我们分别在R和python中构建一个数据框,用1到9进行填充,有3列,对应a,b,c
R代码如下
mat = matrix(1:9, nrow = 3, ncol = 3,byrow = TRUE)
df = as.data.frame(mat)
colnames(df) "a","b","c")
Python代码如下
import numpy as np
import pandas as pd
mat = np.array(range(1,10))
mat = mat.reshape(3,3)
df = pd.DataFrame(mat, columns=['a','b','c'])
在R语言中,我们可以直接用df$a > 2 & df$c > 3获取一组逻辑值,然后用逻辑值进行过滤
df[df$a > 2 & df$c > 3,]
但是在Python中,类似的代码却会报错
df.loc[df.a > 2 & df.b > 3, :]
# 报错信息
# ValueError: The truth value of a Series is ambiguous.
# Use a.empty, a.bool(), a.item(), a.any() or a.all().
看起来完全一样的代码,逻辑也似乎没啥问题,为什么会有不同的结果呢?
这其实是R和Python在运算符的优先级上的差异所引起的。在R里面里面,比较运算符的优先级是高于and的优先级。
在Python中&的位'AND'优先级高于比较运算符,也就是说 df.a > 2 & df.b > 3的是先求 2&df.b 而非我们预期的 先获取df.a > 2 与df.b >3的逻辑运算结果,然后按位对两个结果再进行比较。换言之,我们需要给df.a > 2和 df.b >3先套上括号,提高它们的运算优先级才行。
df.loc[(df.a > 2 )& (df.b > 3), :]
最后附上Python和R的运算符号优先级(operator precedence)
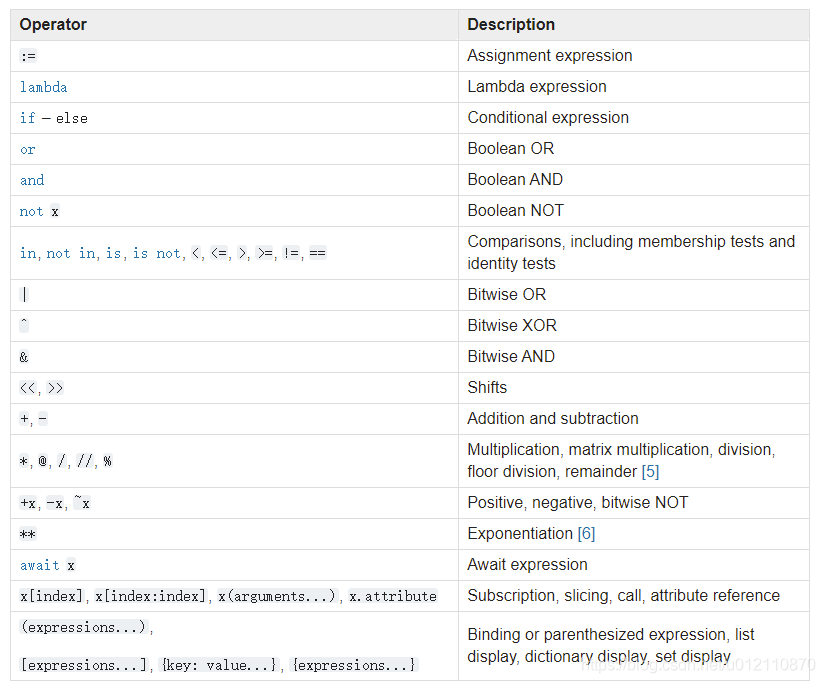 来源: https://docs.python.org/3/reference/expressions.html#operator-precedence
来源: https://docs.python.org/3/reference/expressions.html#operator-precedence

来源R的帮助文档 ?Syntax
题图来源: https://www.datacamp.com/community/blog/when-to-use-python-or-r







