本文你将会了解到
1、如何使用PyTorch对数据集进行导入
2、如何使用PyTorch搭建一个简易的深度学习模型
3、如何优化和训练我们搭建好的模型
注:本案例使用的PyTorch为0.4版本
简介
Pytorch是目前非常流行的深度学习框架,因为它具备了Python的特性所以极易上手和使用,同时又兼具了NumPy的特性,因此在性能上也并不逊于任何一款深度学习框架。现在PyTorch又和Caffe2进行了融合,在今年暑期整和了Caffe2的PyTorch1.0版本将受到更多专业人士的关注和重视。下面我们通过使用PyTorch实现一个手写数字识别的模型来简单的入门一下PyTorch。
如何使用PyTorch对数据集进行导入
在进行数据导入之前我们需要先导入一些在之后需要用的包,代码如下:
import torch
import torchvision
from torch.
autograd import Variable
from torchvision import transforms,datasets
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
手写数字的数据集我们可以使用PyTorch中自带的torchvision.datasets方法进行下载。另外这个方法还可以方便的下载COCO,ImageNet,CIFCAR等常用的数据集。代码如下:
transform = transforms.ToTensor() train_dataset = datasets.MNIST(root =
"./data",
train = True,
transform = transform,
download = True)
test_dataset = datasets.MNIST(root = "./data",
train = False,
transform = transform,
download = True)
train_data_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size=64,
shuffle = True)
test_data_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=64,
shuffle = True)
通过这几段代码我们就实现了数据的载入和装载。其中batch_size指定我们每次装载的数据个数,这里使用的值是64即我们每次装载到模型中的图片个数是64张。shuffle设置为True表明我们装载到模型中的输入数据是被随机打乱顺序的。
如何使用PyTorch搭建一个简易的深度学习模型
定义好了数据载入和装载的方法之后,我们就可以开始搭建深度学习模型,这里使用卷积层、最大池化层和全连接层来搭建一个简易的卷积神经网络模型,代码如下:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.Conv=torch.nn.Sequential(
torch.nn.Conv2d(1,28,kernel_size=3,padding=1,stride=1),
torch.nn.Conv2d(28,64,kernel_size=3,padding=1,stride=
1), torch.nn.MaxPool2d(kernel_size=2, stride=2), torch.nn.Conv2d(64,64,kernel_size=3,padding=1,stride=1), torch.nn.Conv2d(64,64,kernel_size=3,padding=1,stride=1), torch
.nn.MaxPool2d(kernel_size=2, stride=2)
)
self.Dense = torch.nn.Linear(7*7*64, 10)
def forward(self, input):
x =
self.Conv(input)
x = x.view(-1, 7*7*64)
x = self.Dense(x)
return x ```
模型使用的是4层卷积、2层池化和1层全连接的卷积神经网络结构。虽然结构简单,但是对于处理手写数字识别问题这个模型已经绰绰有余了。搭建好模型之后我们可以对模型进行打印输出,查看具体的模型细节,如下:
model = Model()
model =
model.cuda()
print(model)
输出的结果为:
Model(
(Conv): Sequential(
(0): Conv2d(1, 28, kernel_size=(3, 3), stride=(1, 1), padding=(1
, 1))
(1): Conv2d(28, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): MaxPool2d(kernel_size=2, stride=2, padding=0
, dilation=1, ceil_mode=False)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(64, 64, kernel_size
=(3, 3), stride=(1, 1), padding=(1, 1))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(Dense
): Linear(in_features=3136, out_features=10, bias=True)
)
如何优化和训练我们搭建好的模型
模型已经搭建好了,数据的装载方式也已经完成了定义,下面就差最后一步了,对我们的模型进行训练并优化模型内部的参数。代码如下:
epoch_n = 5
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters
(), lr=0.001)
for epoch in range(epoch_n):
epoch_loss = 0.0
epoch_acc = 0.0
for batch in train_data_loader:
X_train,y_train = batch
X_train,y_train=
Variable(X_train.cuda()),Variable(y_train.cuda())
y_pred = model(X_train)
_,pred =torch.max(y_pred, 1)
optimizer.zero_grad()
loss = loss_f(y_pred, y_train)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += torch.sum(pred == y_train.data)
epoch_loss = epoch_loss*64/len(train_dataset)
epoch_acc = epoch_acc.double()/len(train_dataset)
print("Epoch{}: Loss is:{:.4f},Acc is:{:4f}".format(epoch, epoch_loss, epoch_acc))
我们定义了5次训练,所以在整个训练过程中会进行5次后向传播对模型的参数进行更新,其中定义的优化函数是Adam方法,损失函数是CrossEntropyLoss(交叉熵损失)。我们来看训练过程中输出的结果,如下所示:
Epoch0: Loss is:0.1550,Acc is:0.953250
Epoch1: Loss is:0.0663,
Acc is:0.979433
Epoch2: Loss is:0.0525,Acc is:0.984133
Epoch3: Loss is:0.0462,Acc is:0.985567
Epoch4: Loss is:0.0386,Acc is:0.987950
从结果上非常不错了,训练的准确率已经逼近了99%,而且还有上升的趋势,如果继续进行训练还能有更好的表现,不过也有可能会有过拟合的风险。下面我们使用测试集来验证模型对手写数字识别的效果如何。 随机抽取64张测试集的图片,它们的真实标签和图片显示如下:
[ 7, 4, 0, 3, 3, 8, 9, 7, 9, 1, 6, 0, 4, 4,
3, 6, 2, 3,
7, 1, 6, 0, 6, 5, 9, 9, 8, 7,
9, 7, 6, 7, 8, 6, 6, 9, 4, 9,
3, 6, 1, 3,
5, 7, 6, 2, 7, 8, 8, 9, 8, 3, 0, 1, 1, 2,
8
, 8, 5, 3, 3, 1, 1, 4]

我们训练好的模型预测结果如下:
[ 7, 4, 0, 3, 3, 8, 9, 7, 9, 1,
6, 0, 4, 4,
3, 6, 2, 3, 7, 1, 6, 0, 6, 5, 9, 9, 8, 7,
9, 7, 6, 9, 8, 6, 6, 9, 4, 9, 3, 6, 1, 3,
5, 7, 6, 2, 7, 8,
8, 9, 8, 3, 0, 1, 1, 2,
8, 8, 5, 3, 3, 1, 1, 4]
可以看到预测的结果中只出现了一个错误,总体来说这组测试数据的准确率仍然高达98%以上。完整的测试部分代码如下:
X_test,y_test =
next(iter(test_data_loader))
print("Test dataset label is:{}".format(y_test))
X = torchvision.utils.make_grid(X_test)
X = X.numpy().transpose(1,2,0)
plt.imshow(X)
X_test = X_test.cuda()
y = model(X_test)
_,y = torch.max(y,1)
print(y)
本文介绍的只是一个简单的小案例,整个过程基于PyTorch进行完成非常的简单。当然面对较为复杂的问题我们依然可以遵循这三个步骤来搭建出我们基础的模型。
本文作者:唐进民(Guilin Tang),Python中文社区专栏作者。《深度学习之PyTorch实战计算机视觉》图书作者,知乎专栏地址:https://zhuanlan.zhihu.com/c_135203221
赞赏作者

最近热门文章
用Python更加了解微信好友
如何用Python做一个骚气的程序员
用Python爬取陈奕迅新歌《我们》10万条评论的新发现
用Python分析苹果公司股价数据
Python自然语言处理分析倚天屠龙记
百度AI开发者免费实战营深圳站(主会场)
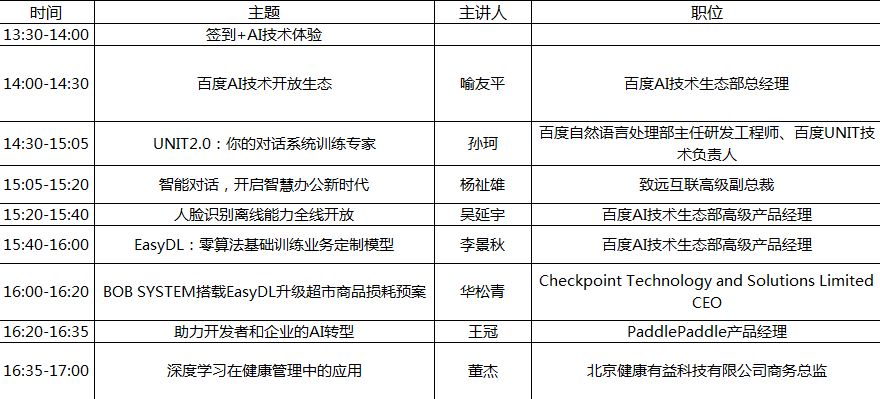
活动时间:2018年5月11日 13:30-17:00
活动地点:深圳科兴科学园国际会议中心三层
活动地址:广东省深圳市南山区科苑路15号科兴科学园B4座3层
▼ 长按扫描下方二维码或者点击
阅读原文报名!








