点击上方“图灵人工智能”,选择“星标”公众号
您想知道的人工智能干货,第一时间送达
来源:海豚数据科学实验室
编辑:王萌
著作权归作者所有,本文仅作学术分享,若侵权,请联系后台删文处理
目前,关于神经网络的定义尚不统一,按美国神经网络学家Hecht Nielsen 的观点,神经网络的定义是:“神经网络是由多个非常简单的处理单元彼此按某种方式相互连接而形成的计算机系统,该系统靠其状态对外部输入信息的动态响应来处理信息”。综合神经网络的来源﹑特点和各种解释,它可简单地表述为:人工神经网络是一种旨在模仿人脑结构及其功能的信息处理系统。人工神经网络(简称神经网络):是由人工神经元互连组成的网络,它是从微观结构和功能上对人脑的抽象、简化,是模拟人类智能的一条重要途径,反映了人脑功能的若干基本特征,如并行信息处理、学习、联想、模式分类、记忆等。深度学习一般指深度神经网络,这里的深度指神经网络的层数(较多)。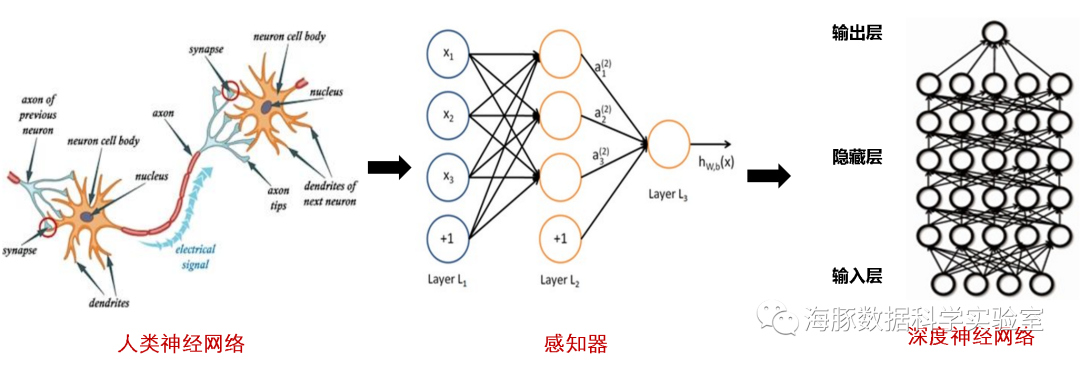
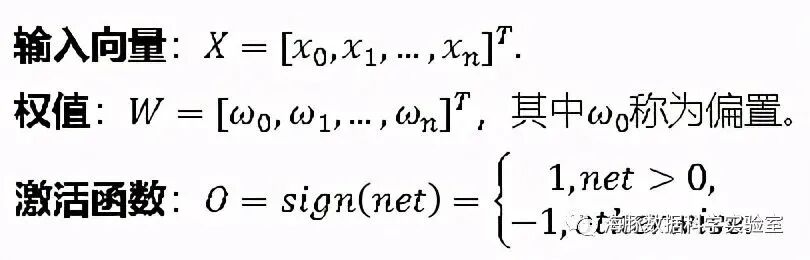
上面的感知器,相当于一个分类器,它使用高维的X向量作为输入,在高维空间对输入的样本进行二分类:当W^T X>0时,o=1,相当于样本被归类为其中一类。否则,o=-1,相当于样本被归类为另一类。这两类的边界在哪里呢?就是W^T X=0,这是一个高维超平面。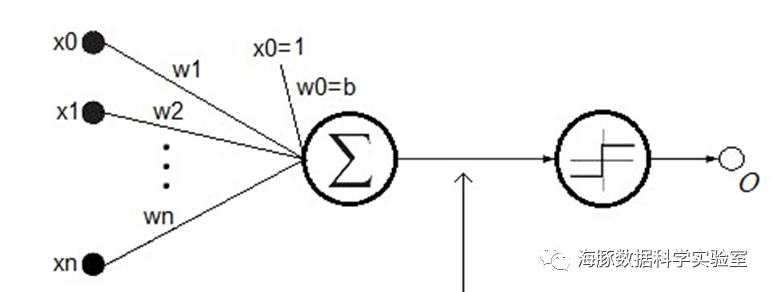

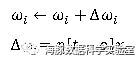
其中,X为输入向量,t为目标值,o为感知器当前权值下的输出,η为学习率,x_i和ω_i为向量X和W的第i个元素。当训练样例线性可分时,反复使用上面的方法,经过有限次训练,感知器将收敛到能正确分类所有训练样例的分类器。在训练样例线性不可分时,训练很可能无法收敛。因此,人们设计了另一个法则来克服这个不足,称为delta法则。它使用梯度下降(Gradient Descent)的方法在假设空间中所有可能的权向量,寻找到最佳拟合训练样例的权向量。l对于多元函数o=f(x)=f(x_0,x_1,…,x_n ),其在X^′=〖[〖x_0〗^′,〖x_1〗^′,…,〖x_n〗^′]" " 〗^T处的梯度为: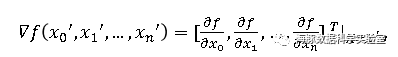
梯度向量的方向,指向函数增长最快的方向。因此,负梯度向量-∇f,则指向函数下降最快的方向。当训练样例线性不可分的时候,我们无法找到一个超平面,令感知器完美分类训练样例,但是我们可以近似地分类他们,而允许一些小小的分类错误。怎样让这个错误最小呢,首先要参数化描述这个错误,这就是损失函数(误差函数),它反映了感知器目标输出和实际输出之间的误差。最常用的误差函数为
L2误差: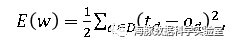
其中,d为训练样例,D为训练样例集,t_d为目标输出,o_d为实际输出。既然损失函数E(W)的自变量是权值,因此他是定义在权值空间上的函数。那么问题就转化成了在权值空间中,搜索使得E(W)最小的权值向量W。然而不幸的是,E(W)=1/2 ∑_(d∈D)▒(t_d-o_d )^2 定义了一个非常负杂的高维曲面,而数学上,对高维曲面的极值求解还没有有效的方法。既然负梯度方向是函数下降最快的方向,那我们可以从某个点开始,沿着−()方向一路前行,期望最终可以找到E(W)的极小值点,这就是梯度下降法的核心思想。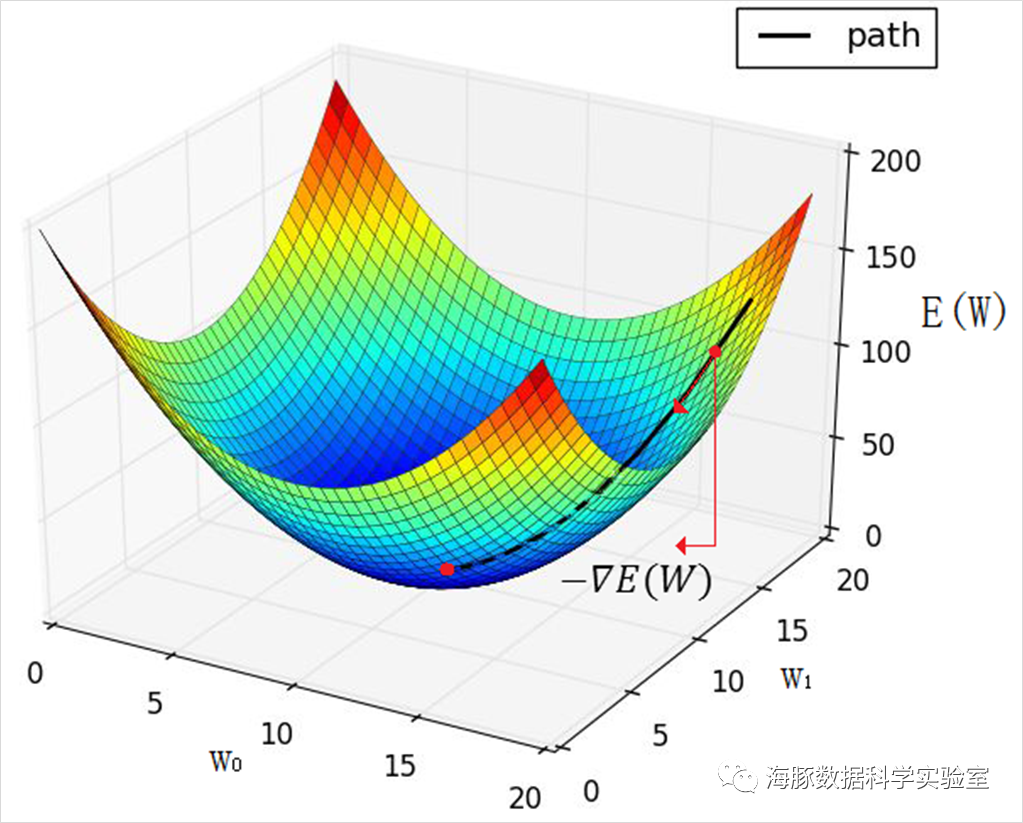
对于训练样例集D中的每一个样例记为,X是输入值向量,t为目标输出,η是学习率。
对于此单元的每个w_i,do:∆w_i+= η(t-o) x_i对于此单元的每个w_i,do:w_i+= ∆w_i这个版本的梯度下降算法,实际上并不常用,它的主要问题是:收敛过程非常慢,因为每次更新权值都需要计算所有的训练样例;如果误差曲面上有多个局部极小值,那么这个过程极易陷入局部极值。针对原始梯度下降算法的弊端,一个常见的变体称为增量梯度下降(Incremental Gradient Descent),亦即随机梯度下降(SGD:Stochastic Gradient Descent)。其中一种实现称为在线学习(Online Learning),它根据每一个样例来更新梯度: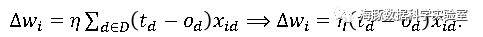
ONLINE-GRADIENT-DESCENT(D, η)
针对上两种梯度下降算法的弊端,提出了一个实际工作中最常用的梯度下降算法,即Mini-Batch SGD。它的思想是每次使用一小批固定尺寸(BS:Batch Size)的样例来计算∆w_i,然后更新权值。BATCH-GRADIENT-DESCENT(D, η, BS)从D中下一批(BS个)样例,对这批样例中的每一个,do:对于此单元的每个w_i,do:w_i += ∆w_i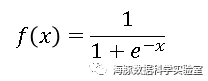
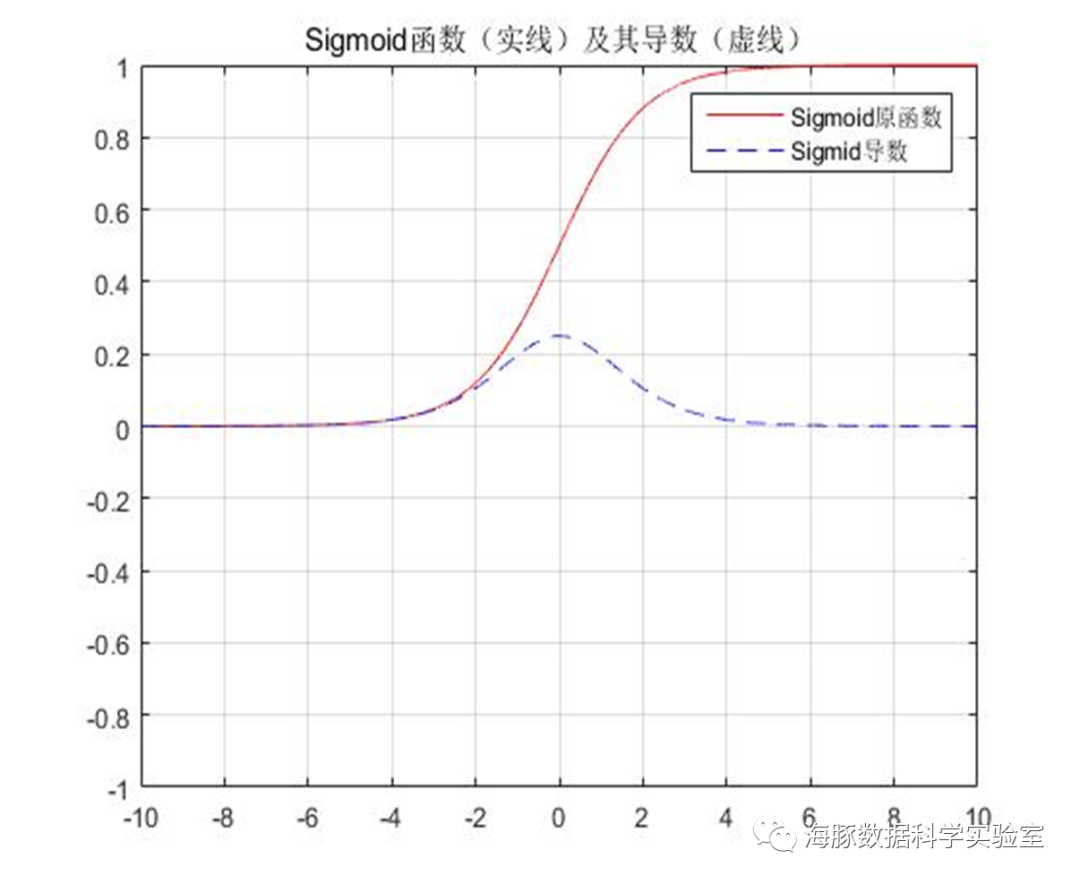
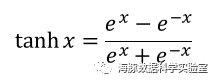
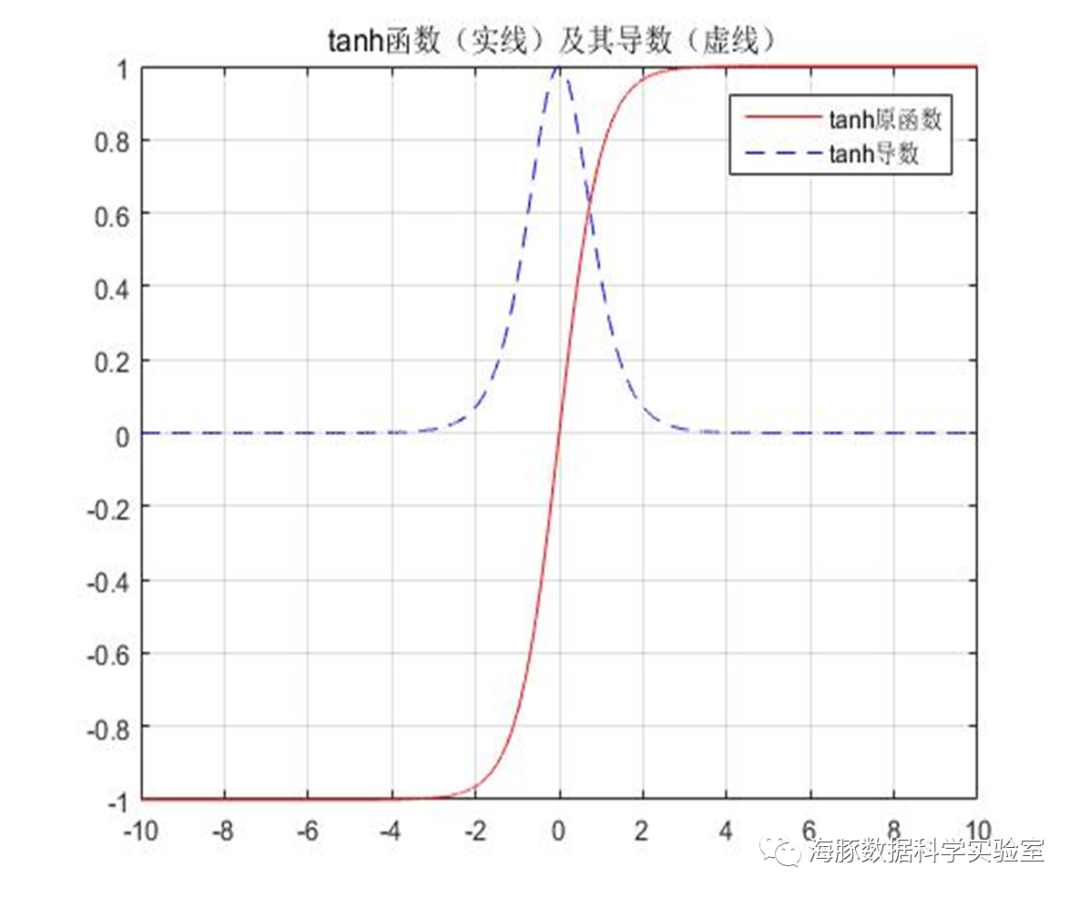
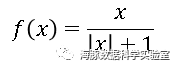
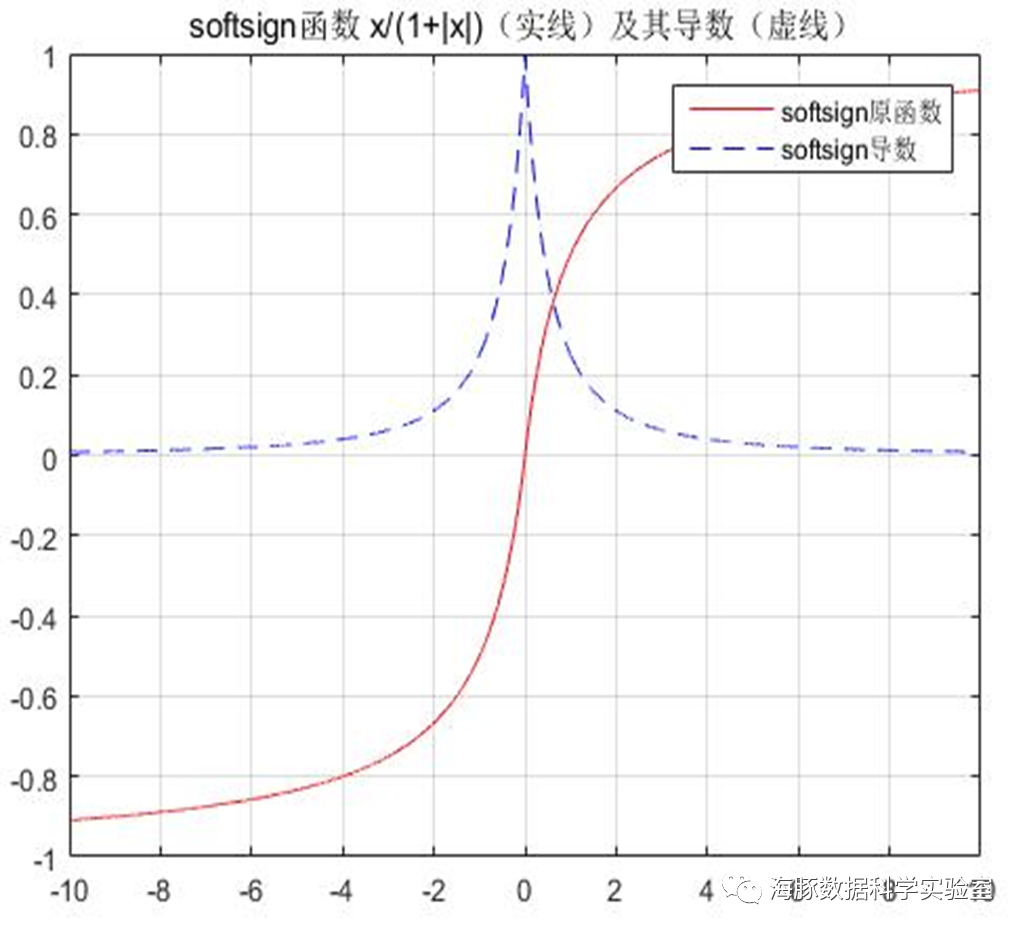
ReLU( Rectified Linear Unit )函数: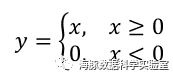
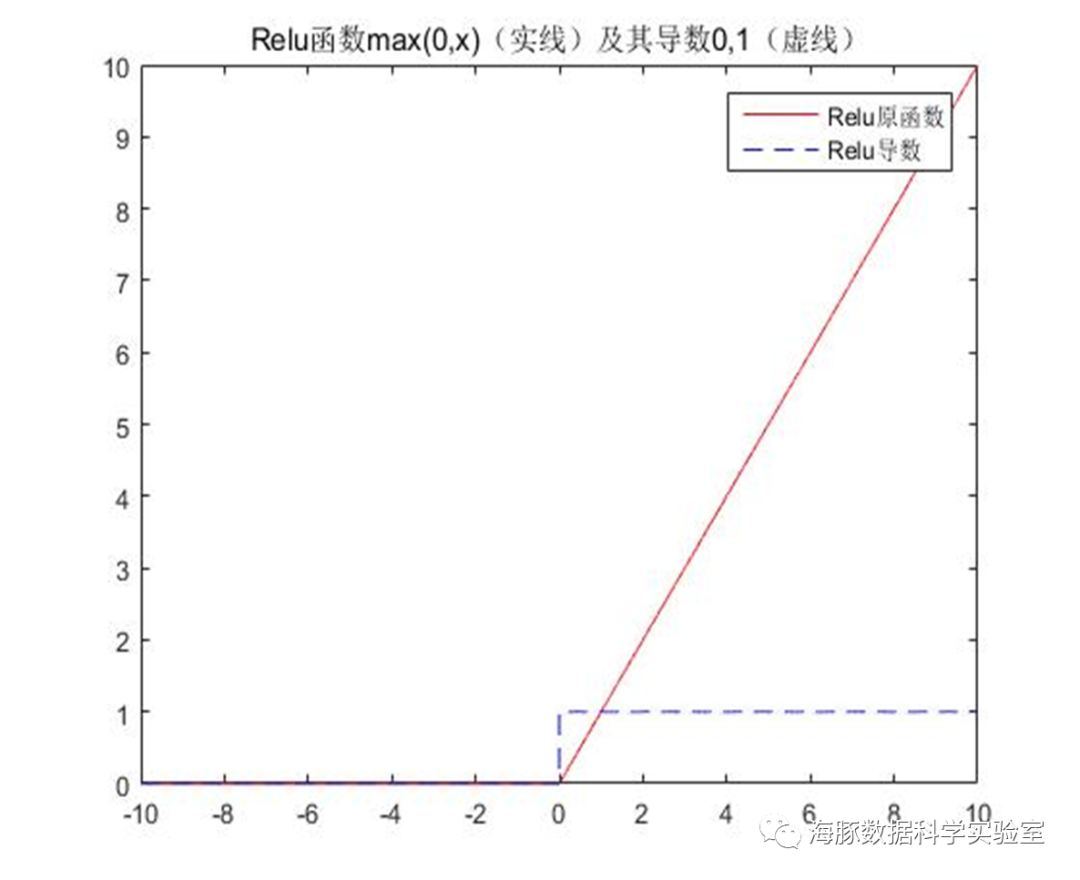
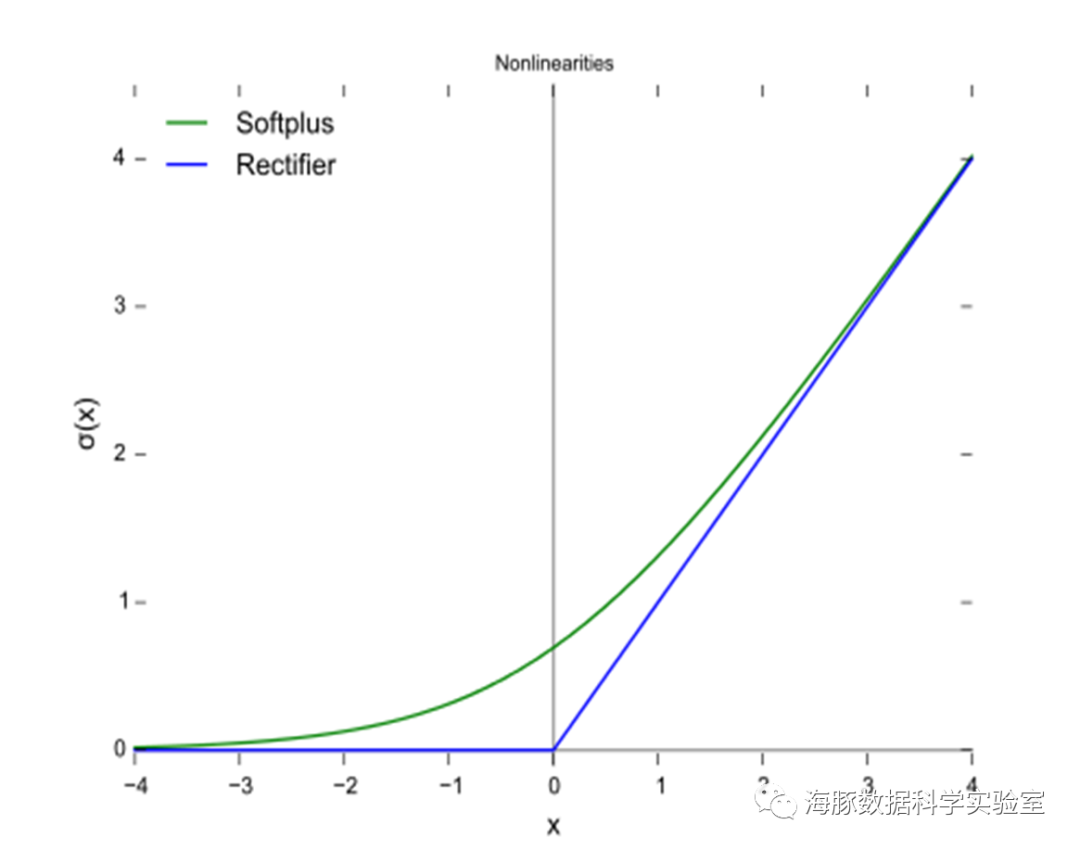
非线性:当激活函数是非线性的,一个两层神经网络可以证明是一个通用函数近似值,如果失去了非线性,整个网络就相当于一个单层的线性模型。连续可微性:这个属性对基于梯度优化方法是必要的,如果选择了一些具有局部不可微的函数,则需要强行定义此处的导数。有界性:如果激活函数有界的,基于梯度的训练方法往往更稳定;如果是无界的,训练通常更有效率,但是训练容易发散,此时可以适当减小学习率。单调性:如果激活函数是单调的,与单层模型相关的损失函数是凸的。平滑性:有单调导数的平滑函数已经被证明在某些情况下泛化效果更好。原点附近近似Identity:当激活函数有这个特点时,对于小的随机初始化权重,神经网络能够更有效地学习。否则,在初始化权值时往往需要进行特殊设计。单个感知器的表达能力有限,它只能表达线性决策面(超平面)。如果我们把众多的感知器互联起来,就像人的大脑做所的那样,再将激活函数更换为非线性函数,我们就可以表达种类繁多的非线性曲面。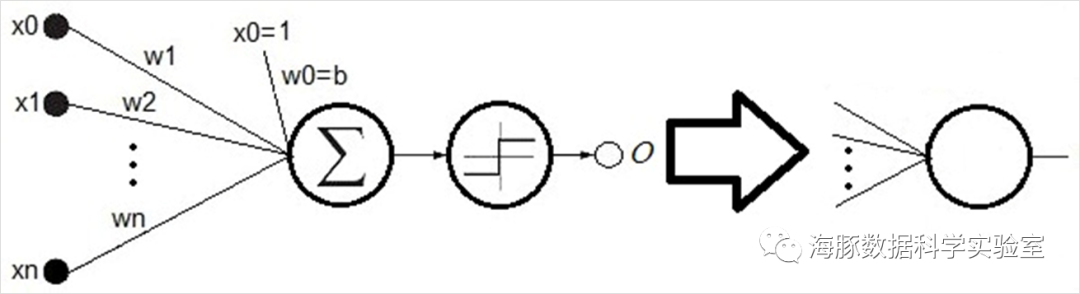
前馈神经网络是一种最简单的神经网络,各神经元分层排列。是目前应用最广泛、发展最迅速的人工神经网络之一。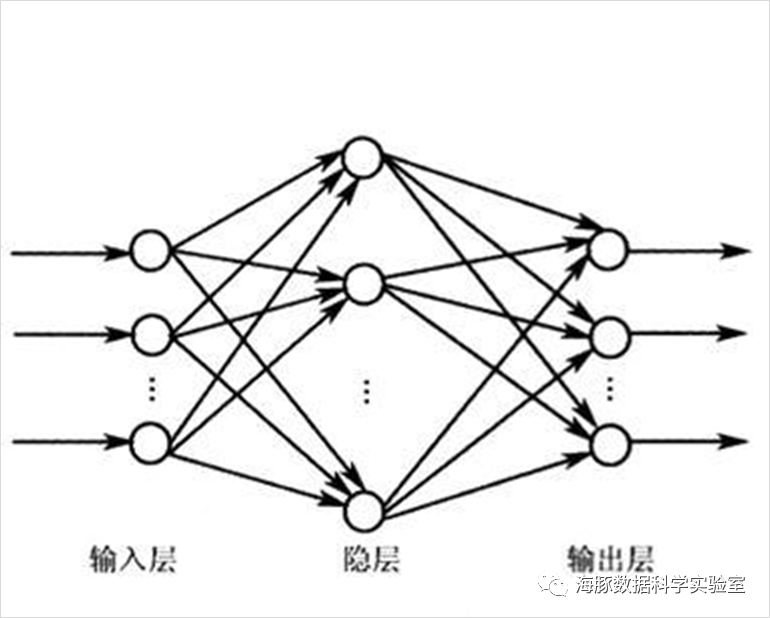
可以看出,输入节点并无计算功能,只是为了表征输入矢量各元素值。各层节点表示具有计算功能的神经元,称为计算单元。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层,采用一种单向多层结构,每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。
有了这个公式,我们就可以训练神经网络了,公式重列如下:1.取出下一个训练样例,将X输入网络,得到实际输出O。2.根据输出层误差公式(1)求取输出层δ,并更新权值。3.对于隐层,根据隐层误差传播公式(2)从输出往输入方向反向、逐层、迭代计算各层的δ,每计算好一层的δ,更新该层权值,直至所有权值更新完毕。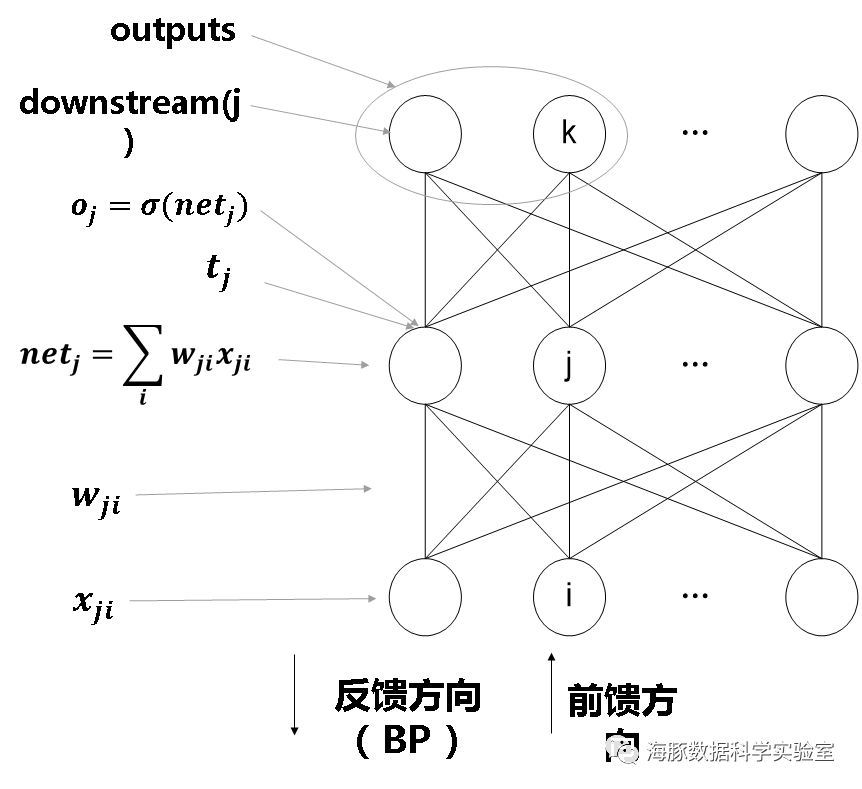
l卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于图像处理有出色表现。它包括卷积层(convolutional layer),池化层(pooling layer)和全连接层(fully_connected layer)。
l20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。l现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。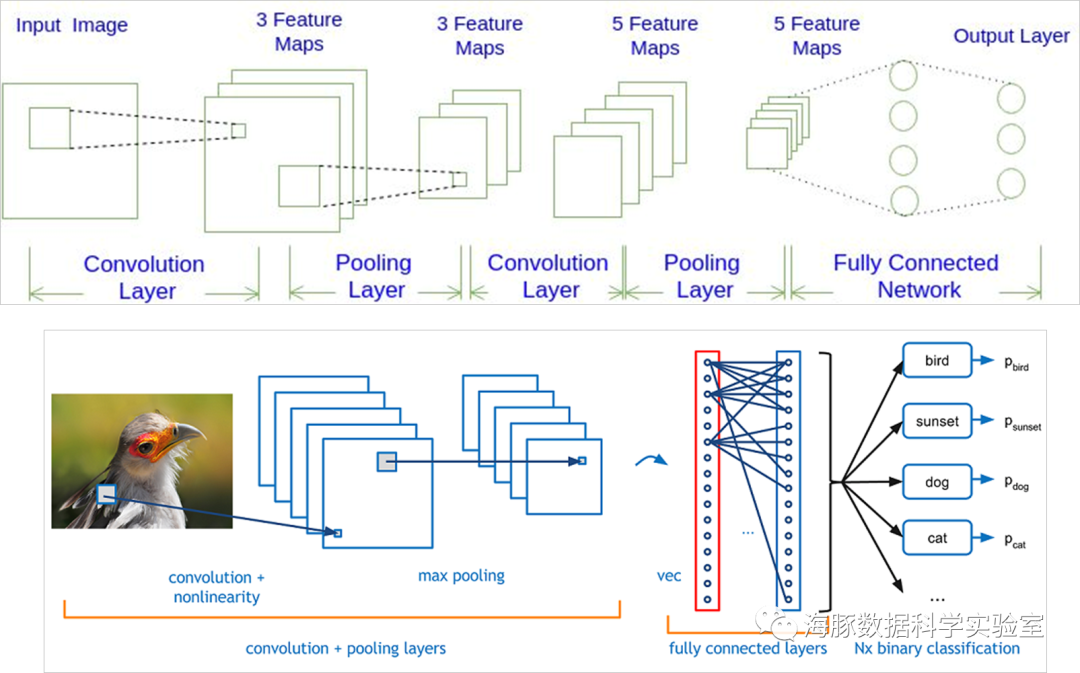
卷积神经网络的基本结构,就是前面说的多通道卷积。上一层的输出(或者第一层的原始图像),作为本层的输入,然后和本层的卷积核卷积,作为本层输出。而各层的卷积核,就是要学习的权值。和FCN类似,卷积完成后,输入下一层之前,也需要经过偏置和通过激活函数进行激活。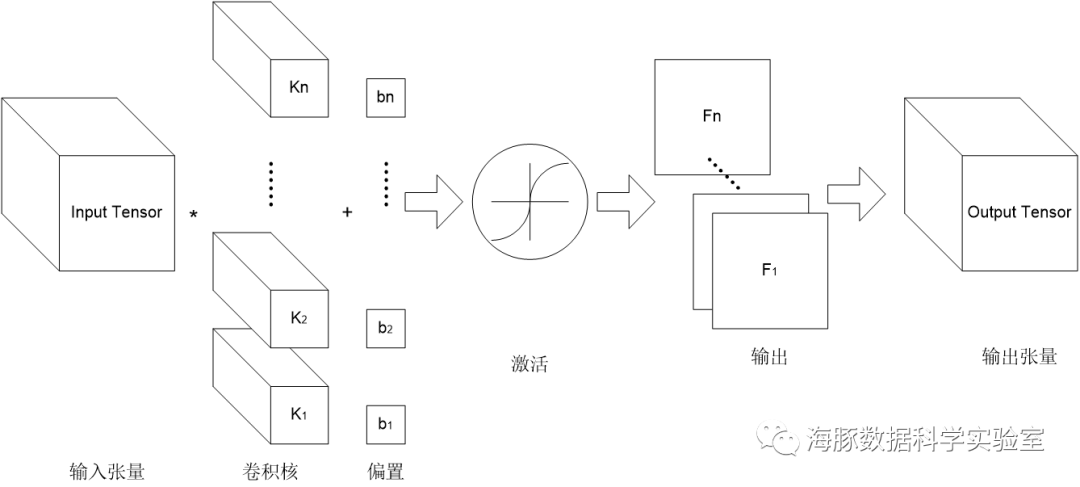
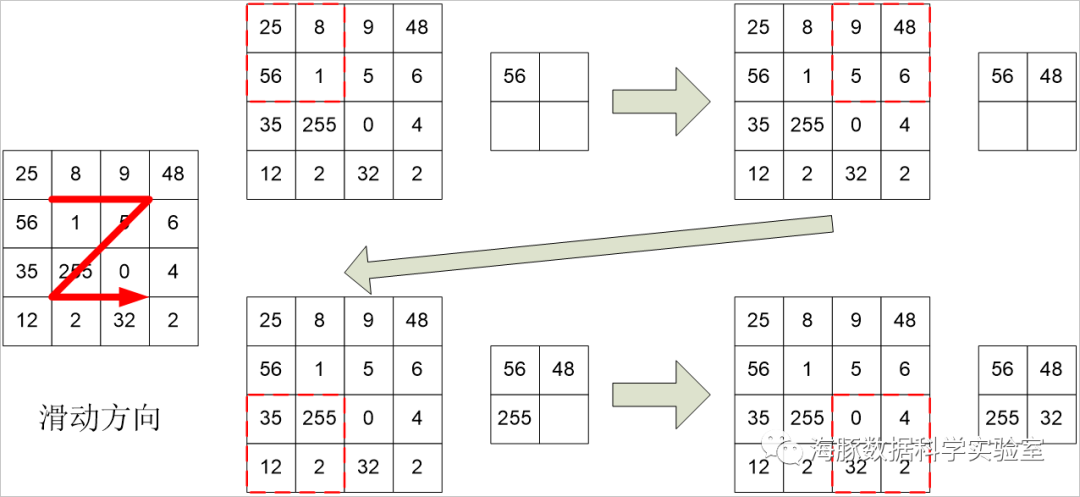
Pooling的中文名为池化,它合并了附近的单元,减小了下层输入的尺寸。常用的Pooling有Max Pooling和Average Pooling,顾名思义,Max Pooling选择一小片正方形区域中最大的那个值作为这片小区域的代表,而Average Pooling则使用这篇小区域的均值代表之。这片小区域的边长为池化窗口尺寸。下图演示了池化窗口尺寸为2的一般Max池化操作。
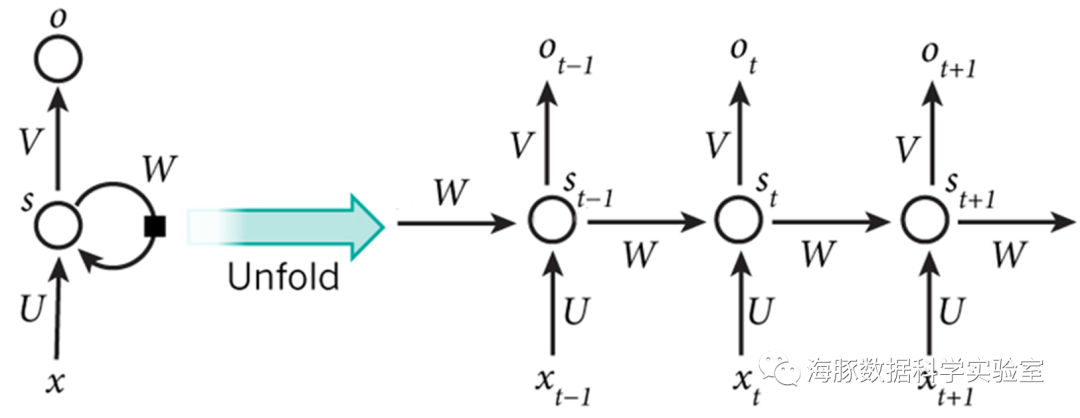
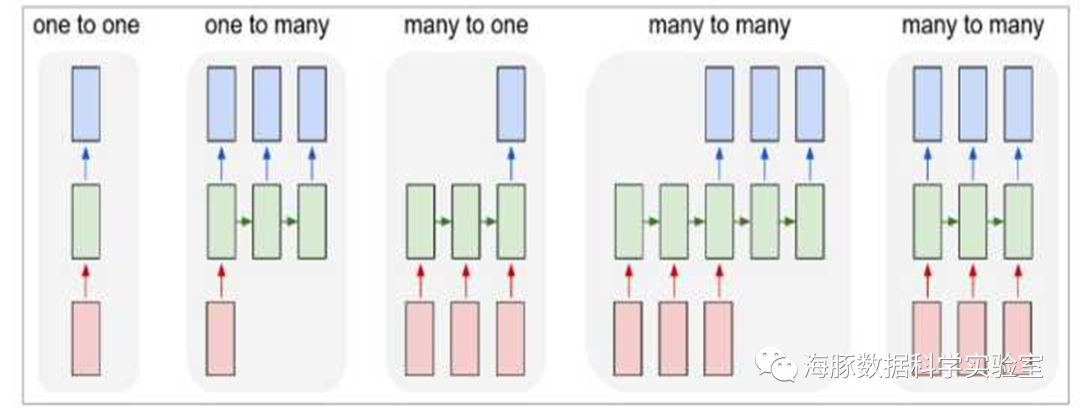
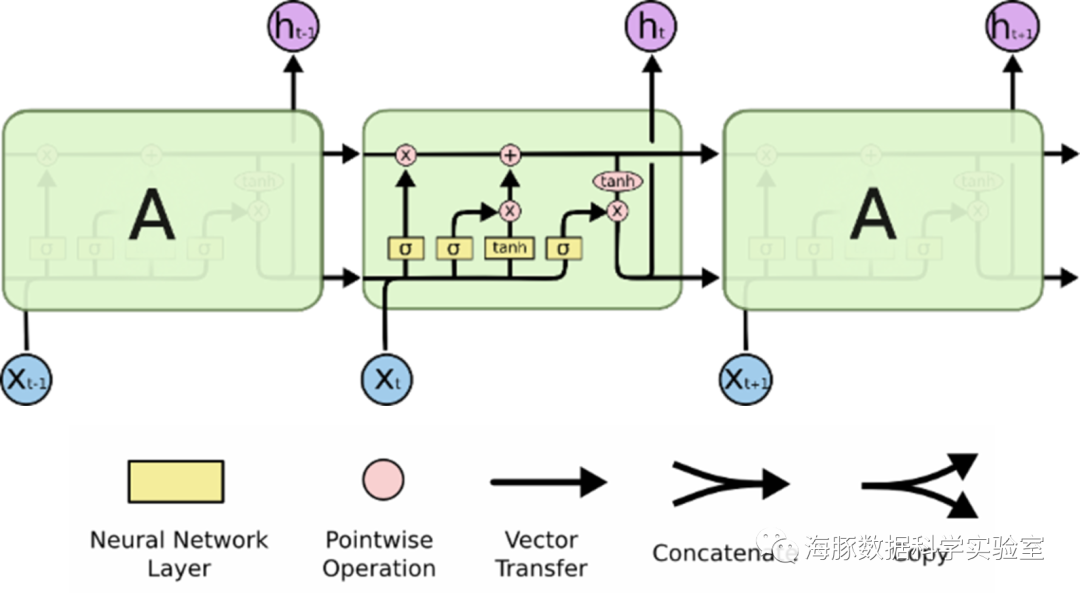
循环神经网络(Recurrent neural networks,简称RNN)是一种通过隐藏层节点周期性的连接,来捕捉序列化数据中动态信息的神经网络,可以对序列化的数据进行分类。和其他前向神经网络不同,RNN可以保存一种上下文的状态,甚至能够在任意长的上下文窗口中存储、学习、表达相关信息,而且不再局限于传统神经网络在空间上的边界,可以在时间序列上有延拓,直观上讲,就是本时间的隐藏层和下一时刻的隐藏层之间的节点间有边。RNN广泛应用在和序列有关的场景,如如一帧帧图像组成的视频,一个个片段组成的音频,和一个个词汇组成的句子。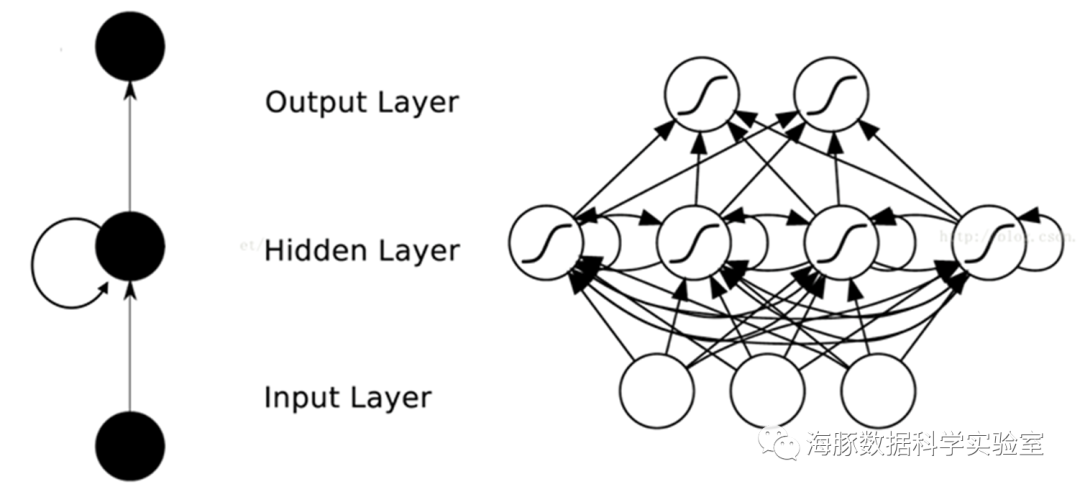
正则化是机器学习中非常重要并且非常有效的减少泛化误差的技术,特别是在深度学习模型中,由于其模型参数非常多非常容易产生过拟合。因此研究者也提出很多有效的技术防止过拟合,比较常用的技术包括:参数添加约束,例如L_1、L_2范数等。
训练集合扩充,例如添加噪声、数据变换等。
Dropout
l许多正则化方法通过对目标函数J添加一个参数惩罚Ω(θ),限制模型的学习能力。我们将正则化后的目标函数记为J ̃。J ̃(θ;X,y)=J(θ;X,y)+αΩ(θ),
其中αϵ[0,∞)是权衡范数惩罚项Ω和标准目标函数J(X;θ)相对贡献的超参数。将α设为0表示没有正则化。α越大,对应正则化惩罚越大。J ̃(w;X,y)=J(w;X,y)+α‖w‖_1,l参数约束添加L_2范数惩罚项,该技术用于防止过拟合。J ̃(w;X,y)=J(w;X,y)+1/2 α‖w‖^2,通过最优化技术,例如梯度相关方法可以很快推导出,参数优化方式为其中ε为学习率,相对于正常的梯度优化公式,对参数乘上一个缩减因子。通过上面的分析,L_1相对于L_2能够产生更加稀疏的模型,即当L_1正则在参数w比较小的情况下,能够直接缩减至0,因此可以起到特征选择的作用。如果从概率角度进行分析,很多范数约束相当于对参数添加先验分布,其中L_2范数相当于参数服从高斯先验分布;L_1范数相当于拉普拉斯分布。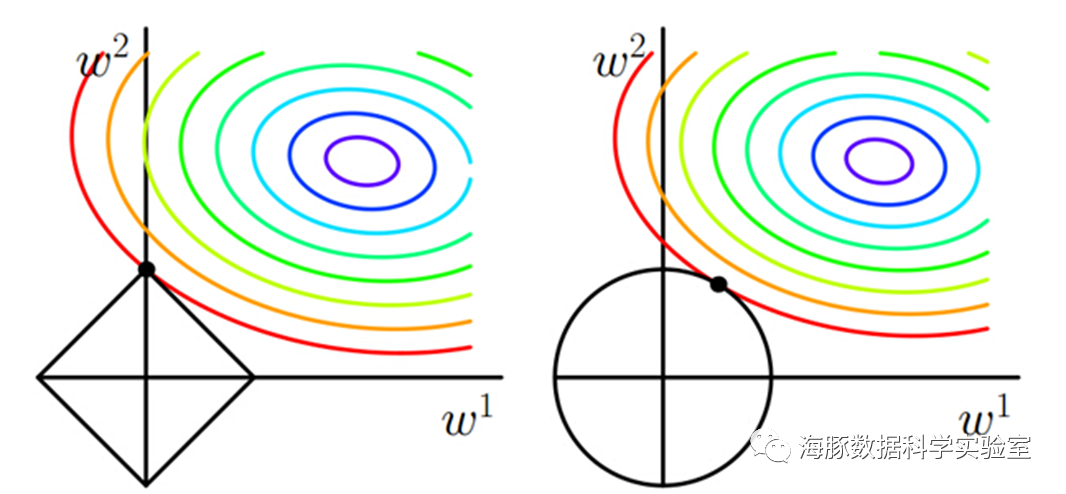
防止过拟合最有效的方法是增加训练集合,训练集合越大过拟合概率越小。数据集合扩充是一个省时有效的方法,但是在不同领域方法不太通用。lDropout是一类通用并且计算简洁的正则化方法,在2014年被提出后广泛的使用。简单的说,Dropout在训练过程中,随机的丢弃一部分输入,此时丢弃部分对应的参数不会更新。相当于Dropout是一个集成方法,将所有子网络结果进行合并,通过随机丢弃输入可以得到各种子网络。例如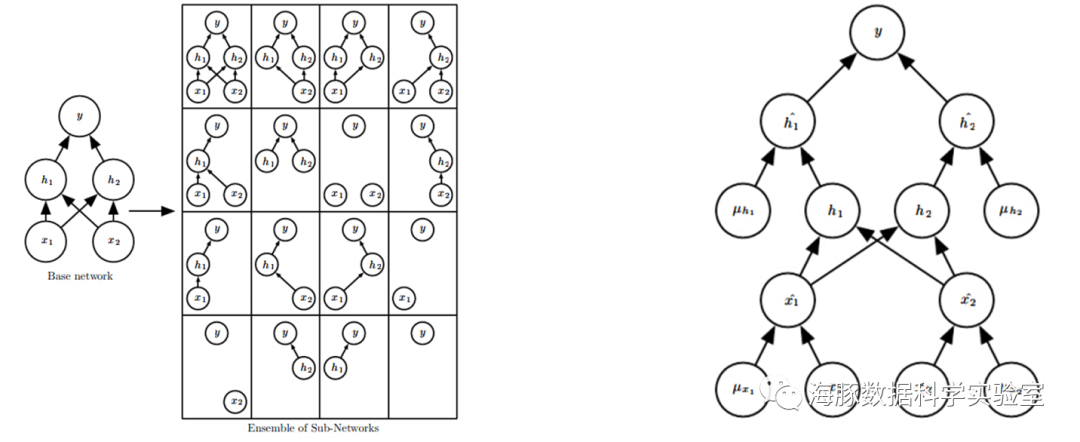
在梯度下降算法中,有各种不同的改进版本。在面向对象的语言实现中,往往把不同的梯度下降算法封装成一个对象,称为优化器。
常见的优化器如:普通GD优化器、动量优化器、Nesterov、Adagrad、Adadelta、RMSprop、Adam、AdaMax、Nadam
往期精彩必读文章(单击就可查看):
1.图灵奖得主Hamming的22年前经典演讲:如何做研究,才能不被历史遗忘
2.当这位70岁的Hinton老人还在努力推翻自己积累了30年的学术成果时,我才知道什么叫做生命力(附Capsule最全解析)
3.你为什么获得不了图灵奖,原来本科学的是计算机专业,数据显示历届图灵奖得主当中竟然只有三位在本科时主修计算机专业......
4.图灵奖得主Jeff Ullman直言:机器学习不是数据科学的全部!统计学也不是
5.魔幻现实!英国百年名校认为基础数学没用,要裁掉数学系补贴AI研究,图灵听后笑了笑
6.图灵奖得主Yann LeCun的六十年
7.图灵奖得主长文报告:是什么开启了计算机架构的新黄金十年?
8.看了 72 位图灵奖得主成就,才发现我对计算机一无所知
9.重读图灵经典之作,九条反驳意见引人深思
10.从图灵奖看人工智能的历史沉浮







