作者:Gregor Scheithauer博士 翻译:王闯(Chuck) 校对:欧阳锦本文约2000字,建议阅读5分钟
本文介绍了如何在Python/Pandas中运用管道的概念,以使代码更高效易读。

简介
我是R语言的忠实粉丝,并且靠它吃饭。特别提一下Tidyverse,它是一个功能强大、简洁易懂且文档齐全的数据科学平台。我在此向每一位初学者强烈推荐免费的在线电子书R for Data Science。然而,我所在团队使用的编程语言却是Python/Pandas,它也是一个出色的数据科学平台。最大的区别之一(至少对我来说)是如何编写Python代码,这与R代码非常不同——这跟语法没什么直接关系。R语言的众多优点之一是它在编程中引入了管道(pipe)的概念。这会让你的代码更具有效性和可读性。一个范例详见 Soner Yıldırım发表的帖子The Flawless Pipes of Tidyverse。我在这里对照他的帖子,向您展示如何在Pandas中使用管道(也称方法链,method chaining)。什么是管道?
根据R magrittr包文档[1]所述,代码中使用管道的优点如下:下面的代码是一个典型示例。我们将函数调用的结果保存在变量中,如foo_foo_1,这样做的唯一目的就是将其传递到下一个函数调用中,如scoop()。这导致许多变量的命名可能没那么有意义,结果增加了代码的复杂性。 foo_foo_1 foo_foo_2 foo_foo_3
在R语言中使用管道的语法为%>%。它可以使多个函数链接起来使用。在下面的示例中,请尝试以如下方式阅读代码:foo_foo %>% hop(through = forest) %>%
scoop(up = field_mice) %>% bop(on = head)
请注意,数据集是一个名词,而函数是动词。你现在可能理解了为什么说管道增加了代码的可读性。为了更好地理解管道的工作方式,下面给出了解释前的代码版本:bop( scoop( hop(foo_foo, through = forest), up = field_mice ), on = head)
由于Python中没有magrittr包,因此必须另寻他法。在Pandas中,大多数数据框函数都会返回数据集本身,我们将利用这一事实。这被称之为方法链。让我们继续以foo_foo为例。foo_foo_1 = hop(foo_foo, through = forest)foo_foo_2 = scoop(foo_foo_1, up = field_mice)foo_foo_3 = bop(foo_foo_2, on = head)
foo_foo.hop(through = forest).scoop(up = field_mice).bop(on = head)
已经很接近目标了,但还没到。需要做一个小调整,即用小括号()将代码括起来,使其变成我们想要得到的样子。具体样例请查看如下代码:( foo_foo .hop(through = forest) .scoop(up = field_mice) .bop(on = head))
我喜欢这种编程风格。在我看来,引入管道概念可以带来如下优点:1. 使你的代码对于团队中的其他数据科学家(以及你自己以后阅读)而言更具可读性;3. 可以在数据评估过程中快速添加或删除函数功能;4. 让代码遵循你在数据评估和分析过程中的思路(遵循名词-动词范式)。https://magrittr.tidyverse.org/[2] R for Data Science书中的Pipes章:https://r4ds.had.co.nz/pipes.html?q=pipe#pipes
Python中的无缝管道(即方法链)
我将对照SonerYıldırım的文章,让您对比学习如何在R和Python中使用管道/方法链。Soner使用的是Kaggle上的Melbourne housing(墨尔本住房)数据集。你可以下载数据集,并和我一起演练一下。
读取数据集并导入相关包
# import libsimport pandas as pd
# read datamelb = pd.read_csv("../01-data/melb_data.csv")# Have a quick look at the data( melb .head())
图片来自作者
筛选,分组并生成新变量
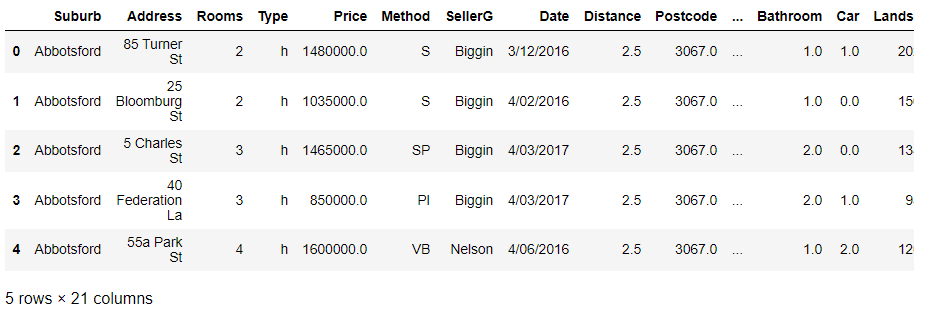
接下来的示例对住房按距离小于2来进行筛选,按照类型进行分组,然后计算每个类型分组的平均价格。然后进行一些格式化。( melb .query("Distance < 2") # query equals filter in Pandas .filter(["Type", "Price"]) # select the columns Type and Price .groupby("Type") .agg("mean") .reset_index() .set_axis(["Type", "averagePrice"], axis = 1, inplace = False))
图片来自作者
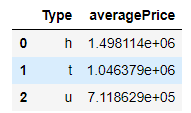
接下来的示例,我们将使用多个条件进行筛选并计算其他特征。请注意,可以使用内置函数agg(用于数据聚合)。就我个人而言,我通常会将assign与lambda结合使用。代码和运行结果如下。( melb .query("Distance < 2 & Rooms > 2") .filter(["Type", "Price"]) .groupby("Type") .agg(["mean", "count"]) .reset_index() .set_axis(["Type", "averagePrice", "numberOfHouses"], axis = 1, inplace = False) .assign(averagePriceRounded = lambda x: x["averagePrice"].round(1)))
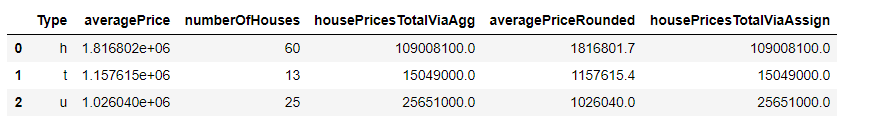
图片来自作者
排序
下一个示例展示了如何对不同区域(仅指以字符串South开头的区域)的住房按照平均距离来进行排序。( melb .
query('Regionname.str.startswith("South")', engine = 'python') .filter(["Type", "Regionname", "Distance"]) .groupby(["Regionname", "Type"]) .agg(["mean"]) .reset_index() .set_axis(["Regionname", "Type", "averageDistance"], axis = 1, inplace = False) .sort_values(by = ['averageDistance'], ascending = False))
图片来自作者
为不同区域的平均距离绘制条形图
管道概念的妙处是,它不仅可以用于评估或处理数据,也可以与绘图一起使用。我个人强烈推荐绘图库plotnine - 它是Python图形语法的一个很好的实现,某种程度上说是R语言中ggplot2 包的翻版。你可以在Medium上找到更多有关plotenine的文章。不过,如果只是想先粗略地看一下数据,Pandas plot功能则非常值得一试。( melb #.query('Regionname.str.startswith("South")', engine = 'python')
.filter(["Regionname", "Distance"]) .groupby(["Regionname"]) .agg(["mean"]) .reset_index() .set_axis(["Regionname", "averageDistance"],axis = 1, inplace = False) .set_index("Regionname") .sort_values(by = ['averageDistance'], ascending = False) .plot(kind = "bar"))
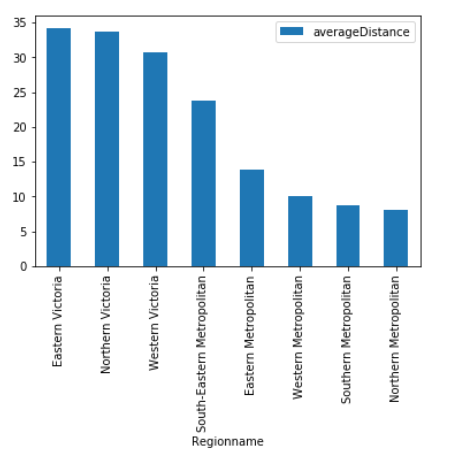
图片来自作者
使用直方图绘制价格分布
( melb .Price # getting one specific variable .hist())
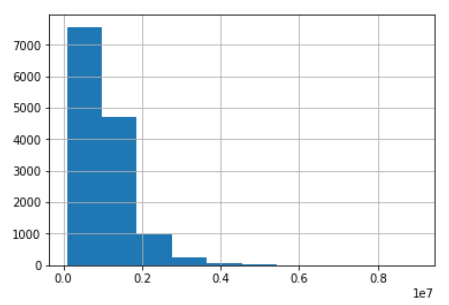
图片来自作者
结语
在本文中,我鼓励大家在Python代码中使用类似R语言中的管道和方法链,以提高代码可读性和效率。我重点介绍了管道的一些优点,然后我们将这一概念应用于住房数据。我特别展示了如何进行数据读取,数据筛选和分组,计算新变量以及如何绘图。我再次安利下plotnine包,它能帮你得到更好的可视化效果。The Flawless Pipes of Python/Pandashttps://towardsdatascience.com/the-flawless-pipes-of-python-pandas-30f3ee4dffc2参考资料
Melbourne Housing Snapshot | Kaggle:https://www.kaggle.com/dansbecker/melbourne-housing-snapshot
Tidyverse:https://www.tidyverse.org/
The Flawless Pipes of Tidyverse. Exploratory data analysis made easy | by Soner Yıldırım | Mar, 2021 | Towards Data Science:ttps://towardsdatascience.com/the-flawless-pipes-of-tidyverse-bb2ab3c5399f
Welcome | R for Data Science (had.co.nz):https://r4ds.had.co.nz/
18 Pipes | R for Data Science (had.co.nz):https://r4ds.had.co.nz/pipes.html?q=pipe#pipes
Data visualization in Python like in R’s ggplot2 | by Dr. Gregor Scheithauer | Medium:https://gscheithauer.medium.com/data-visualization-in-python-like-in-rs-ggplot2-bc62f8debbf5
译者简介:王闯(Chuck),台湾清华大学资讯工程硕士。曾任奥浦诺管理咨询公司数据分析主管,现任尼尔森市场研究公司数据科学经理。很荣幸有机会通过数据派THU微信公众平台和各位老师、同学以及同行前辈们交流学习。
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。










