
微博上一些基本的信息都是可以爬取的,当然也有一些没有完善的地方。但是对于微博基本数据需求的朋友应该足够了。这个项目也是支持自己拓展开发的。
具体的使用方法readme中说的挺清楚,这里给大家简单的梳理一下怎么跑起来这个项目。
第一步
pip install -r requirements.txt
第二步
第一次执行:
python3 -m weibo_spider
它会自动产生config.json的配置文件,我们主要的配置信息都在那个文件里。
第三步
{
"user_id_list": ["1866405545"],
"filter": 0,
"since_date": "2019-12-30",
"end_date": "now",
"random_wait_pages": [1, 3],
"random_wait_seconds": [6, 15],
"global_wait": [[100, 10], [500, 2000]],
"write_mode": ["csv", "json"],
"pic_download": 0,
"video_download": 0,
"file_download_timeout": [5, 5, 10],
"result_dir_name": 0,
"cookie": "D",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
},
"kafka_config": {
"bootstrap-server": "127.0.0.1:9092",
"weibo_topics": ["spider_weibo"],
"user_topics": ["spider_weibo"]
},
"sqlite_config": "weibo.db"
}
这些参数的具体含义,大家还是自行去readme中阅读,项目地址我放在了文末。
第四步
python3 -m weibo_spider --config_path="config.json"
执行之后就可以跑起来了。
关于如何拓展该项目,爬到自己想要的数据:
整体的框架已经做得比较完善了。
其中,想拓展爬虫功能,可以在parser的包中进行修改。
其中page_parser.py中是爬虫的一些主要函数,建议大家可以从这个文件开始看起。
我在这个爬虫的基础上也添加了一个爬取热门评论以及热门评论点赞数的功能,大家可以看下我是如何去拓展的。
当然,如果它所爬取的信息已经满足你的需求,那么就没必要自己去加了,加了可能还会报错。
我们还是来看page_parser.py这个文件
def get_one_weibo(self, info):
"""获取一条微博的全部信息"""
try:
weibo = Weibo()
is_original = self.is_original(info)
if (not self.filter) or is_original:
weibo.id = info.xpath('@id')[0][2:]
weibo.content = self.get_weibo_content(info,
is_original) # 微博内容
weibo.article_url = self.get_article_url(info) # 头条文章url
picture_urls = self.get_picture_urls(info, is_original)
weibo.original_p
......
# 省略
从他给的注解以及我们对这个函数进行分析,整体的步骤就是,自己编写一个函数,然后在这里进行调用即可。
通过我们对其他函数的分析,他们的函数参数中都有一个info参数,这个是什么呢?
从下面这个函数,我们可以知道info具体是什么:
def get_one_page(self, weibo_id_list):
"""获取第page页的全部微博"""
try:
info = self.selector.xpath("//div[@class='c']")
is_exist = info[0].xpath("div/span[@class='ctt']")
weibos = []
.......
其实info就是用户微博列表的页面。了解到info是什么,我们就可以对其进行xpath的解析
下面的代码是我对其功能进行的拓展,实际含义就是获取热门评论内容以及点赞数
def get_hot_comment_and_up_num(self,info):
from lxml.html import tostring
from lxml import etree
id = info.xpath('@id')[0][2:]
comment_url = 'https://weibo.cn/comment/'+id
comment = handle_html(self.cookie, str(comment_url))
comment = tostring(comment).decode()
html1 = etree.HTML(comment)
# 获取所有a标签的href属性
comment_hot_text = ''
pattern = r'\d+'
up_num = 0
linklist = html1.xpath('//span[@class="kt"]/../@id')
for i in linklist:
l = html1.xpath('//div[@id="' + i + '"]//span[@class="ctt"]//text()')
l2 = html1.xpath('//div[@id="' + i + '"]')
for j in l2:
text = handle_garbled(j) # 处理乱码
str_footer = text[text.rfind(u'赞'):]
weibo_footer = re.findall(pattern, str_footer, re.M)
up_num += int(weibo_footer[0])
comment_hot_text = comment_hot_text.join(l)
return comment_hot_text, up_num
然后,我们再去之前说的get_one_weibo函数中添加我们写好的函数
不过在此之前,我们还需要做一件事,就是将WeiBo对象的属性进行简单的修改,只需要添加你需要的字段名称就行。
例如我这里新增爬取热门评论以及点赞数,所以我只需要加上
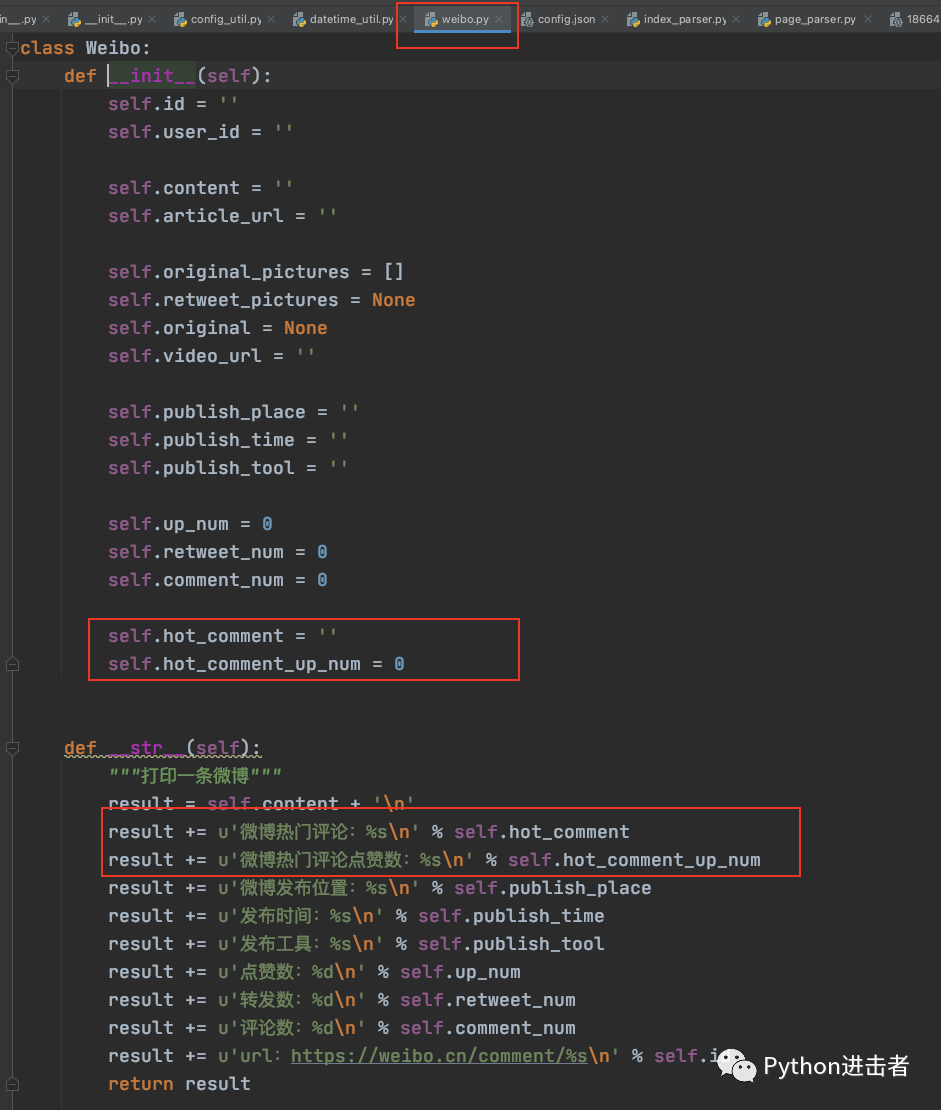
self.hot_comment = ''
self.hot_comment_up_num = 0
项目地址:
https://github.com/dataabc/weiboSpider








