
《Artificial Intuition》是今年2月新出版的一本书,工科背景的作者Carlos Perez在自述中说这是一本写给大众的深度学习入门书,然而在我看来,这是一本写给AI产品经理的有很大的阅读难度的书,书后的参考文献有几十页厚,提到的论文有上千篇,其中有很多是理论的探讨性的文章,是一本需要反复阅读的书。要理解这本书,我们可以站在一个产品经理的角度,去看看深度学习有什么特别之处。
现在关于深度学习的应用案例的描述,没有百万篇也有十万篇的介绍文章。AI相关的创业者都在问这样两个问题,第一是深度学习和之前的机器学习有什么本质的区别,第二个问题是会不会出现下一个AI的冬天,或者深度学习带来的革命性改变的上线在那里?而《Artificial Intuition》这本书则试图回答下面的两个问题,回答的方式是通过揭示深度学习的三个基石性的算法背后的道理。
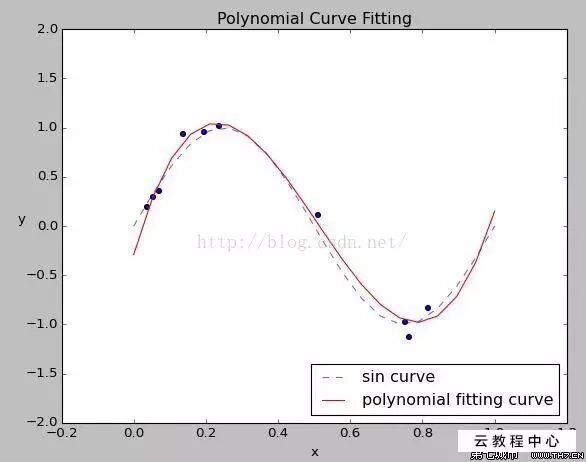
先总结下传统的机器学习方法,这些方法不管是什么,都可以看成是去根据已知的数据点拟合一条未知的曲线(如上图),这些模型不管其本身多么复杂,都只是单个的模型而已,但深度学习却不是这样的,链式法则使深度学习具有了分形和性质,而这是深度学习有别于传统机器学习的第一点。
所谓分形(不熟悉分形的读者,点击查看16张gif图带你认识分形(fractal)),指得是部分和整体的关系如同俄罗斯套娃一样,你永远不知道自己是不是拆到最小的那个。在每个神经元的层面,训练模型的和传统方法目标一致,是拟合一条线。但由于链式法则,使得多层的神经网络的目标变成拟合一个函数的函数。深度学习的特点不只是其需要优化的参数远远多于传统的模型,因此数据越多,效果越好,更重要的是深度学习要优化的参数相互间是有关联的。
不止在神经元的层面可以看到类似分形的性质,残差神经网络和LSTM使的网络的层与层之间具有了尺度一致性。残差网络是卷积神经网络的一种改进,在卷积层与层之间建立短路式的连接,让第一层网络和第三层网络可以直接连起来,这样绕过了中间层,使得网络中层级的概念变得当前所在的层次无关,在极端的情况下,残差网络使得底层的神经元能够直接连接顶层的神经元。而LSTM中的遗忘门,也在时间尺度上具有相似的效果。
深度学习中分形表现的第三点是在模型本身的层面进行复用,比如对抗神经网络GAN和自编码器,都是将模型本身作为了更大模型的一部分。而传统的机器学习,除了决策树,很少具有类似模型组合的性质。未来的深度学习框架,将不会只由一个网络组成,而是多个神经网络组合形成,例如先用CNN处理空间上的相似性,再用RNN来处理时间上的一致性。不管是GAN还是自编码器,没过几年就有越来越多的变种,之所以这是可能的,是因为模型本身可以拆开进行组合。迁移学习之所以在深度学习中变得普遍,也是托模型本身分形性质的福,不管是参数的微调还是模型最后几层的重复训练,传统的机器学习因为模型和数据绑定的太紧,即使可以做迁移,效果也不如深度学习。
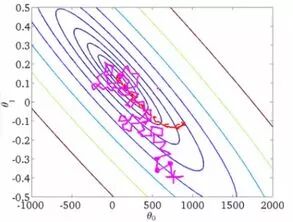
深度学习的第二个特点是平衡探索与利用的权衡(explore VS exploitation),这可以从深度学习中最常用的一个方法随机梯度下降中看出。当你有太多的参数需要优化的时候,你首先需要是找出先在那些方向上做出改变,效果最好,而这是梯度要度量的。但若只是梯度,那就只是利用当前的信息,在梯度上随机的加上一个变化的量,可以起到探索的作用,使得模型能够越过局部最优点和没有梯度的鞍点,从而使得模型能够找到最优解。
另一个例子是卷积神经网络三明治中的部分,卷积层用来进行探索,找出通用的结构,而池化层所作的则可以看出是对已有信息的利用(降低原始信息的维度),最后在通过批量正则化引入随机性。相比之下,传统的模型只注重利用信息的一面,而会忽略对未知结构的探索。能同时兼顾到探索和权衡,是深度学习能够解决之前无法解决问题的根本原因。由于随机梯度下降及其改进版的优化方法是任何神经网络都会用到的方法,因此其具有普世的解释性,能够部分的说明为什么深度学习能够成功。
不同于传统模型的确定性,深度学习每一次的训练都是动态的,其训练成的网络也会有细微的的差别。而深度学习中另一个通用的技术是反向传播算法,这可以看成是复杂系统中的负反馈,通过计算为什么模型会出错,训练的过程可以看成是动态演化的复杂系统。负反馈可以使复杂系统保持动态的稳定,而深度学习中的负反馈也使得模型不同于使用手工设置的优化函数的传统模型,能够持续的进行优化。
以上是《Artificial Intuition》这本书给出的关于深度学习为什么有效的回答。明白了这三点,可以让你更方便的思考你面临的场景是否适合深度学习。如果你面对的问题本身具有层次化的特点,需要平衡信息的探索与利用,需要动态的持续改进,那么深度学习就适合。但对于有些任务,以上三点还是远远不够的,还需要能够综合使用结构化的知识,而这是当前的深度学习技术的天花板,这个理论上线决定了当前的AI热潮是否会引来下一个冬天。
世上的决策不止是一串串的矩阵运算,而当前的深度学习落到实际的计算上,不过是一组矩阵运算。比如医学上的应用,深度学习只能够完成放射科医生的一部分工作,但判断这个片子是不是有肿瘤,只是诊断的第一步,医生需要根据病人的家族史和问诊的信息进行综合的判定。这些结构化的信息如何编码,又如何进行信息的整合,这其中既缺少明确的标签,从而难以进行监督学习;又无法像游戏那样,能够有足够的实例进行试错,从而无法进行强化学习;即使是非监督学习,由于直觉的判断步骤与步骤之间跳跃过大,使得模型也无法以类似词嵌入的方式进行前后步骤之间的预测。
虽然很难,但该如何结合结构化的信息,则是任何深度学习模型都会遇到的问题。要进行小数据上的迁移学习,就需要已有的模型能够提取一组原始高维数据的低维表示。但若是只是空间上的坐标,就无法进行逻辑推理,就无法结合专家的知识,模型的记忆也只有“是什么”这个层面,而没法进入“为什么”的层面。而人类的思维,则可以再想清楚了为什么之后,指定计划从而进入“怎么办”的层面。目前最成功的AI应用Alpha Zero,其背后的两个技术核心一是深度强化学习,二是蒙特卡罗树搜索。而蒙特卡罗树,就是一种结构化的知识表示方法,而现实世界中很多的任务无法像游戏中那样能够清晰的进行结构化的建模。
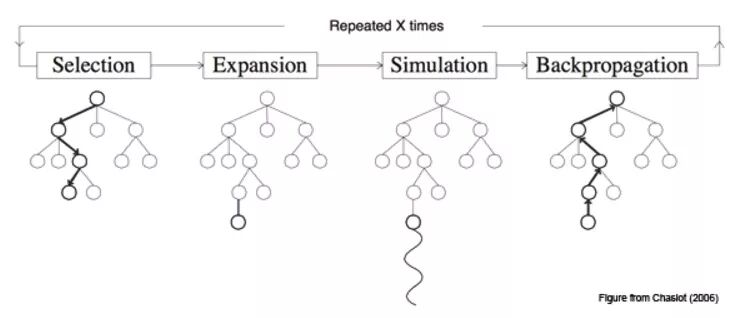
不举之前用过的医疗的例子,用教育中应用的AI作为例子。现在的AI能够批改作业,能够修改学生作文中的语法错误,还能够找出学生的问题更类似已知问题库中的那个问题。但好的老师能够做到因材施教,对同一个问题给不同的学生不同的答案,这就需要基于规则这种结构化的数据了。你可以先训练一个神经网络,通过和学生的闲聊了解学生的个性和学习进度,之后在回答学生问题时能够有针对性。但难点在于你如何解读上述神经网络打出的标签,教育和医疗一样,要求模型能够解释自己运行的逻辑。假设你训练好了一个在线问答系统,你不止需要证明你的系统能够在统计学意义上提高学生的成绩,还要证明自己的系统没有歧视弱势群体的孩子,没有给孩子们传递错误的价值观。例如这个对话系统学会了对于那些成绩差的学生问出的超过课程大纲的过难问题采取嘲笑的态度,也许能够使的这些孩子专注于基础知识,但却是不符合现代社会的伦理标准的。
而唯有将模型的中间结果结构化的表示出来,深度学习才可能摆脱助手的身份,成为能够和人平等对话的伙伴。而这将是深度学习下一步的进化方向,帮助人们更高的的认识未知的世界,而不只是重复人类可以做的决策过程。所谓的星辰大海,说得是深度学习在未知世界的探索中起到的作用,而这是这本书下半部分的内容。也将在本读书笔记的下篇中详细讲述。
总结一下,AI曾经被戏称为Artificial idiot,而在这本书中,作者认为深度学习使得模型能够产生类似人的直觉式的判断,因此可以称为Artificial Intuition。深度学习能够以涌现式的思考方式(动态,层级化)的处理由涌现而产生的复杂系统,这使得深度学习和传统的方法有了本质性的不同。但缺乏整合结构性数据的能力,制约了深度学习在日常生活中的应用,使得模型只能够在游戏等可以零风险试错的领域达到人类的水平,在其他领域还只能是是人类的助手,只能提高生产率,去除任务中重复性的部分,而无法革命性的让人类获得认知上的突破。这是当前AI的发展上线,也是AI界要攻克的圣杯。
更多阅读
读《人之彼岸》说说我心目中的AI与反乌托邦
原创不易,随喜赞赏,

联系小编,请加微信号ironcruiser 。








