
今天,继续给各位数据粉带来的是参加过CDA 认证 LEVEL II 课程培训的学员比较熟悉的一个经典数据挖掘应用案例——金融常见信用评分卡的开发解析。
为更全面深入的呈现案例全貌,我们将分3个篇幅展开(层层递进,不容错过!)
· 信用评分卡的应用场景、概述及本案背景(👈🏻点击查看往期内容)
· 信用评分卡如何做数据收集
· 信用评分卡的模型构建(附全码)
废话不多说,码上开始~
Python金融信用评分卡案例 ——数据准备工作
上篇我们介绍了评分卡的基本理论知识,接下来我们要做评分卡建模中很重要的工作,数据准备工作。
导入相关依赖模块

数据探索

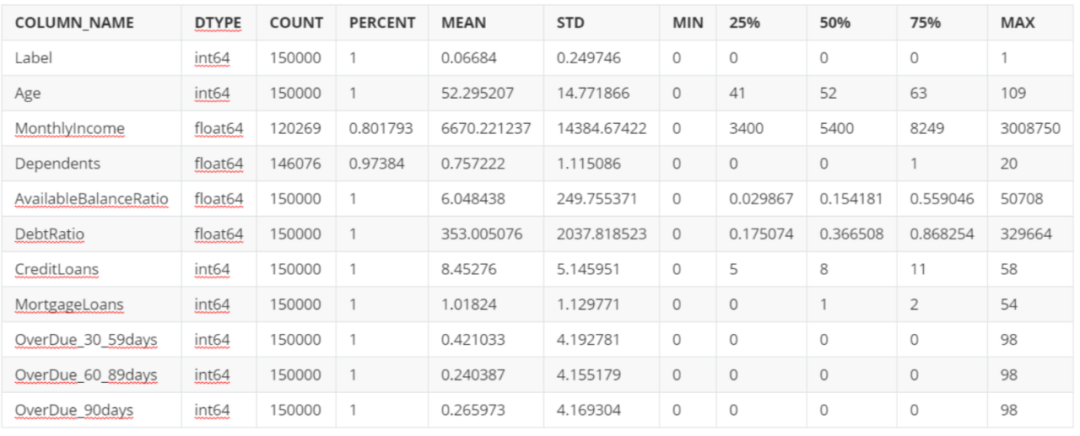
数据准备


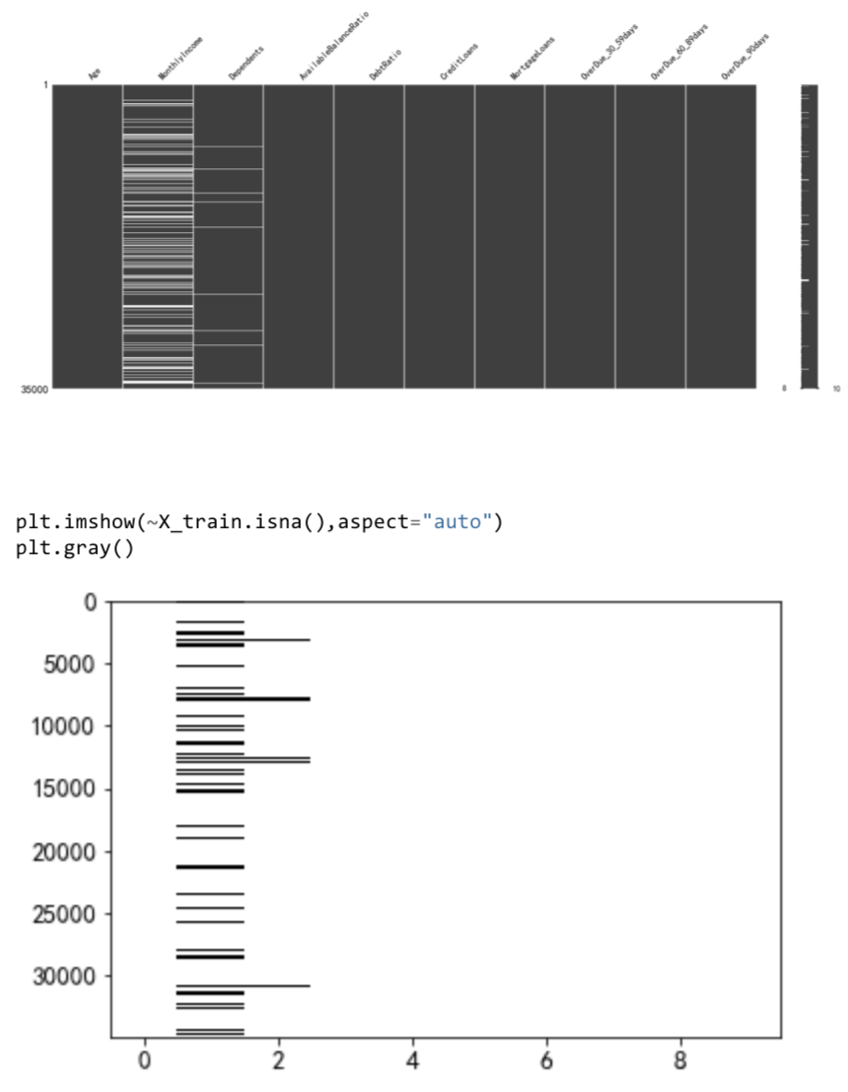
缺失值处理的常用方法:
缺失值处理方法的选择,主要依据是业务逻辑和缺失值占比,在对预测结果的影响尽
可能小的情况下,对缺失值进行处理以满足算法需求,所以要理解每个缺失值处理方
法带来的影响,下面的缺失值处理方法没有特殊说明均是对特征(列)的处理:

本数据的缺失值处理逻辑:
对于信用评分卡来说,由于所有变量都需要分箱,故这里缺失值作为单独的箱子
即可
对于最后一列 Dependents,缺失值占比只有 2.56%,作为单独的箱子信息不够,故
做单一值填补,这列表示家庭人口数,有右偏的倾向,且属于计数的数据,故使用中
位数填补
这里没必要进行多重插补,下面的多重插补只是为了让读者熟悉此操作

异常值处理
异常值处理的常用方法:
1. 删除对应的样本数据,即所在的行
2. 替换成缺失值,当缺失值处理
3. 盖帽法处理
结合业务逻辑和算法需求判断是否需要处理异常值以及如何处理,一般情况下盖帽
法即可,即将极端异常的值改成不那么异常的极值。不过一些算法例如决策树中连
续变量的异常值也可以不做处理。
自定义盖帽法函数
盖帽法将某连续变量均值上下三倍标准差范围外的记录替换为均值上下三倍标准差
值,即盖帽处理。
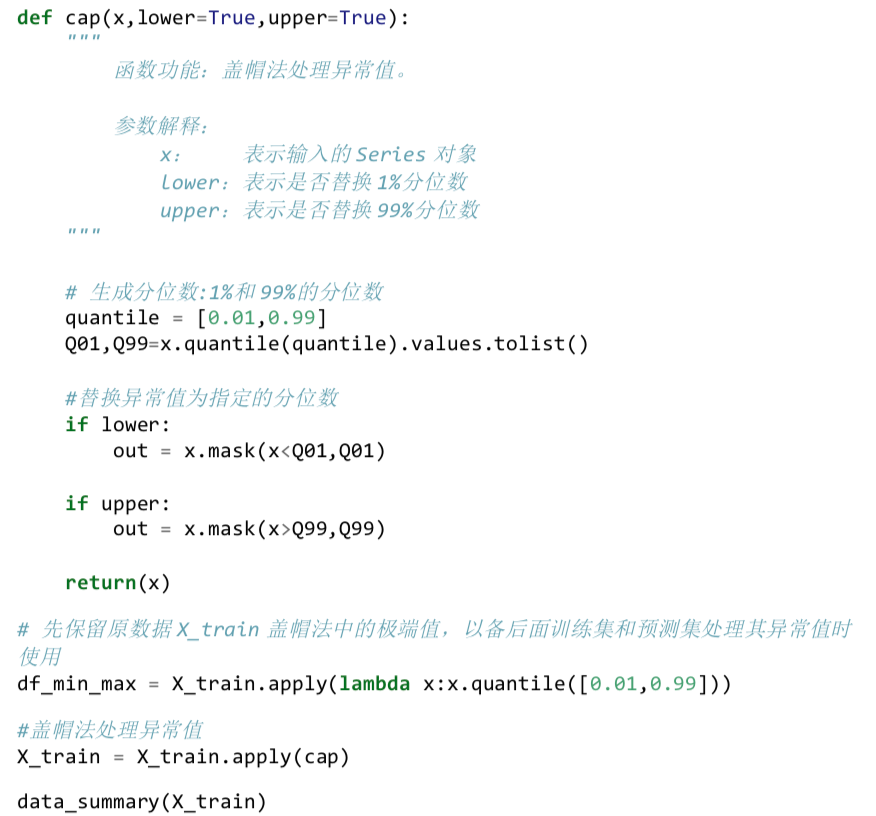
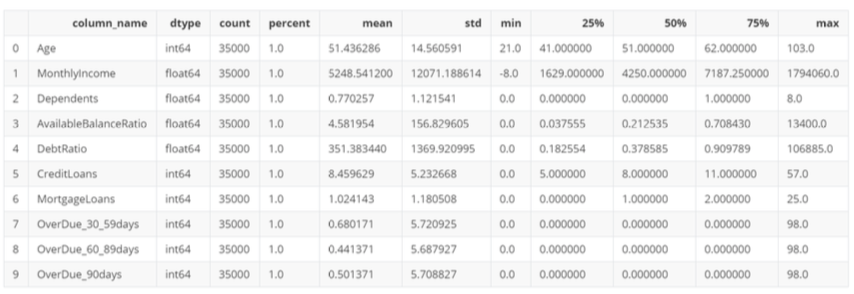
数据清洗-测试集数据

训练数据特征处理
WOE 分箱
我们要制作评分卡,最终想要得到的结果是要给各个特征进行分档,以便业务人员
能够根据新客户填写的信息为客户打分。我们知道变量(即特征)的形态可分为离
散型和连续型,离散型天然就是分档的,因此,我们需要重点如何使连续变量分档,
即连续变量离散化。
连续变量离散化,我们也常称为分箱或者分组操作。它是评分卡制作过程中一个非
常重要的步骤,是评分卡最难,也是最核心的思路。目的就是使拥有不同属性的客
户被分成不同的类别,进而评上不同的分数。在评分卡建模流程中,我们常用WOE(Weight of Evidence,迹象权数)方法对变量进行分箱。
WOE 分箱的好处:
• 避免变量值中出现极端值(Outliers)的情形
• 减少模型过度配适(Overfitting)的现象

变量的IV值
用与之相关的另一个重要概念,IV 值(Information Value,信息值)则用来衡量该变量(特征)对好坏客户的预测能力。
查看每个变量对应的 IV 值


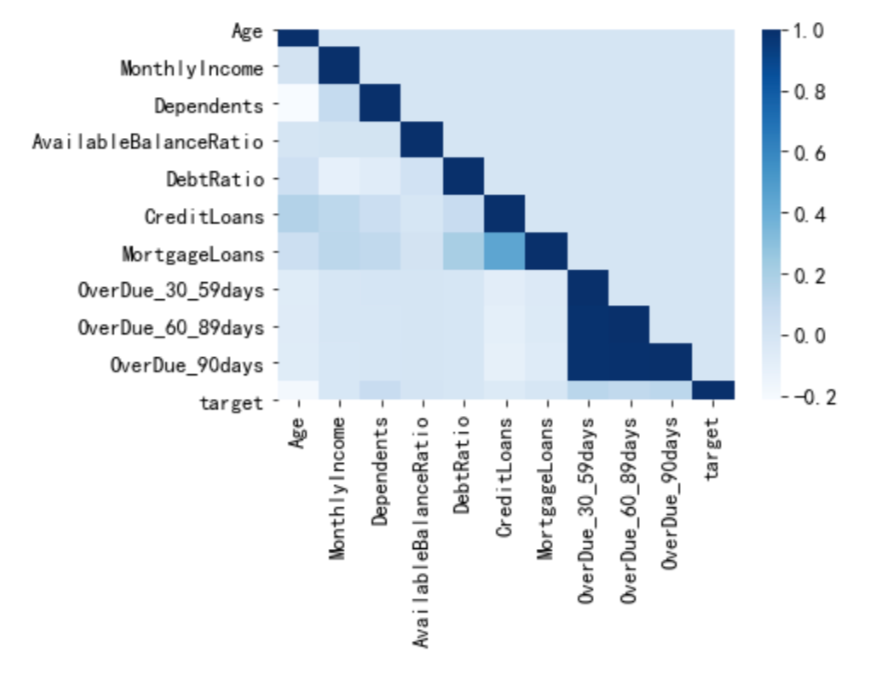



数据准备工作完成后我们接下来就要在此数据基础上构建评分卡模型了。
其实数据准备工作往往不是一蹴而就的。
如果后面模型不理想,有可能还要重新处理数据,重做特征工程。
以下是福利区


点这里👇关注我,记得标星哦~











