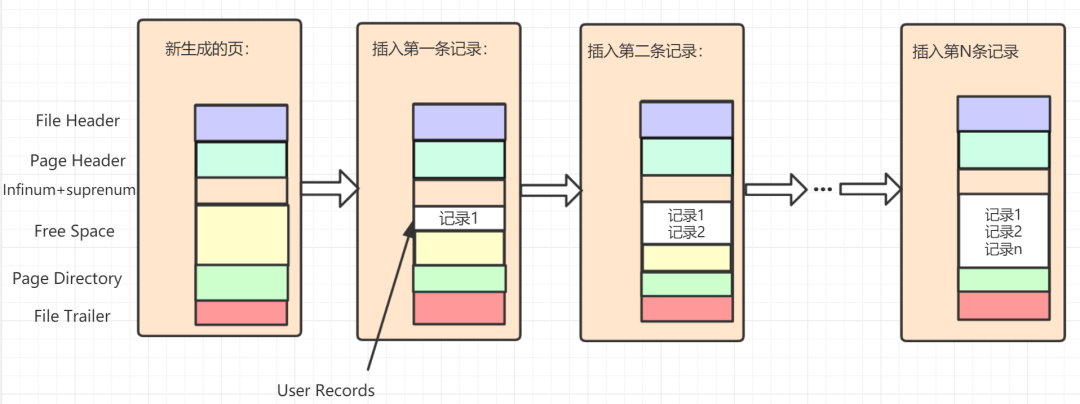
4.2 记录在页中的存储流程图
每当我们插入一条记录,都会从 Free Space 部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到 User Records 部分,当 Free Space 部分的空间全部被 User Records 部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了,这个过程的图示如下:
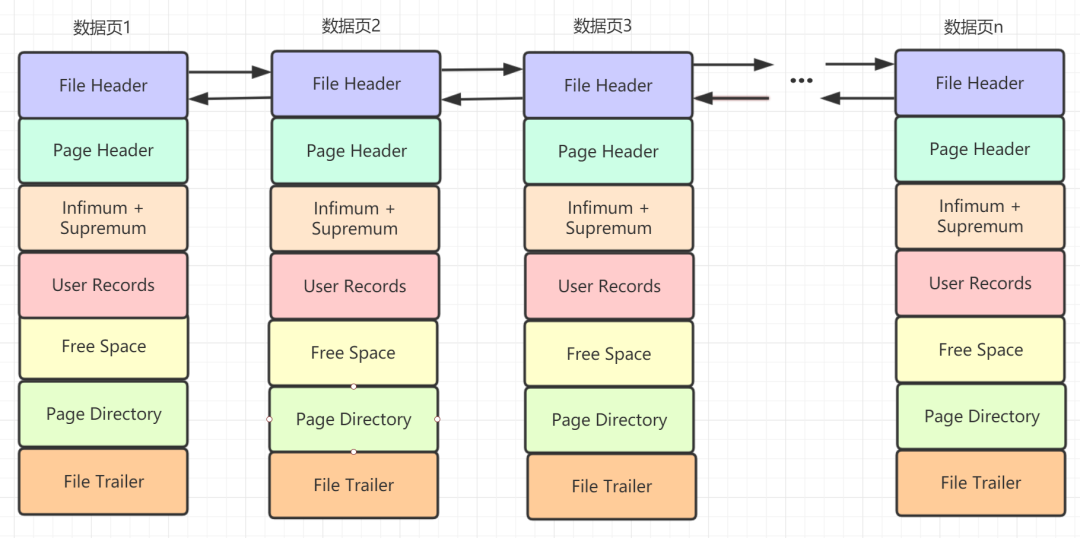
4.3 不同Innodb页构成的数据结构图
一张表中可以有成千上万条记录,一个页只有 16KB,所以可能需要好多页来存放数据。不同页其实构成了一条双向链表,File Header 是 InnoDB 页的第一部分,它的 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 就分别代表本页的上一个和下一个页的页号,即链表的上一个以及下一个节点指针。
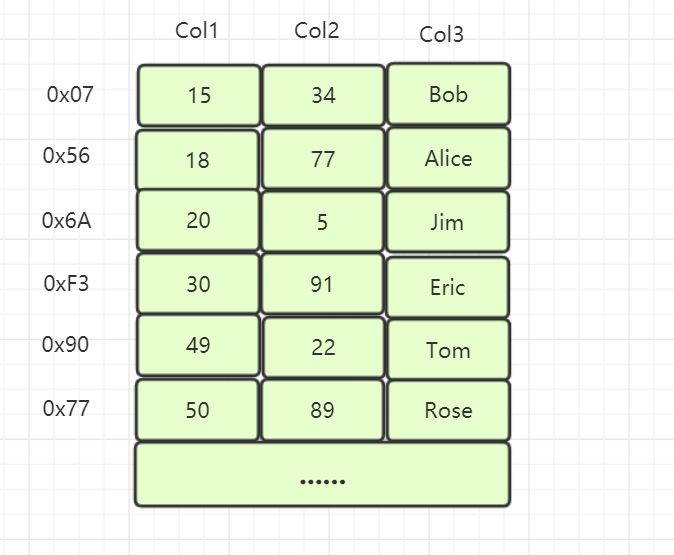
5. Innodb索引结构图
我们先看一份数据表样本,假设 Col1 是主键,如下:
5.1 B+ 树聚集索引结构图
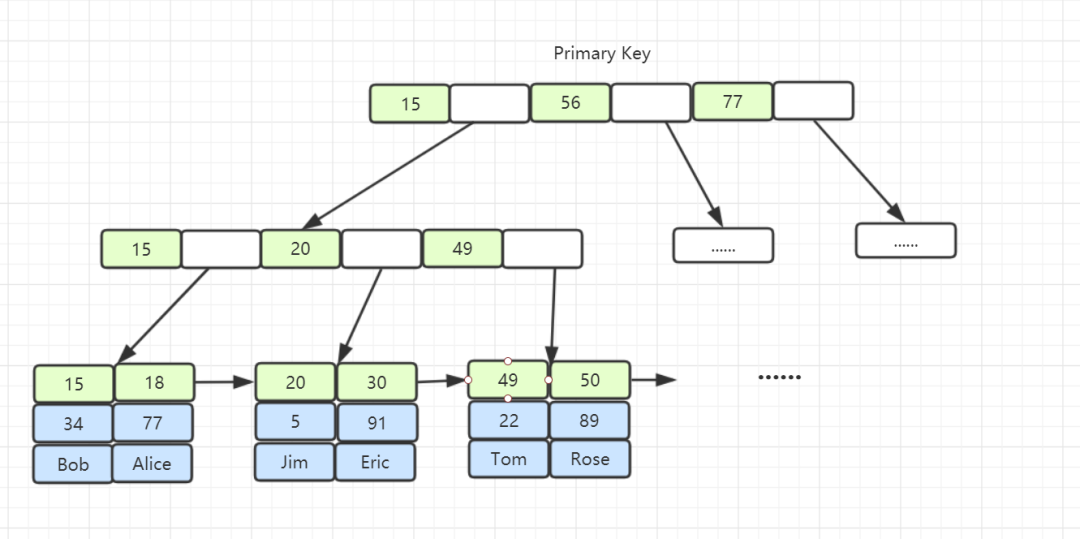
聚集索引就是以主键创建的索引;
聚集索引在叶子节点存储的是表中的数据。
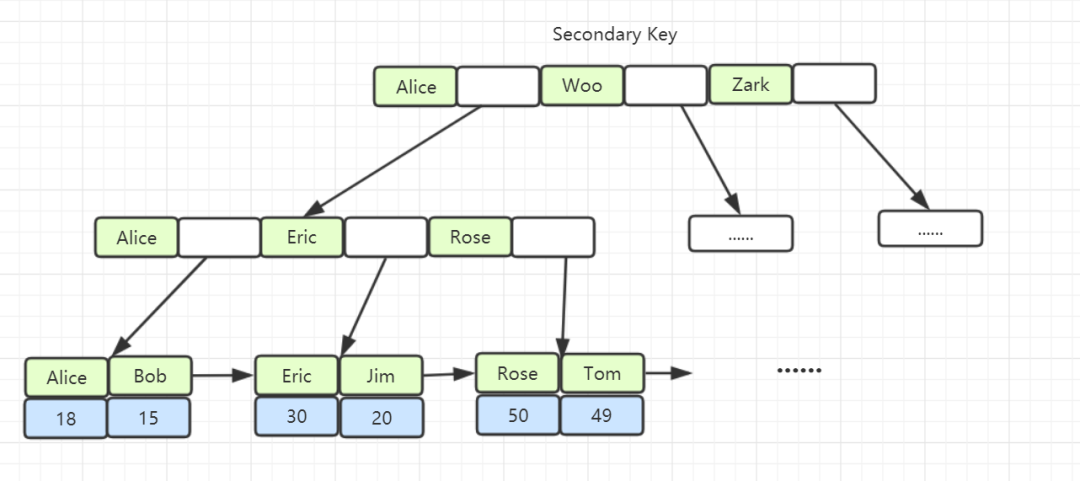
5.2 非聚集索引结构图
假设索引列为 Col3,索引结构图如下:
5.3 InnoDB 锁类型思维导图
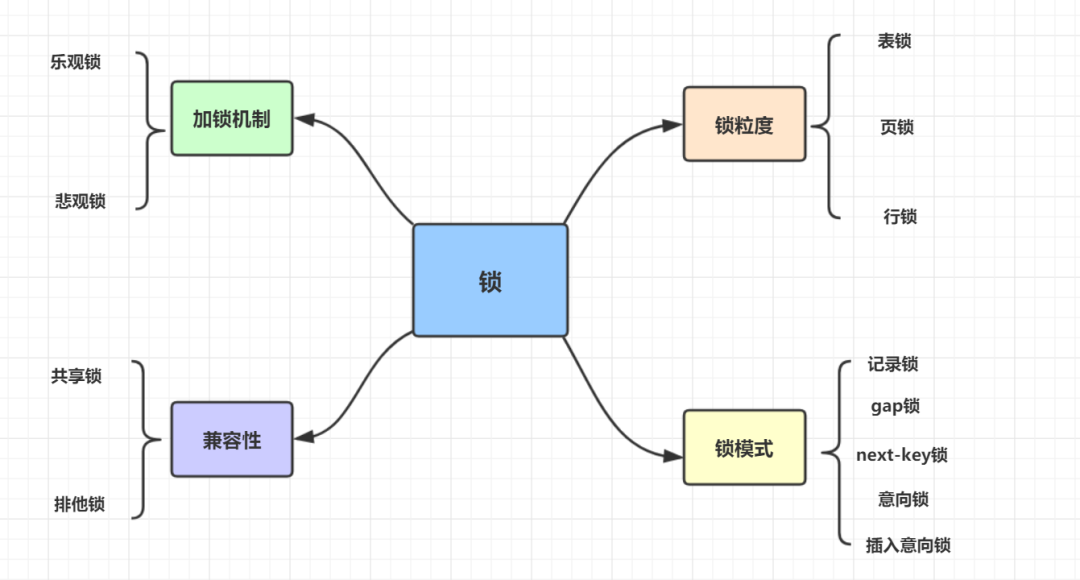
5.4 加锁机制
乐观锁与悲观锁是两种并发控制的思想,可用于解决丢失更新问题。
乐观锁
悲观锁
5.5 锁粒度
表锁: 开销小,加锁快;锁定力度大,发生锁冲突概率高,并发度最低;不会出现死锁;
行锁: 开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高;
页锁: 开销和加锁速度介于表锁和行锁之间;会出现死锁;锁定粒度介于表锁和行锁之间,并发度一般。
5.6 兼容性
共享锁
排他锁
5.7 锁模式
记录锁: 在行相应的索引记录上的锁,锁定一个行记录;
gap 锁: 是在索引记录间歇上的锁,锁定一个区间;
next-key 锁: 是记录锁和在此索引记录之前的 gap 上的锁的结合,锁定行记录+区间;
意向锁:是为了支持多种粒度锁同时存在。
6. 参考与感谢
《MySQL 技术内幕》
《高性能 MySQL》
MySQL InnoDB 锁机制全面解析分享: https://segmentfault.com/a/1190000014133576
数据库两大神器【索引和锁】: https://juejin.im/post/5b55b842f265da0f9e589e79#heading-2
InnoDB 的逻辑存储结构学习: https://blog.csdn.net/m0_37752084/article/details/80496490
MySQL 索引背后的数据结构及算法原理: http://blog.codinglabs.org/articles/theory-of-mysql-index.html
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能

好文章,我在看❤️







