西雅图是美国的超一线城市,不仅孕育了科技巨头微软,华盛顿大学也是城市的招牌,华人武术宗师李小龙也毕业于此。
陈天奇在AI圈的名气,好比李小龙在武术界的地位,且都是少年有成。
90后的陈天奇是机器学习领域著名的青年华人,在2020年秋季加入CMU任助理教授,成为加入CMU的年轻华人学者之一。

近日,陈天奇团队在arxiv上发表了针对深度学习开发的编译器「CORTEX」,侧重解决深度学习模型的优化问题,能够为递归神经网络生成高效的编码。
重点来了,这个编译器不依赖其他库,能够端到端地测量优化性能,最高降低了14倍推理延迟。
深度学习模型在生产中越来越多地被用作应用程序的一部分,例如个人助理,自动驾驶汽车和聊天机器人。

这些应用对模型的推理延迟提出了严格的要求。
因此,生产中使用了各种各样的专用硬件,包括CPU,GPU和专用加速器,以实现低延迟推理。
对于具有递归和其他动态控制流的模型,减少推理延迟尤其困难。
陈天奇提出了一个解决方法,一种递归深度学习模型的编译器「CORTEX」,在编译阶段就生成高效代码。
优化深度学习模型一般分两步进行:
这种方法对于递归深度学习模型,通常会表现出显著的性能。
递归深度学习模型的编译器「CORTEX」旨在构建一个编译器和运行基础结构,以通过不规则和动态的控制流,甚至不规则的数据结构访问也能有效地编译ML应用程序。
这种编译器方法和不依赖其他库,能够实现端到端优化,在不同backend上的推理延迟最多降低了14倍。
CORTEX包括一个运行框架,这个框架可以处理具有递归数据结构遍历的模型。
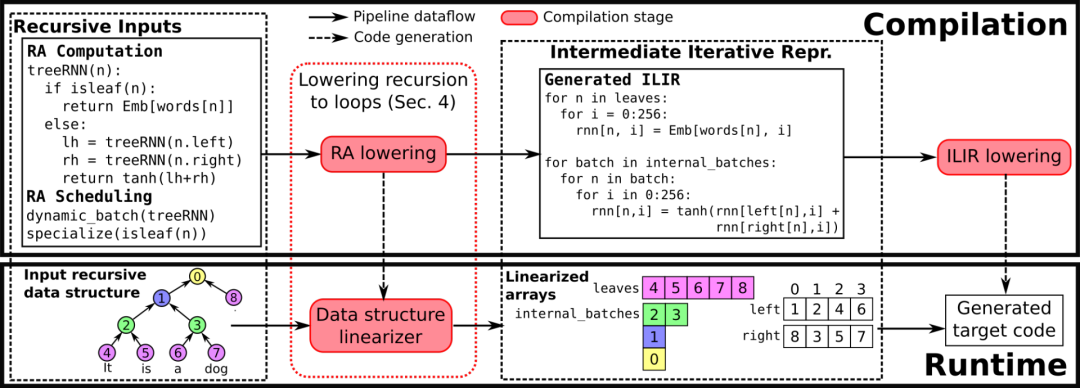
这个框架能够从张量计算中完全解开递归遍历,并进行部分推理,从而能够快速地将整个张量计算放入到硬件加速器(目前支持CPU和GPU)。
这意味着编译器可以生成一个高度优化的代码,能够避免加速器和主机CPU之间频繁通信的开销。
最后,论文总结了贡献:
- 设计了CORTEX,一个基于编译器的框架,可实现端到端优化和高效的代码生成,以递归深度学习模型的低延迟推理。
- 作为设计的一部分,扩展了张量编译器,并提出了递归模型的新调度原语和优化。
- 对提出的框架进行原型设计,并根据最新的递归深度学习框架对其进行评估,并获得了显着的性能提升( 在Nvidia GPU,Intel和ARM CPU上最高可达14倍)。
CORTEX需要具有模型计算的端到端视图,以便执行诸如内核融合之类的优化。
输入程序需要包含有关在模型中执行的张量操作的足够信息,以在将其降低到ILIR时进行调度。
从而RA将输入计算建模为运算符的DAG,其中每个运算符都指定为循环嵌套。
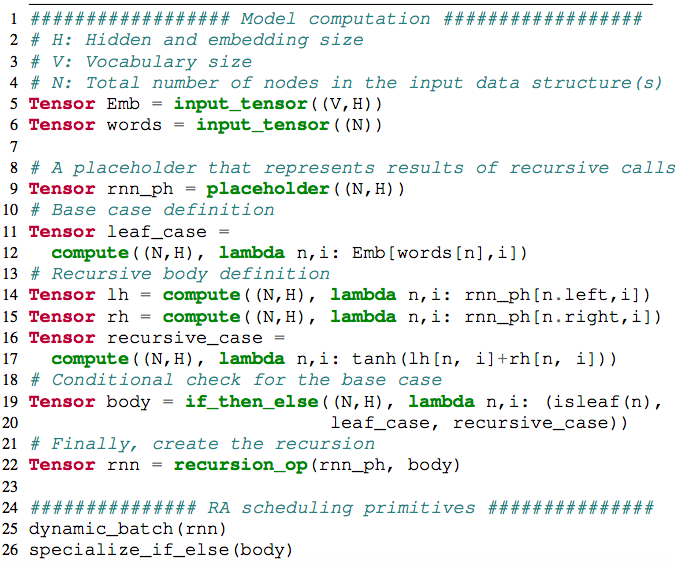
除了进行RA计算外,用户还需要提供有关输入数据结构的基本信息,例如每个节点的最大子代数以及数据结构的类型(序列,树或DAG)。
这些信息在编译期间使用,并且可以在运行时很容易验证。
从RA到ILIR的降低本质上是从递归到迭代的降低。因此,陈团队在降低过程中使所有临时显性张量。
他们还具体化了张量rnn,它存储了计算结果。三个张量中的每个张量都存储每个递归调用的数据,在这种情况下,这些数据相当于每个树节点。
ILIR是张量编译器使用的程序表示的扩展。因此,ILIR中分别指定了计算和优化。
该计算表示为运算符的DAG,每个运算符都通过消耗先前生成的或输入的张量来生成张量。可以在调度原语的帮助下执行优化,例如循环切片,循环展开,矢量化等。
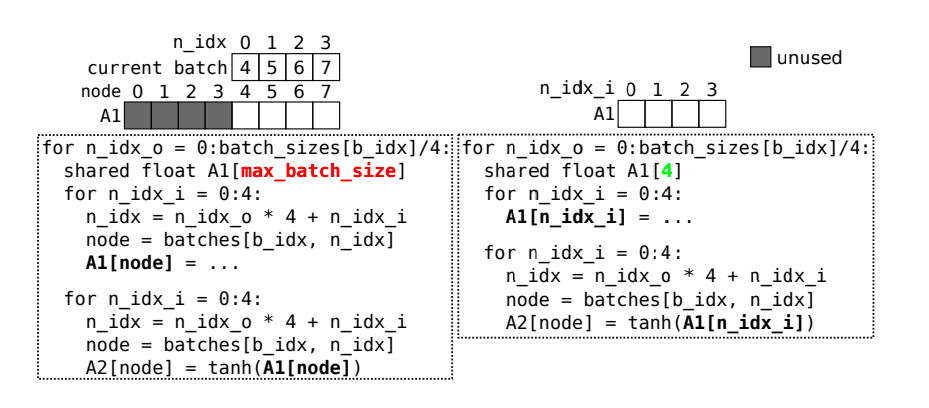
当中间张量存储在暂存器中时,用非仿射表达式索引它会导致张量稀疏。这种稀疏填充的张量会占用过多的内存, 其中A1的一半未使用。
在这种情况下,可以通过循环迭代空间来索引张量。这种转换还通过将间接内存访问转换为仿射访问来降低索引成本。
过去有关机器学习编译器的以及深度学习的工作建议在机器学习模型中支持有效地动态执行是非常必要的。
CORTEX展示了一种行之有效的方法是利用过去在通用编译中的工作,例如检查执行器技术或稀疏的多面体框架。
陈天奇团队认为,像在ILIR中一样,扩大当今使用的高度专业化的机器学习框架和技术的范围也很重要(在不损害其优化静态前馈模型的能力的前提下)。
同时,他们也介绍了团队的未来开发方向:
- 应用这些研究来开发类似的技术来训练和服务具有潜在非递归动态控制流的模型。







