-- 创建一个测试表CREATETABLE`app_user`(`id`BIGINT(20)UNSIGNEDNOTNULLAUTO_INCREMENT,`name`VARCHAR(50)DEFAULT''COMMENT'用户昵称',`email`VARCHAR(50)NOTNULLCOMMENT'用户邮箱',`
phone`VARCHAR(20)DEFAULT''COMMENT'手机号',`gender`TINYINT(4)UNSIGNEDDEFAULT'0'COMMENT'性别(0:男;1:女)',`password`VARCHAR(100)NOTNULLCOMMENT'密码',`age`TINYINT(4)DEFAULT'0'COMMENT'年龄',`create_time`DATETIMEDEFAULTCURRENT_TIMESTAMP,`update_time`TIMESTAMPNOTNULLDEFAULTCURRENT_TIMESTAMPONUPDATECURRENT_TIMESTAMP,PRIMARYKEY(`id`))ENGINE=INNODBDEFAULTCHARSET=utf8 COMMENT='app用户表'-- 5.7版本代码
第一个语句 delimiter 将 mysql 解释器命令行的结束符由”;” 改成了”$$”,
让存储过程内的命令遇到”;” 不执行
DROPFUNCTIONIFEXISTS mock_data;DELIMITER $$
CREATEFUNCTION mock_data()RETURNSINTDETERMINISTICBEGINDECLARE num INTDEFAULT1000000;DECLARE i INTDEFAULT0;WHILE i < num DOINSERTINTO app_user(`name`,`email`,`phone`,`gender`,`password`,`age`)VALUES(CONCAT('用户',i),'24736743@qq.com',CONCAT('18',FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*2),UUID(),FLOOR(RAND()*100));SET i = i +1;ENDWHILE;RETURN i;END $$
SELECT mock_data()$$
+-------------+| mock_data()|+-------------+|1000000|+-------------+1rowinset(16.59 sec)-- 8.0.18版本代码DROPFUNCTIONIFEXISTS mock_data;-- 写函数之前必须要写,标志:$$DELIMITER $$
CREATEFUNCTION mock_data()RETURNSINT-- 注意returns,否则报错。DETERMINISTIC-- 8.0版本需要多这么一行BEGINDECLARE num INTDEFAULT1000000;-- num 作为截止数字,定义为百万,DECLARE i INTDEFAULT0;
WHILE i < num DOINSERTINTO app_user(`name`,`email`,`phone`,`gender`,`password`,`age`)VALUES(CONCAT('用户', i),'965499224@qq.com', CONCAT('13', FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*2),UUID(), FLOOR(RAND()*100));SET i = i +1;ENDWHILE;RETURN i;END;SELECT mock_data();-- 总耗时 : 41.436 sec
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
创建索引
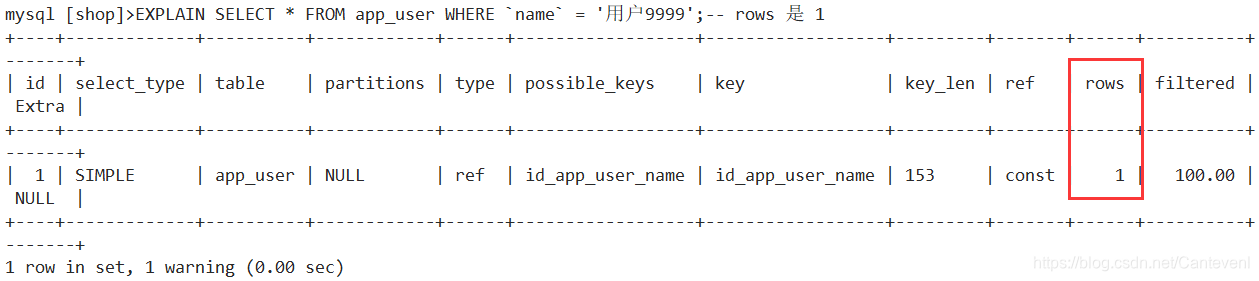
SELECT*FROM app_user WHERE`name`='用户9999';1rowinset(0.33
sec)SELECT*FROM app_user WHERE`name`='用户999999';1rowinset(0.31 sec)EXPLAINSELECT*FROM app_user WHERE`name`='用户9999';-- 创建一个索引-- id _ 表名 _ 字段名-- create index 索引名 on 表(字段)CREATEINDEX id_app_user_name ON app_user(`name`);SELECT*FROM app_user WHERE`name`='用户9999';1rowinset(0.00 sec)SELECT*FROM app_user WHERE`name`='用户999999';1rowinset(0.00 sec)EXPLAINSELECT*FROM app_user WHERE`name`='用户9999';-- 只查了1条数据 直接查到数据-- rows 是 1-- 删除索引对象:-- drop index 索引名 on 表名;