

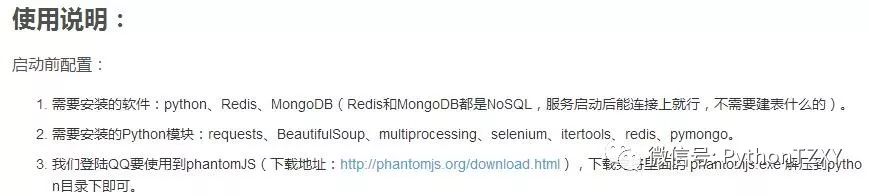
使用说明:
启动前配置:
MongoDB安装好 能启动即可,不需要配置。

启动程序:
进入 myQQ.txt 写入QQ账号和密码(用一个空格隔开,不同QQ换行输入),一般你开启几个QQ爬虫线程,就至少需要两倍数量的QQ用来登录,至少要轮着登录嘛。
进入 init_messages.py 进行爬虫参数的配置,例如线程数量的多少、设置爬哪个时间段的日志,哪个时间段的说说,爬多少个说说备份一次等等。
运行 init.py 文件开启爬虫项目。
爬虫开始之后首先根据 myQQ.txt 里面的QQ去获取 Cookie(以后登录的时候直接用已有的Cookie,就不需要每次都去拿Cookie了,遇到Cookie失效也会自动作相应的处理)。获取完Cookie后爬虫程序会去申请四百多兆的内存,申请的时候会占用两G左右的内存,大约五秒能完成申请,之后会掉回四百多M。
爬虫程序可以中途停止,下次可打开继续抓取。
一个人自学很有可能因为动力不足而中途放弃,可以尝试加入一个或几个适合自己的网络群体(QQ、 微信、 社区等),寻找志同道合的学习伙伴,相互交流、相互促进.如果大家想要学习交流欢迎给我私信,私信关键词: 01.02.03.04 都会得到不一样的资料!系统坚持到关键词会自动发送。分开发送!01或者02
运行截图:
说说数据:
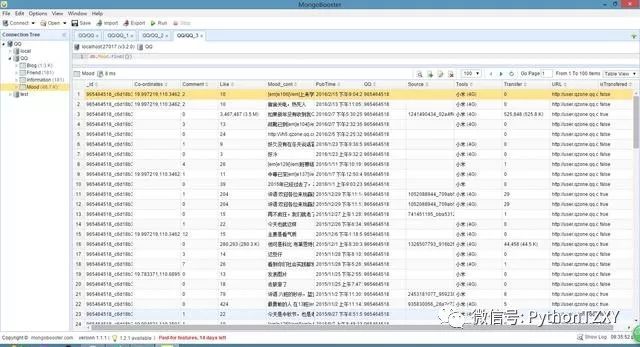
日志数据:
好友关系数据:
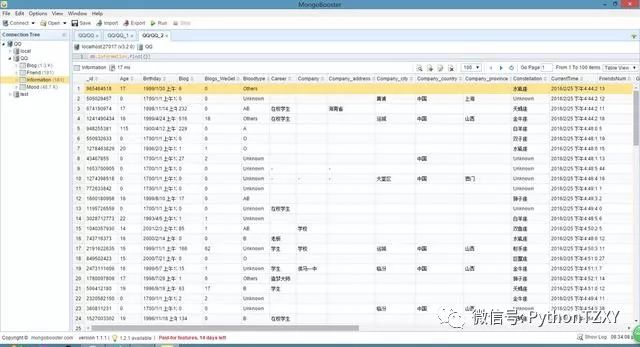
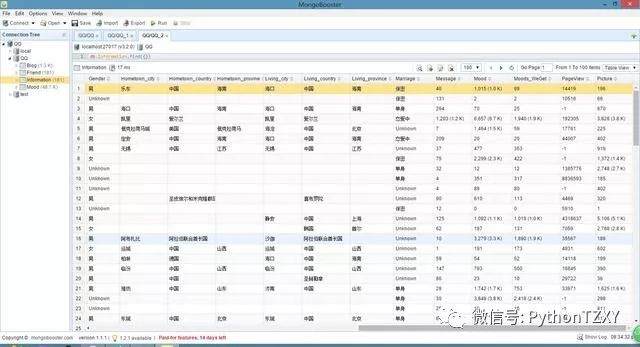
个人信息数据:




Friend 表:
_id:采用 QQ 作为唯一标识。
Num:此QQ的好友数(仅统计已抓取到的)。
Fx:朋友的QQ号,x代表第几位好友,x从1开始逐渐迭加。

启动程序:
进入 myQQ.txt 写入QQ账号和密码(不同QQ换行输入,账号密码空格隔开)。如果你只是测试一下,则放三两个QQ足矣;但如果你开多线程大规模抓取的话就要用多一点QQ号(thread_num_QQ的2~10倍),账号少容易被检测为异常行为。
进入 init_messages.py 进行爬虫参数的配置,例如线程数量的多少、设置爬哪个时间段的日志,哪个时间段的说说,爬多少个说说备份一次等等。
运行 launch.py 启动爬虫。



此文还是有些许难度的!零基础不宜上手!










