👇点击关注公众号👇
第一时间获取人工智能干货内容
本篇文章带大家实现K-Means算法。
首先,导入鸢尾花数据集:
from sklearn.datasets import load_iris
iris = load_iris()
导入K-Means模型并进行聚类操作:
from sklearn.cluster import KMeans
#?KMeans
kmeans = KMeans(n_clusters = 3, init = 'k-means++', random_state = 123)#k=3
#init = 'k-means++' 一种可以避免选择较差起始点的方法
y_kmeans = kmeans.fit_predict(iris.data)#产生结果
其中:
n_clusters = 3 代表聚类为3类
init = 'k-means++' 代表一种可以避免选择较差起始点的方法
查看聚类结果:
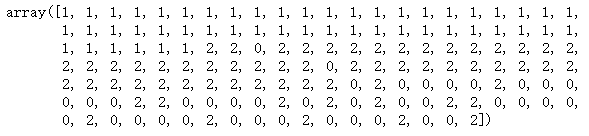
一样的数字代表聚为一类。
将3种鸢尾花的聚类结果可视化(这里选择花瓣长度和宽度作为特征可视化):
import matplotlib.pyplot as plt
%matplotlib inline
#将聚类结果显示
plt.scatter(iris.data[y_kmeans == 0, 2], iris.data[y_kmeans == 0, 3], s = 100, c = 'red', label = 'Cluster 1')
#[y_kmeans == 0, 2], 花瓣长度在第3的栏位,所以是2,花瓣宽度是第4栏位,所以是3,s = 100是点的大小
plt.scatter(iris.data[y_kmeans == 1, 2], iris.data[y_kmeans == 1, 3], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(iris.data[y_kmeans == 2, 2], iris.data[y_kmeans == 2, 3], s = 100, c = 'green', label = 'Cluster 3')
plt.title('Clusters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()
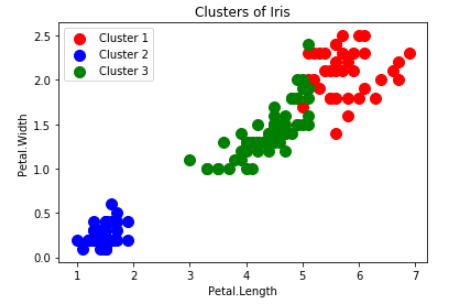
输出4个特征聚类结果的中心点:
kmeans.cluster_centers_ #下面是 三种的 花萼长的中心点,花萼宽的中心点,花瓣长的中心点,花瓣宽的中心点

将聚类中心点打印在图中:
plt.scatter(iris.data[y_kmeans == 0, 2], iris.data[y_kmeans == 0, 3], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(iris.data[y_kmeans == 1, 2], iris.data[y_kmeans == 1, 3], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(iris.data[y_kmeans == 2, 2], iris.data[y_kmeans == 2, 3], s = 100, c = 'green', label = 'Cluster 3')
#绘制中心点
plt.scatter(kmeans.cluster_centers_[:, 2], kmeans.cluster_centers_[:, 3], s = 100, c = 'black', label = 'Centroids')#花瓣长和花瓣宽
plt.title('Clusters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()
接下来看个客户属性聚类的案例
读取并查看数据
import pandas as pd
#dataset = pandas.read_csv(r'D:\机器学习第二天\customers.csv')
f = open(r'D:\机器学习数据第二天\customers.csv')
dataset = pd.read_csv(f)
dataset.head()
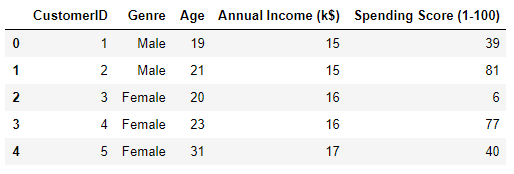
从上面图中发现,包含顾客ID、性别、年龄、年收入、消费能力等5个特征。
考虑将年收入与消费能力作为聚类特征依据:
X = dataset.iloc[:, [3, 4]].values#全部行,第四第五列 Annual Income (k$) 和 Spending Score (1-100)
#X
#考虑最后两栏作为分群依据
开始聚类:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 5, init = 'k-means++', random_state = 42)#k=5
y_kmeans = kmeans.fit_predict(X)
#y_kmeans
输出聚类结果可视化:
#标记 中心
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s = 100, c = 'red', label = 'Standard')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s = 100, c = 'blue', label = 'Traditional')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s = 100, c = 'green', label = 'Normal')
plt.scatter(X[y_kmeans == 3, 0], X[y_kmeans == 3, 1], s = 100
, c = 'cyan', label = 'Youth')
plt.scatter(X[y_kmeans == 4, 0], X[y_kmeans == 4, 1], s = 100, c = 'magenta', label = 'TA')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'black', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
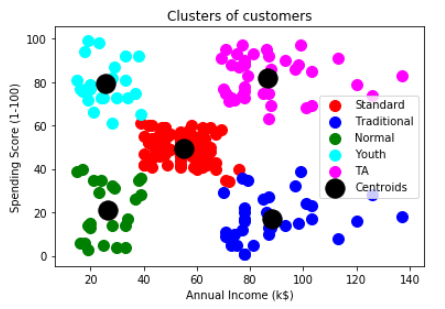
如果你仔细观察,发现之前的聚类个数选择为5个,聚类个数可以通过肘方法实现选择。
#肘方法
import matplotlib.pyplot as plt
wcss = []
for i in range(1, 11): #循环使用不同k测试结果
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
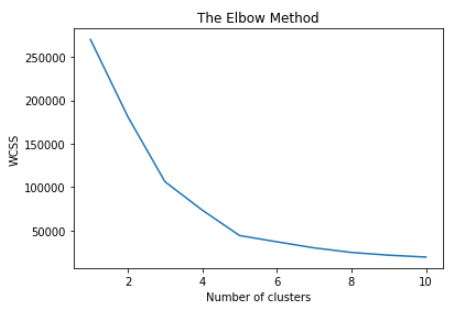
通过观察以上肘方法得到的图,选择5个聚类类别比较合适!
这就是K-Means聚类的案例实现了,你学会了么?







