
今天,继续给各位数据粉带来的是参加过CDA 认证 LEVEL II 课程培训的学员比较熟悉的一个经典数据挖掘应用案例——金融常见信用评分卡的开发解析。
为更全面深入的呈现案例全貌,我们将分3个篇幅展开(层层递进,不容错过!)
· 信用评分卡的应用场景、概述及本案背景(👈🏻点击查看往期内容)
· 信用评分卡如何做数据收集 (👈🏻点击查看往期内容)
· 信用评分卡的模型构建(附全码)
废话不多说,码上开始~
Python金融信用评分卡案例 ——评分卡模型构建
相信经过上面两篇信用评分卡的相关介绍,你已经摩拳擦掌的准备大干一场了。
不要急,超级干货码上来!
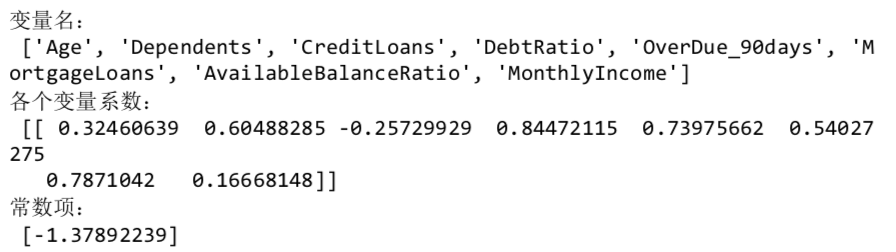
逻辑回归建模

模型评估
模型的评价指标一般有 Gini 系数、K-S 值和 AUC 值,基本上都是基于评分卡分数
的。但是从理论上评分分数是依据预测为正样本的概率计算而得,因此基于这个概
率计算的指标也是成立的。
下面我们用 sklearn 库中的函数计算模型的 AUC 值和 K-S 值,以此初步判断模型
的优劣。
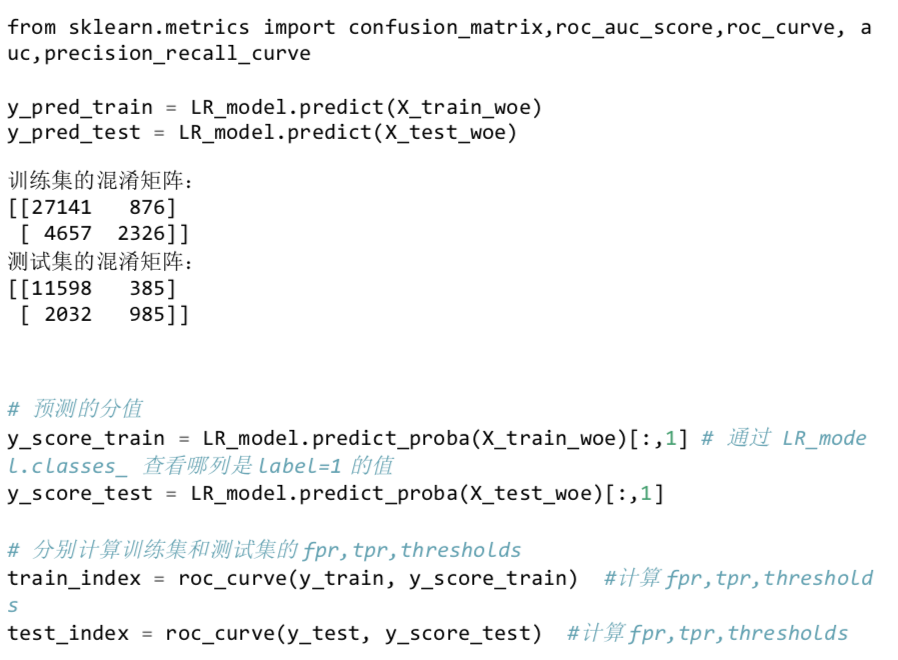
AUC 值
ROC 曲线是以在所有可能的截断点分数下,计算出来的对评分模型的误授率(误
授率表示模型将违约客户误评为好客户,进行授信业务的比率)和 1-误拒率(误
拒率表示模型将正常客户误评为坏客户,拒绝其授信业务的比率)的数量所绘制而
成的,AUC 值为 ROC 曲线下方的总面积。

我们再绘制训练集的 ROC 曲线与测试集的 ROC 曲线。
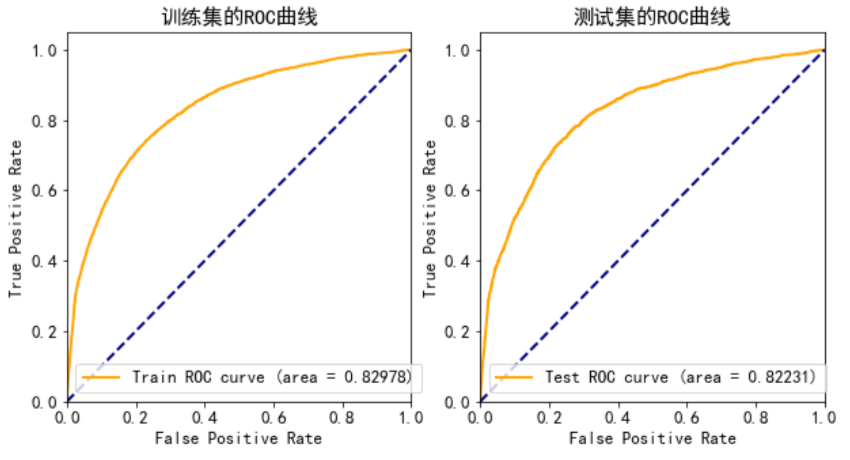
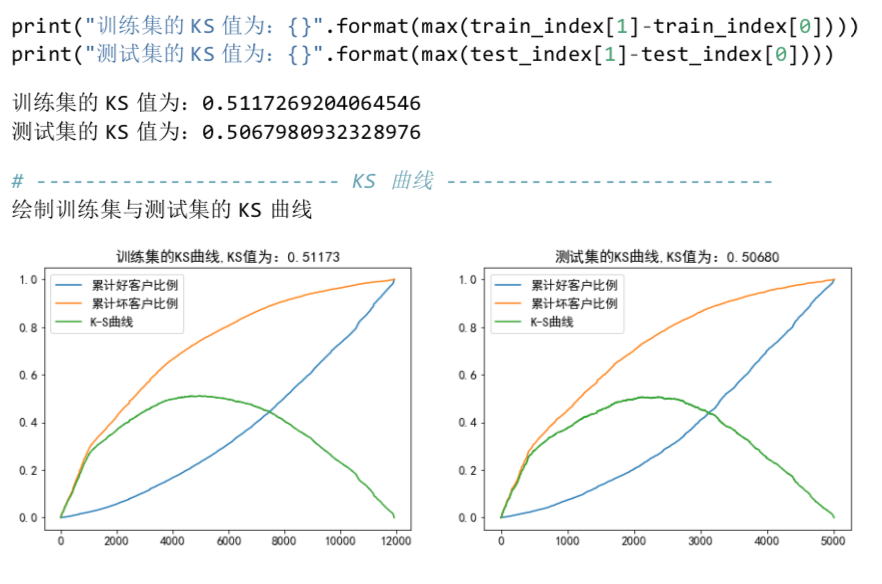
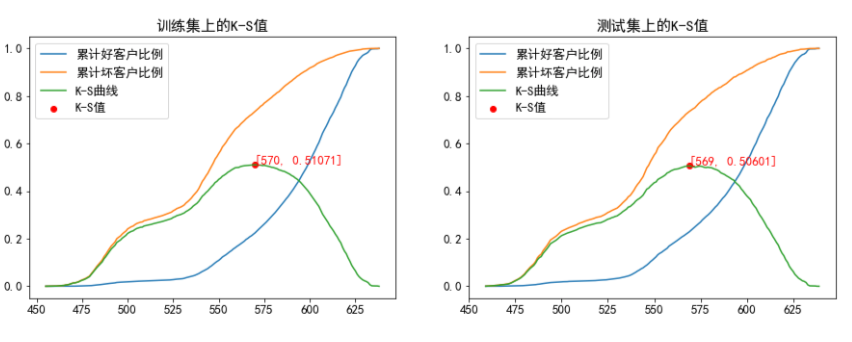
KS 曲线
K-S 测试图用来评估评分卡在哪个评分区间能够将正常客户与违约客户分开。根据各评分分数下好坏客户的累计占比,就可完成 K-S 测试图。
需要注意的是实际业务中数据需要这样准备:模型开发前,我们一般会将数据分为:训练集 train、测试集 test、跨时间数据 OOT(train 和 test 是同一时间段数据,一般三七分,oot 是不同时间段的数据,用来验证模型是否适用未来场景)通过这样的技术保证模型最终可靠稳定。
生成评分卡

基于评分的 KS 值
绘制结果如下:
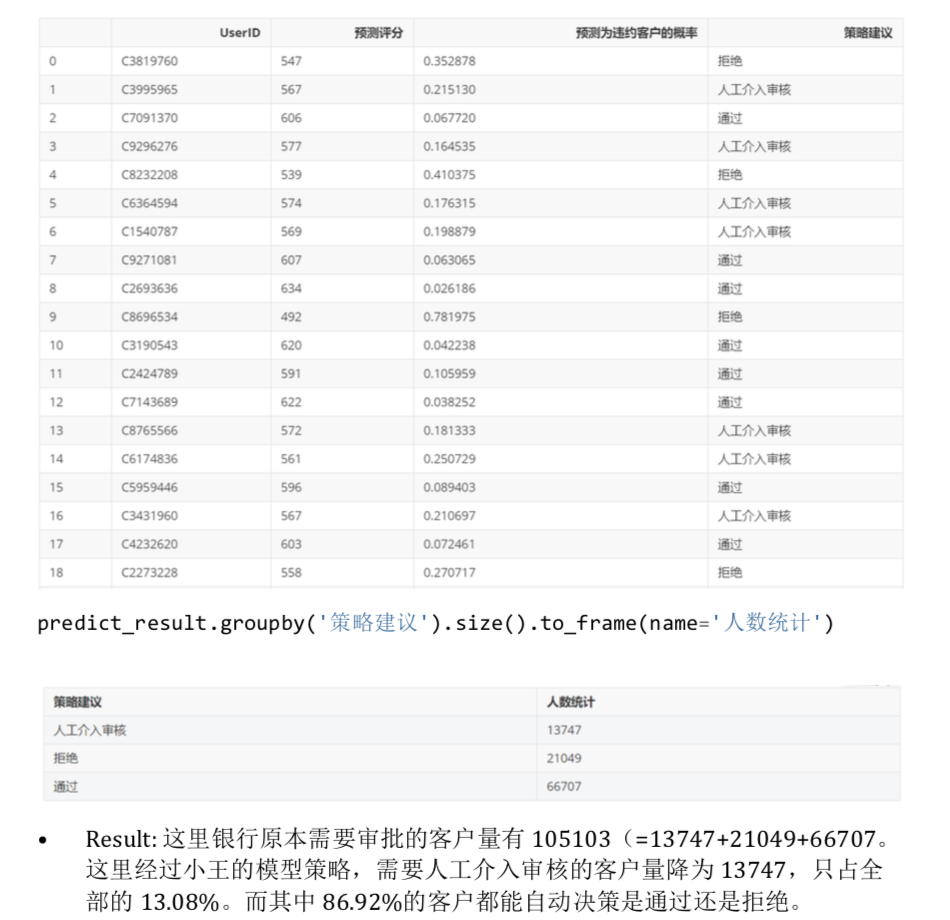
策略建议
由训练集的 KS 值可知,570 分是好坏样本的最佳分隔点。测试集对其进行验证,KS 值为 569,基本一致。因此我们可在训练集的 KS 值上下 10 分内可做如下策略:
以上只是我们给出的策略建议,实际问题和需求远比这里复杂,风控人员可以根据
具体业务需求给出更加贴合实际业务的策略建议。
新数据的预测


结束语
至此,我们已经用 python 实现了一个申请评分卡的开发过程,并在结尾给出了策略建议。数据化后的风控极大提高了银行的审批效率,这是传统的人工审核不可比
拟的,也正是大数据时代带给我们的便利。
另外需要注意的是,在实际中,模型上线还需要持续追踪模型的表现。
一般是每个月月初给全量客户打分,并生成前端和后端监控报告。
由于篇幅的原因,在此不做详述,有兴趣的读者可做相关查阅。
以下是福利区


点这里👇关注我,记得标星哦~











