
量化投资与机器学习微信公众号,是业内垂直于量化投资、对冲基金、Fintech、人工智能、大数据等领域的主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业20W+关注者,连续2年被腾讯云+社区评选为“年度最佳作者”。
量化投资与机器学习公众号独家解读
量化投资与机器学公众号 QIML Insight——深度研读系列 是公众号今年全力打造的一档深度、前沿、高水准栏目。

公众号遴选了各大期刊前沿论文,按照理解和提炼的方式为读者呈现每篇论文最精华的部分。QIML希望大家能够读到可以成长的量化文章,愿与你共同进步!
本期遴选论文
来源:The Journal of Financial Data Science Fall 2021
标题:Benchmark Dataset for Short- Term Market Prediction of Limit Order Book in China Markets
作者:Charles Huang, Weifeng Ge, Hongsong Chou, Xin Du
重构订单簿
深交所的Level2数据包含逐笔委托和成交数据。准确的模拟撮合方法就是回放交易所的逐笔委托和成交数据,根据交易所撮合机制、市场流动性来模拟撮合订单,从而得出策略的成交概率。高频策略研究中,可以通过这两个数据重构订单簿,并生成任意时间间隔的快照数据。(上交所的逐笔数据暂时还未完全公开)。
作者基于深交所的Level2数据重构了订单簿,生成了1秒间隔的快照数据及每一秒间隔内发生的交易统计数据,分别称为Snapshot component和Periodical component,下图就展示了平安银行某个时间点的快照:
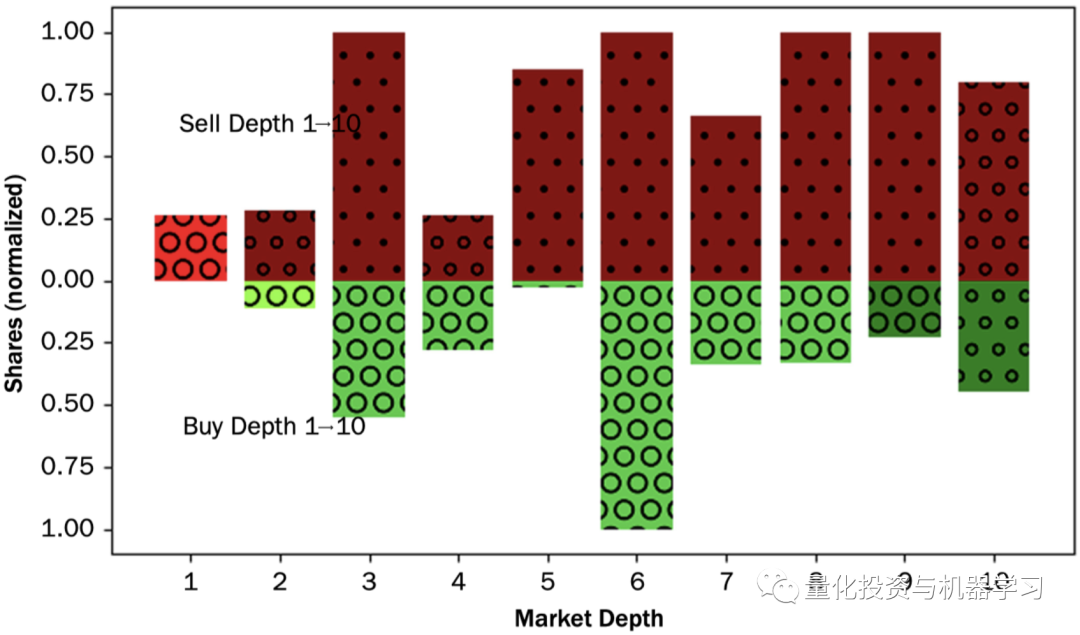
关于重构订单簿,作者指出学术界常用LOBSTER软件,公众号查了下一年的费用需要近5000欧元😭。他们自己用C++实现了重构逻辑,但没给出具体逻辑和代码。
基于以上1秒间隔的Snapshot及Periodical数据,作者尝试构建预测模型对未来一段时间的价格及成交量进行预测。
深度学习模型预测Tick级价格变动
特征
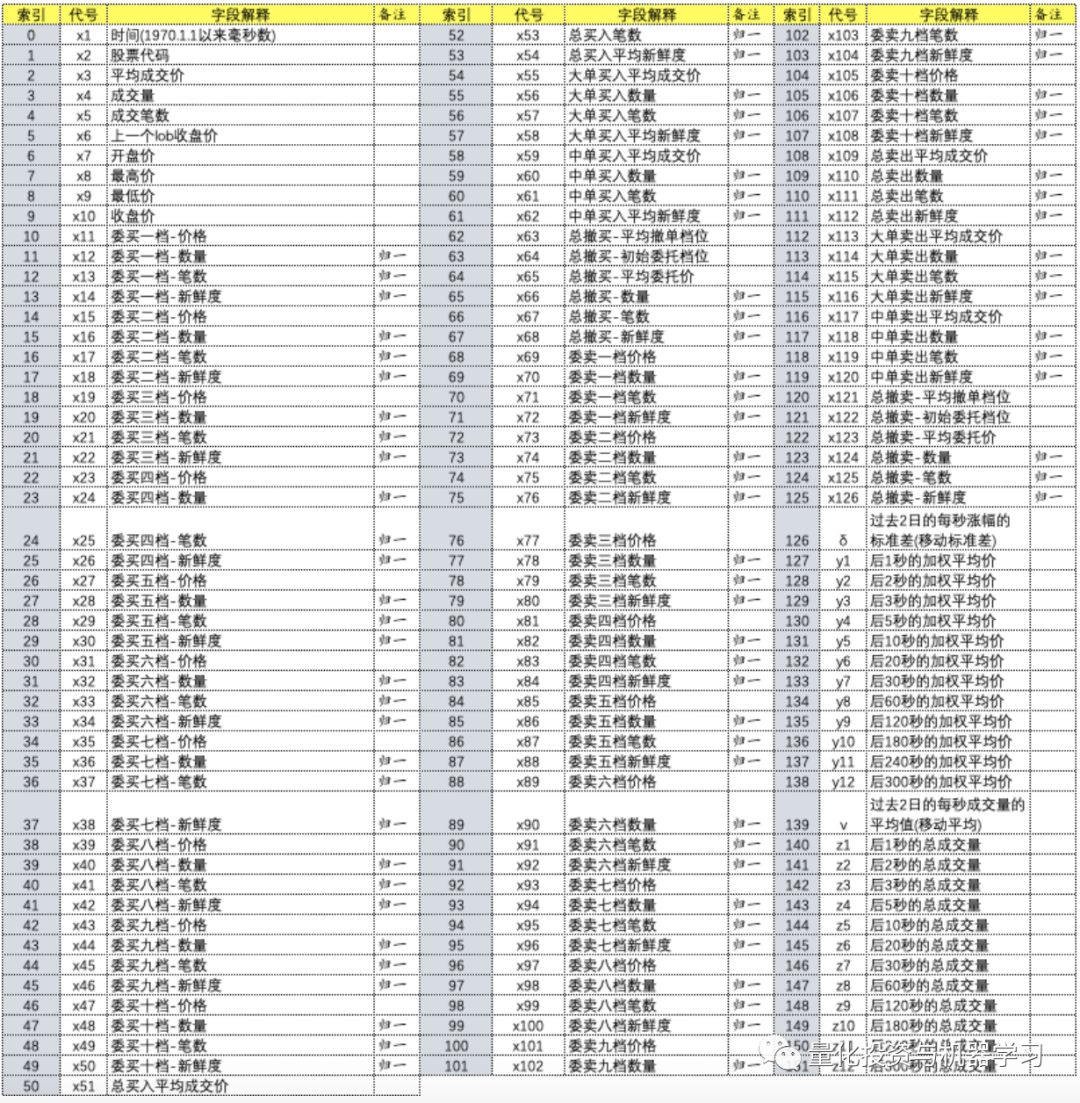
作者一共构建了124个特征, 分成两大类:
作者对以上特征数据做了以下处理:
- 价格数据保持不变,当没有成交量时,对价格数据进行前向填充;
- 交易量数据除以所有交易量数据的10%分位数进行标准化;
- 订单量数据除以所有订单量数据的10%分位数进行标准化;
- 新鲜度分为三类: 0 (过去5秒以内), 1 (过去5-30秒), 2 (过去超过30秒)。
标签
预测未来1, 2, 3, 5, 10, 20, 30, 60, 120, 180, 240, 及300秒的价格及成交量:
详细的特征及标签的说明如下(除去股票代码和时间):
模型
训练数据:2020年6月3日至2020年8月31日,9:30-11:30及13:00-14:57的快照数据;
测试数据:2020年9月1日至2020年9月30日的快照数据;
每个输入到模型的数据结构如下:
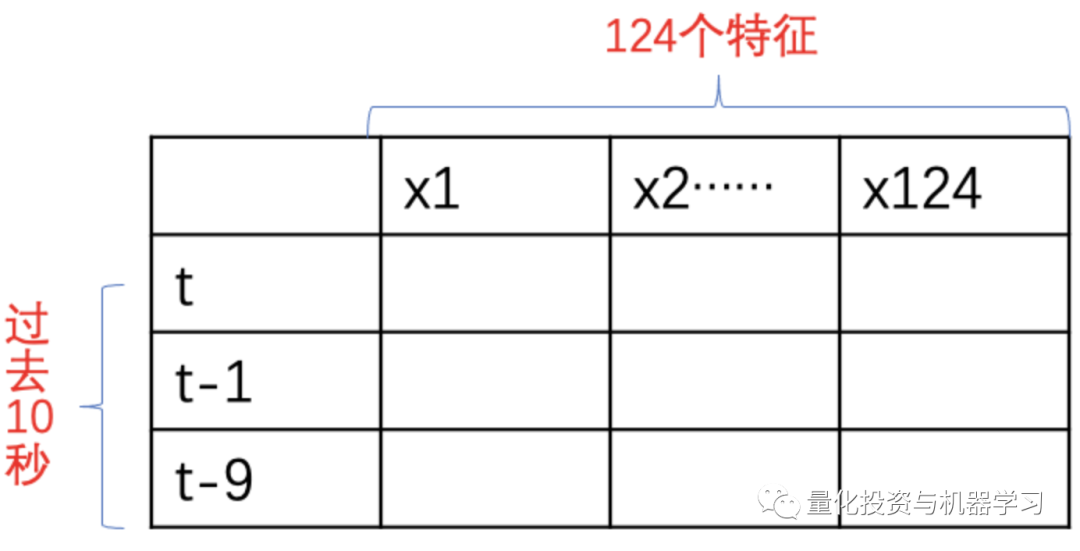
针对每个预测标签都构建一个模型,所以任何一类模型都会有24个子模型,如12个预测价格的模型及12个预测成交量的模型。(1, 2, 3, 5, 10, 20, 30, 60, 120, 180, 240, 及300秒的价格及成交量)。
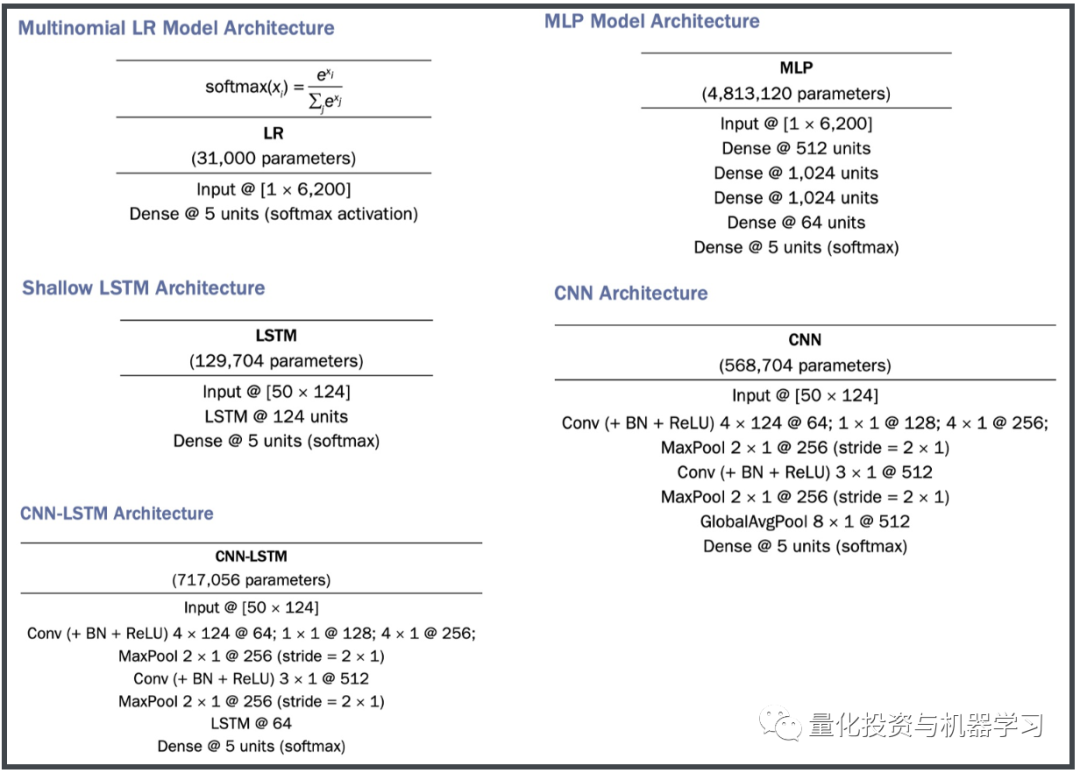
总共测试了5个模型,模型的架构如下图展示:
测试结果
由于计算资源的限制,作者在最后的实证中对20个交易最活跃的股票进行了建模分析,预测的标签是未来5,6及300秒的价格。使用的是Pytorch和RTX 2080显卡,结果如下:
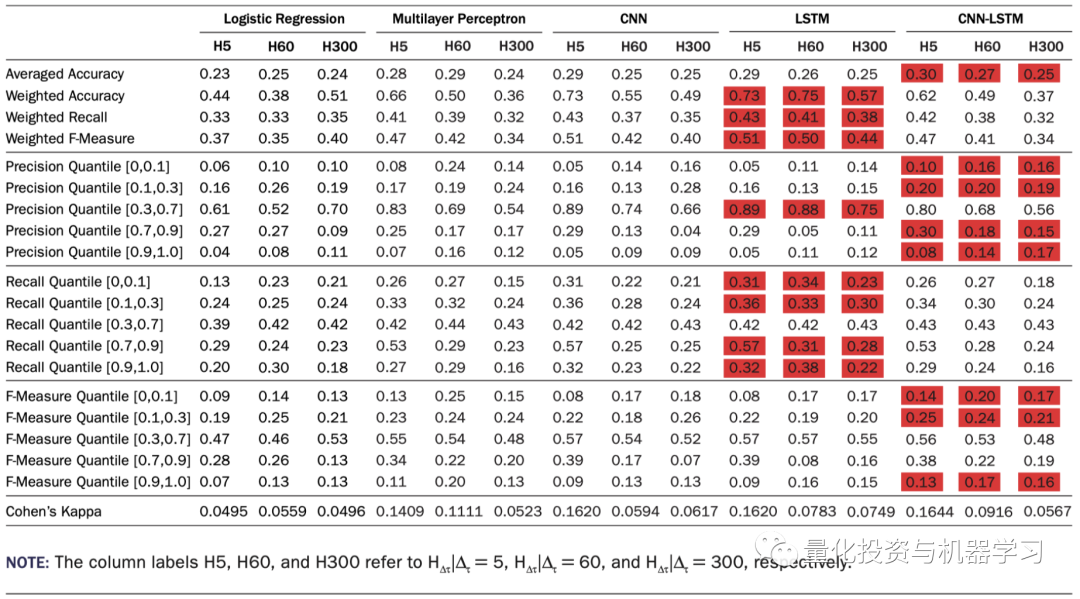
可以看出,LSTM和CNN-LSTM要优于MLP和CNN。且所有四个非线性的模型的表现都优于线性模型。但是同样也可以看到,每个模型预测准确率最高的分位数是区间是0.3-0.7,也就是说模型对于极端价格的变动没有很好的预测能力。作者表示,未来应该使用更多的数据,更长的历史Lookback长度及更复杂或合适的网络结构构建深度学习模型。
开源代码
所有的模型代码及数据均已在Github开源,大家可以访问如下网址获取:
https://github.com/hkgsas/LOB










