相比之下,机器学习中的神经网络更像是一个数学函数。我们输入一组数据,然后神经网络会给我们返回一个结果。像下面这个简单的函数:
y
=
w
x
+
b
(
w
和
b
是
常
数
)
y = wx + b(w和b是常数)
y
=
w
x
+
b
(
w
和
b
是
常
数
)
我们给定一个x,就能得到一个y。只不过神经网络的函数要比上面的函数复杂得多。
在前言中,我们介绍了一个简单的函数:
y
=
w
x
+
b
y = wx + b
y
=
w
x
+
b
其实它就是线性回归的基础。线性回归算法就是找到一组最优的
w b
,让我们得到最接近真实的结果。我们还是用上面的数据:
1,3,5,7,9
1
1
对于上面这组数据,我们是要找序号和数值之间的关系,我们可以把上面的数据理解为:
x, y
1,12,33,5,4,7,5,9
1
2
3
4
5
6
1
2
3
4
5
6
其中x表示需要,y表示具体的数值。我们稍加运算就可以得到下面这个函数:
y
=
2
x
−
1
y = 2x - 1
y
=
2
x
−
1
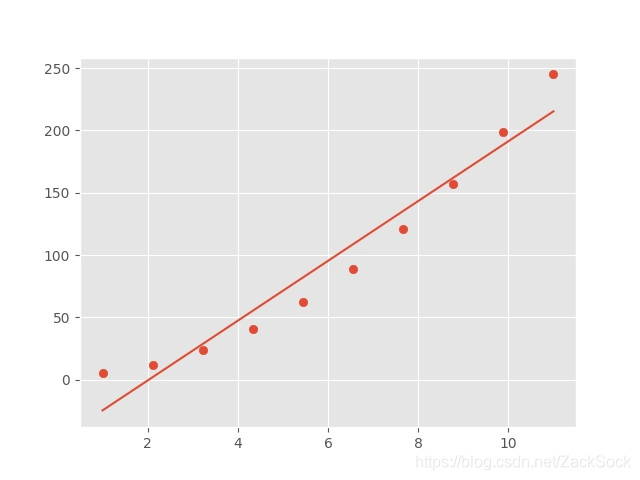
我们得到了最优的一组参数
w=2, b = -1
,通过这个函数我们就可以预测后面后面一千、一万个数字。
不过有时候我们会有多个x,这时我们就可以把上面的函数推广为:
y
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
+
b
y = w_1x_1 + w_2x_2 + ...+w_nx_n + b
y
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
+
b
这时候我们需要求得参数就多多了。下面我们来实际写一个线性回归的程序。
import numpy as np
from sklearn.linear_model import LinearRegression
# 准备x的数据
X = np.array([[1],[2],[3],[4],[5]])# 准备y的数据
y = np.array([1,3,5,7,9])# 创建线性回归模块
lr = LinearRegression()# 填充数据并训练
lr.fit(X, y)# 输出参数print("w=", lr.coef_,"b=", lr.intercept_)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
首先我们需要准备
X
和
y
的数据,这里我们使用的是ndarray数组。这里需要注意,我们
y
的的数据长度为5,则
X
的数据需要是5*n。
准备好数据后我们需要创建线性回归模型,然后调用fit方法填充我们准备好的数据,并训练。
训练完成后我们可以查看一下模块的参数,其中
coef_
表示
w
,而
intercept_
表示
b
。因为
w
可以有多个,所以它应该是个数组,下面是输出结果:
w=[2.] b=-1.0
1
1
和我们人工智慧得到的结果是一样的。我们还可以调用predict方法预测后面的数据:
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1],[2],[3],[4],[5]])
y = np.array([1,3,5,7,9])
lr = LinearRegression()
lr.fit(X, y)
y_predict = lr.predict(np.array([[100]]))print(y_predict)
虽然是个很简单的问题,但是我们还是需要讨论一下。首先我们可以把计算总分的公式写成下面的形式:
y
=
0.4
x
1
+
0.3
x
2
+
0.3
x
3
+
b
y = 0.4x_1 + 0.3x_2 + 0.3x_3 + b
y
=
0
.
4
x
1
+
0
.
3
x
2
+
0
.
3
x
3
+
b
那我们怎么把上面的结果映射到-1和1上呢?这就需要使用一个特殊的函数了,我们把这个函数叫做激活函数。我们可以用下面这个函数作为激活函数:
f
(
x
)
=
y
−
60
∣
y
−
60
∣
f(x) = \frac{y-60}{|y-60|}
f
(
x
)
=
∣
y
−
6
0
∣
y
−
6
0
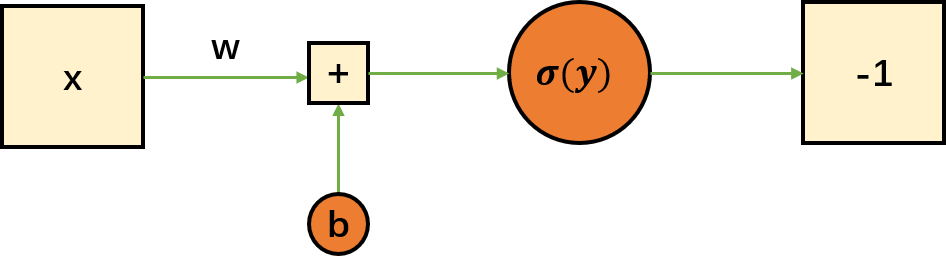
这样就可以把所有分数映射到-1和1上了。(上面的函数在y=60处无定义,严格上来讲上面的激活函数是不适用的)逻辑回归的图示如下: