点击关注公众号,Python干货及时送达
PyCharm操作手册,点击获取
五岁时,我常常依偎在妈妈怀里,听妈妈给我讲故事。讲放羊的小男孩三次大喊“狼来了”,骗村里的人上山来救他,后来,当狼真正来了,村里的人却不信他了,没去救他,他就被狼拖走;讲白雪公主和七个小矮人的故事……一个个故事,把我带到了五彩缤纷的世界里。后来,妈妈说,她讲的故事,都是从书里看到的。还说,只要我以后多看书,也会知道很多很多的故事。从那时候开始,我就爱上了看书。从看花花绿绿的图画书开始,到后来看只有文字没有插图的书。读三年级时候,我就看过了《格林童话》、《安徒生故事》、《淘气包马小跳》。
读四年级时,我们班有了新书柜,还有400多本书:社会、小 说、故事、作文、历史等等。有一次,我向老师从班里借了一本《生命流泪的样子》。回到家里,我放下书包就坐在沙发上津津有味地看书了。当时,妈妈在厨房里炒菜。我看了一会,妈妈出来,递给我十块钱,叫我去买一包盐。我放下书,接过钱,一边走一边想书里的内容。到了村里的小超市,我有点懵了,妈妈叫我买的是什么东西了?我看着手上的十块钱,心想:妈妈早就说今天要做甜酸排骨,一定是要我买白糖的吧。于是,我叫老板给我称了十块钱的白糖就回家了。回到家,我把白糖交给了妈妈,妈妈看着手里的白糖,皱着眉头,不满地说:“女儿,你今天怎么了?我叫你买的是盐,不是白糖。”我吃惊地说:“哦,不是买糖啊!我刚才只想着书里的内容,不记得您叫我买什么东西了,妈妈。”妈妈听了我说的话,哭笑不得。
早几天,妈妈要去街上买衣服,就告诉我阳台上嗮着被子,如果下雨就要记得把被子收回屋里,不然淋湿了,今晚就没得盖了。我正在看着向同学借的《创新作文》,听了妈妈的话,随口就答应:“知道了,妈妈。”我看了一篇又一篇优秀作文,也不知天什么时候天变成灰色的了,还响起了雷声。我赶紧关窗门。
Python丰富的开发生态是它的一大优势,各种第三方库、框架和代码,都是前人造好的“轮子”,能够完成很多操作,让你的开发事半功倍。
那
自从上星期莫明其妙地被拉出来练广播体操后,我们每天dou要练三四节课的广播体操。每次练习时我的手或腰都被老师掰的异常疼痛,每次都觉得练的非常到位,但还是被眼尖的老师挑出毛病来,想偷点懒都会被举报,被老师惩罚。
直到后来我才明白,我们之所以那么努力是为了两星期后的广播体操比赛,知道真相后,我们全班同学练得更起劲了。喊口号时dou要特大声,好像恐怕全校听不见似的,练习进场和退场我们班排的齐齐得,走路也是齐齐的,喊口号时都能听到齐齐的踏步声。
练了两星期以后,我们已练得炉火纯青了,也迎来了广播体操的到来。
这天早晨,全校都没去上课,而是在操场齐齐的站队,每个人的脸上无不露出自信的神情。我们都在操场上等待,等待老师抽签的归来,老师回来了,脸上露出失望的神情,可他很快转变了脸色,开玩笑地说看:“很好,我们抽了上上签,第一个上场。”
“什么?”我们不禁大吃一惊,第一个上场很吃亏呀!但我们很快就平静了下来,我们有强大的实力做后盾第一个出场怕什么,有实力就行,毕竟大家辛苦练了那么久。
“好吧!该你们出场了,记住不要有什么小动作,专心地做,做好了有奖励!”老师高声严厉道。
我们在班长的指挥下,整齐地走向评委面前的空地,班长大喊:“以广播体操队形散开,一二一,一二一……”,我们飞快而又整齐地站好自己的位置。
老师放好了音乐,“第一节广播体操开始……”我们熟练地跳着广播体操。不料我的鞋带竟然不争气地散开了,我跳起来鞋子一直跟穿不上似的,感觉鞋子都快要掉下去了,就连跳跃运动都没跳好,幸好我站后面,评委看不到我,不然我们班就因我只“耗子,坏一锅汤”了。
下面就给大家介绍22个通过Python构建的项目,以此来学习Python编程。
那
一到动物园,弟弟就迫不及待地把车门打开了,飞快地冲了进去,我和妈妈紧随其后,也快步走入其中。动物园真大啊,里面住着各种各样的小动物。
最先映入眼帘的是一群可爱的小白兔,它们身体洁白得像一朵朵云似的,一对长长的耳朵竖在脑后,红红的眼睛像晶莹的宝石似的。看看这群小白兔,我的心都快被萌化了。它们一蹦一跳,好可爱!瞧,那边有只小白兔半眯着眼,全身蜷缩成一个小绒球,毛茸茸的,惹得我好想摸一摸。
逗完小白兔,我们又向熊猫馆走去。两只憨态可掬的熊猫相对而坐,张着小嘴似乎在说着什么悄悄话。过了一会儿,竟打起滚来,宛如两团黑白相间的绒球。见他们这副模样,我们开心地笑着,妈妈拿出相机,拍下了这美好的瞬间。
随后,我们还观赏了孔雀、老虎、大象等等,它们形态各异,我和弟弟都被它们吸引住了。动物的世界真有趣,着实令我们大开眼界。
这些例子都很简单实用,非常适合初学者用来练习。大家也可尝试根据项目的目的及提示,自己构建解决方法,提高编程水平。
那
一代文豪钱钟书,我们都知道他的文笔非常的好,他对服饰的研究也是相当的精彩,鲜为人知的是,他对生活中的事一概不知,他是一个连换灯泡都要依靠夫人的人。如果他不是充分发挥了他对文字的敏感的长处,而是去当一个生活类的学者,,我敢肯定,他一定不会有如此大的成就。再如张爱玲,几乎人人都知道她的小说写的非常的棒,但,你们知道吗?她是一个完全不会做饭的女人!她在美国四十五年的独居生活都是靠着吃面包和喝牛奶度过的!可见,她在生活上面也是一窍不通的。如果她只一味地去学怎样做一个持家的好女人,我想,她也就没有那种对周围生活的独特的观察力了,因为她的时间都花在学做饭上了,也就写不出那样脍炙人口的小说了,她也就不是现在人们眼中的张爱玲了。
在错的路上前进,就是一种后退。只有在正确的路上前进,才是一种进步。
中小学写作指导、写作素材、优秀作文以及有奖活动
① 骰子模拟器
那
在家里,弟弟给我起了一个外号,叫“倒霉蛋”,每次提起这个外号,我总是气得脸红脖子粗,但这个小家伙却笑得前仰后合,心想,为什么就因为最近一次洗完脸,为了展示自己的“毛巾功”,用毛巾把我打的疼痛难忍,就把俺叫做倒霉蛋,我又不是天天都倒霉,再说了,在幼儿园的小朋友照样把你也打过,你不也是倒霉蛋。但有一天,一件事验证了我俩都很倒霉。
暑假的一天,姥爷、姥姥、爸爸、妈妈、舅舅和舅妈带着我俩去老家玩,在老家的后院里,有一个坡,坡的旁边有棵大树,大树上绑了一根绳子,大人在房子里闲聊,我把弟弟叫过来,让他看看我发现了什么?弟弟一看,是一个坡,馊主意就出来了,他理直气壮说:“哥,你瞧,那棵树上有一根绳子,咱们可以顺着它爬到坡下,再上来呀,谁害怕,谁就没出息。”我想,哇塞!你有没有神经病,这样的坡度还让我爬,我可不会卖命的。但是弟弟的那双眼睛一直盯着我,我就勉强答应了,“小倒霉蛋”先闪亮登场,他小心翼翼的抓住绳子,然后左脚先跨上一步,再把右脚放在上面,很快,他像猴子一样的爬到了坡下,归我了,我请求弟弟让我做一个心理准备,幸亏这个“小领导”允许了,大约两分钟后,我鼓起勇气,但弟弟却在底下嬉皮笑脸的想看我的好戏,我不理他,进行自己的路程,一秒、两秒、三秒……过了20多秒,我终于下来了,当时我的心情很高兴,蹦来蹦去的,忽然,看见弟弟的脸上有许多豆豆,我想肯定是被蚊子叮了,我给弟弟说,弟弟还用陕西话给我回复:“别在这儿给我搞恶作剧,小心我让你再爬两个来回。”我只好闭上“乌鸦嘴”,现在该上去了,我又紧张的要命,弟弟又张开他的小嘴说了起来:“这次,你在前面我在后面,我可以在后面保护你,再说我身体肥胖,有点像猪,你稍微有点差错,我可以扶着你。”我心想,这家伙只会吹牛,说自己长的像猪,我看应该是长的是猪脑子,我一屁股都把他压下去了。开始第二段路程,我先锋,这回我很迅速,几下就完成任务,弟弟还边哼着小曲边爬,我也在上面嘲笑他,幸亏没被这家伙发现,最后我俩飞快的跑进了房间。
目的:创建一个程序来模拟掷骰子。
提示:当用户询问时,使用random模块生成一个1到6之间的数字。

② 石头剪刀布游戏
目标:创建一个命令行游戏,游戏者可以在石头、剪刀和布之间进行选择,与计算机PK。如果游戏者赢了,得分就会添加,直到结束游戏时,最终的分数会展示给游戏者。
提示:接收游戏者的选择,并且与计算机的选择进行比较。计算机的选择是从选择列表中随机选取的。如果游戏者获胜,则增加1分。
import random
choices = ["Rock", "Paper", "Scissors"]
computer = random.choice(choices)
player = False
cpu_score = 0
player_score = 0
while True:
player = input("Rock, Paper or Scissors?").capitalize()
# 判断游戏者和电脑的选择
if player == computer:
print("Tie!")
elif player == "Rock":
if computer ==
"Paper":
print("You lose!", computer, "covers", player)
cpu_score+=1
else:
print("You win!", player, "smashes", computer)
player_score+=1
elif player == "Paper":
if computer == "Scissors":
print("You lose!", computer, "cut", player)
cpu_score+=1
else:
print("You win!", player, "covers", computer)
player_score+=1
elif player == "Scissors":
if computer == "Rock":
print("You lose...", computer, "smashes", player)
cpu_score+=1
else:
print("You win!", player, "cut", computer)
player_score+=1
elif player=='E':
print("Final Scores:")
print(f"CPU:{cpu_score}")
print(f"Plaer:{player_score}")
break
else:
print("That's not a valid play. Check your spelling!")
computer = random.choice(choices)
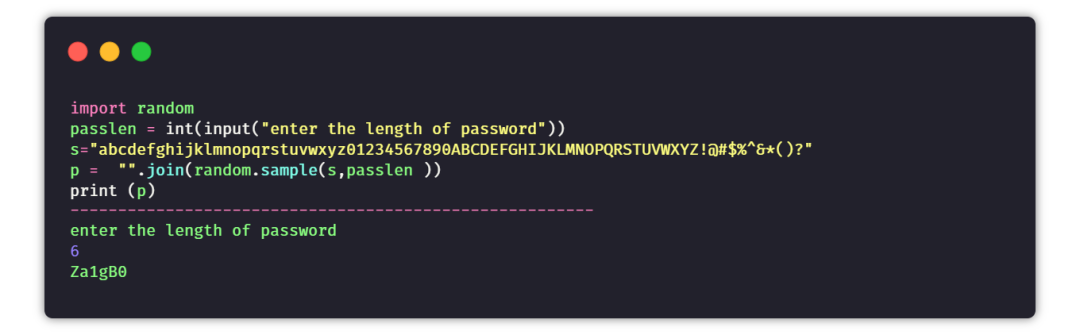
③ 随机密码生成器
目标:创建一个程序,可指定密码长度,生成一串随机密码。
提示:创建一个数字+大写字母+小写字母+特殊字符的字符串。根据设定的密码长度随机生成一串密码。
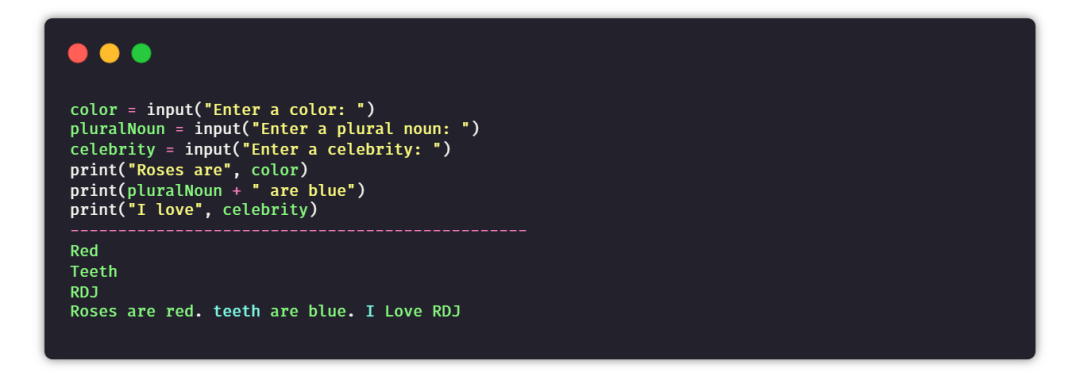
④ 句子生成器
目的:通过用户提供的输入,来生成随机且唯一的句子。
提示:以用户输入的名词、代词、形容词等作为输入,然后将所有数据添加到句子中,并将其组合返回。
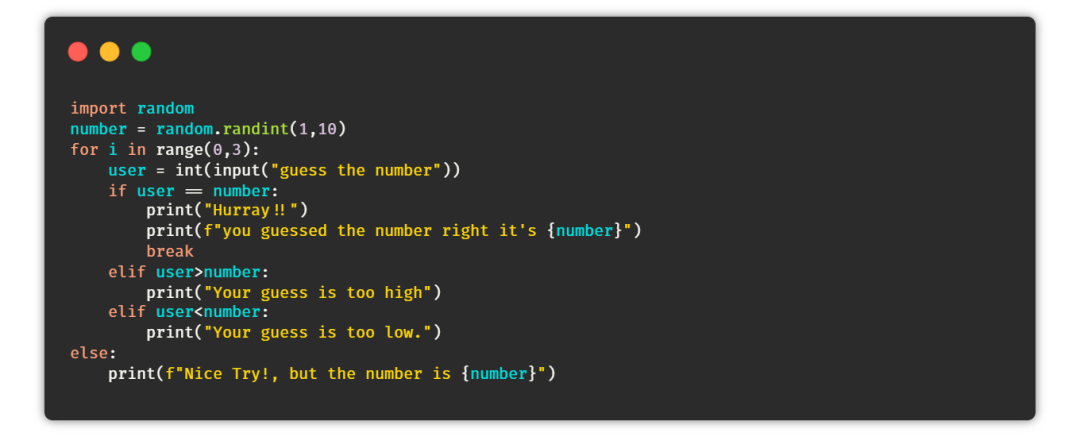
⑤ 猜数字游戏
目的:在这个游戏中,任务是创建一个脚本,能够在一个范围内生成一个随机数。如果用户在三次机会中猜对了数字,那么用户赢得游戏,否则用户输。
提示:生成一个随机数,然后使用循环给用户三次猜测机会,根据用户的猜测打印最终的结果。
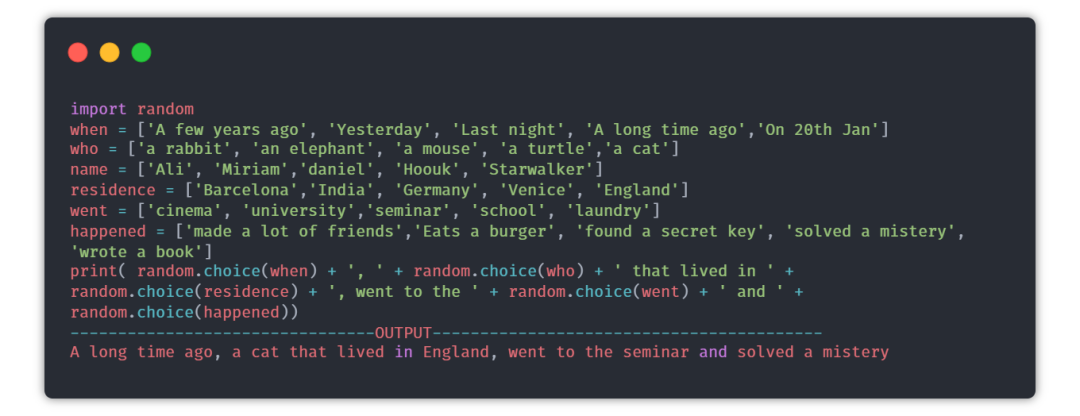
⑥
故事生成器
目的:每次用户运行程序时,都会生成一个随机的故事。
提示:random模块可以用来选择故事的随机部分,内容来自每个列表里。
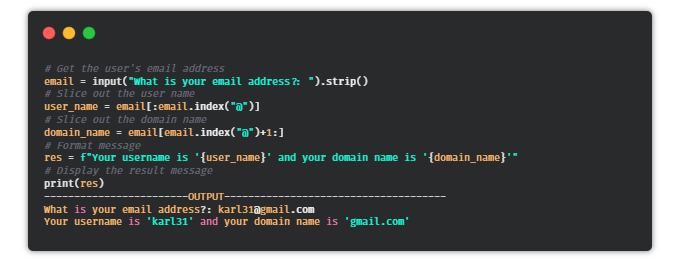
⑦ 邮件地址切片器
目的:编写一个Python脚本,可以从邮件地址中获取用户名和域名。
提示:使用@作为分隔符,将地址分为分为两个字符串。
⑧ 自动发送邮件
目的:编写一个Python脚本,可以使用这个脚本发送电子邮件。
提示:email库可用于发送电子邮件。
import smtplib
from email.message import EmailMessage
email = EmailMessage() ## Creating a object for EmailMessage
email['from'] = 'xyz name' ## Person who is sending
email['to'] = 'xyz id' ## Whom we are sending
email['subject'] = 'xyz subject' ## Subject of email
email.set_content("Xyz content of email") ## content of email
with smtlib.SMTP(host='smtp.gmail.com',port=587)as smtp:
## sending request to server
smtp.ehlo() ## server object
smtp.starttls() ## used to send data between server and client
smtp.login("email_id","Password") ## login id and password of gmail
smtp.send_message(email) ## Sending email
print("email send") ## Printing success message
⑨ 缩写词
目的:编写一个Python脚本,从给定的句子生成一个缩写词。
提示:你可以通过拆分和索引来获取第一个单词,然后将其组合。
⑩ 文字冒险游戏
目的:编写一个有趣的Python脚本,通过为路径选择不同的选项让用户进行有趣的冒险。
⑪ Hangman
目的:创建一个简单的命令行hangman游戏。
提示:创建一个密码词的列表并随机选择一个单词。现在将每个单词用下划线“_”表示,给用户提供猜单词的机会,如果用户猜对了单词,则将“_”用单词替换。
import time
import random
name = input("What is your name? ")
print ("Hello, " + name, "Time to play hangman!")
time.sleep(1)
print ("Start guessing...\n")
time.sleep(0.5)
## A List Of Secret Words
words = ['python','programming','treasure','creative','medium','horror']
word = random.choice(words)
guesses = ''
turns = 5
while turns > 0:
failed = 0
for char in word:
if char in guesses:
print (char,end="")
else:
print ("_",end=""),
failed += 1
if failed == 0:
print ("\nYou won")
break
guess = input("\nguess a character:")
guesses += guess
if guess not in word:
turns -= 1
print("\nWrong")
print("\nYou have", + turns, 'more guesses')
if turns == 0:
print ("\nYou Lose")
⑫ 闹钟
目的:编写一个创建闹钟的Python脚本。
提示:你可以使用date-time模块创建闹钟,以及playsound库播放声音。
from datetime import datetime
from playsound import playsound
alarm_time = input("Enter the time of alarm to be set:HH:MM:SS\n")
alarm_hour=alarm_time[0:2]
alarm_minute=alarm_time[3:5]
alarm_seconds=alarm_time[6:8]
alarm_period = alarm_time[9:11].upper()
print("Setting up alarm..")
while True:
now = datetime.now()
current_hour = now.strftime("%I")
current_minute = now.strftime("%M")
current_seconds = now.strftime("%S")
current_period = now.strftime("%p")
if(alarm_period==current_period):
if(alarm_hour==current_hour):
if(alarm_minute==current_minute):
if(alarm_seconds==current_seconds):
print("Wake Up!")
playsound('audio.mp3') ## download the alarm sound from link
break
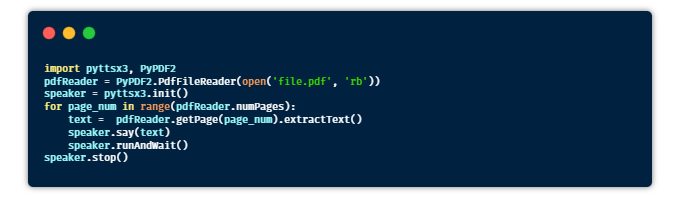
⑬ 有声读物
目的:编写一个Python脚本,用于将Pdf文件转换为有声读物。
提示:借助pyttsx3库将文本转换为语音。
安装:pyttsx3,PyPDF2
⑭ 天气应用
目的:编写一个Python脚本,接收城市名称并使用爬虫获取该城市的天气信息。
提示:你可以使用Beautifulsoup和requests库直接从谷歌主页爬取数据。
安装:requests,BeautifulSoup
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
def weather(city):
city=city.replace(" ","+")
res = requests.get(f'https://www.google.com/search?q={city}&oq={city}&aqs=chrome.0.35i39l2j0l4j46j69i60.6128j1j7&sourceid=chrome&ie=UTF-8',headers=headers)
print("Searching in google......\n")
soup = BeautifulSoup(res.text,'html.parser')
location = soup.select('#wob_loc')[0].getText().strip()
time = soup.select('#wob_dts')[0].getText().strip()
info = soup.select('#wob_dc')[0].getText().strip()
weather = soup.select('#wob_tm')[0].getText().strip()
print(location)
print(time)
print(info)
print(weather+"°C")
print("enter the city name")
city=input()
city=city+" weather"
weather(city)
⑮ 人脸检测
目的:编写一个Python脚本,可以检测图像中的人脸,并将所有的人脸保存在一个文件夹中。
提示:可以使用haar级联分类器对人脸进行检测。它返回的人脸坐标信息,可以保存在一个文件中。
安装:OpenCV。
下载:haarcascade_frontalface_default.xml
https://raw.githubusercontent.com/opencv/opencv/master/data/haarcascades/haarcascade_frontalface_default.xml
import cv2
# Load the cascade
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# Read the input image
img = cv2.imread('images/img0.jpg')
# Convert into grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Detect faces
faces = face_cascade.detectMultiScale(gray, 1.3, 4)
# Draw rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
crop_face = img[y:y + h, x:x + w]
cv2.imwrite(str(w) + str(h) + '_faces.jpg', crop_face)
# Display the output
cv2.imshow('img', img)
cv2.imshow("imgcropped",crop_face)
cv2.waitKey()
⑯ 提醒应用
目的:创建一个提醒应用程序,在特定的时间提醒你做一些事情(桌面通知)。
提示:Time模块可以用来跟踪提醒时间,toastnotifier库可以用来显示桌面通知。
安装:win10toast
from win10toast import ToastNotifier
import time
toaster = ToastNotifier()
try:
print("Title of reminder")
header = input()
print("Message of reminder")
text = input()
print("In how many minutes?")
time_min = input()
time_min=float(time_min)
except:
header = input("Title of reminder\n")
text = input("Message of remindar\n")
time_min=float(input("In how many minutes?\n"))
time_min = time_min * 60
print("Setting up reminder..")
time.sleep(2)
print("all set!")
time.sleep(time_min)
toaster.show_toast(f"{header}",
f"{text}",
duration=10,
threaded=True)
while toaster.notification_active(): time.sleep(0.005)
⑰ 维基百科文章摘要
目的:使用一种简单的方法从用户提供的文章链接中生成摘要。
提示:你可以使用爬虫获取文章数据,通过提取生成摘要。
from bs4 import BeautifulSoup
import re
import requests
import heapq
from nltk.tokenize import sent_tokenize,word_tokenize
from
nltk.corpus import stopwords
url = str(input("Paste the url"\n"))
num = int(input("Enter the Number of Sentence you want in the summary"))
num = int(num)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
#url = str(input("Paste the url......."))
res = requests.get(url,headers=headers)
summary = ""
soup = BeautifulSoup(res.text,'html.parser')
content = soup.findAll("p")
for text in content:
summary +=text.text
def clean(text):
text = re.sub(r"\[[0-9]*\]"," ",text)
text = text.lower()
text = re.sub(r'\s+'," ",text)
text = re.sub(r","," ",text)
return text
summary = clean(summary)
print("Getting the data......\n")
##Tokenixing
sent_tokens = sent_tokenize(summary)
summary = re.sub(r"[^a-zA-z]"," ",summary)
word_tokens = word_tokenize(summary)
## Removing Stop words
word_frequency = {}
stopwords = set(stopwords.words("english"))
for word in word_tokens:
if word not in stopwords:
if word not in word_frequency.keys():
word_frequency[word]=1
else:
word_frequency[word] +=1
maximum_frequency = max(word_frequency.values())
print(maximum_frequency)
for word in word_frequency.keys():
word_frequency[word] = (word_frequency[word]/maximum_frequency)
print(word_frequency)
sentences_score = {}
for sentence in sent_tokens:
for word in word_tokenize(sentence):
if word in word_frequency.keys():
if (len(sentence.split(" "))) <30:
if sentence not in sentences_score.keys():
sentences_score[sentence] = word_frequency[word]
else:
sentences_score[sentence] += word_frequency[word]
print(max(sentences_score.values()))
def get_key(val):
for key, value in sentences_score.items():
if val == value:
return key
key = get_key(max(sentences_score.values()))
print(key+"\n")
print(sentences_score)
summary = heapq.nlargest(num,sentences_score,key=sentences_score.get)
print(" ".join(summary))
summary = " ".join(summary)
⑱ 获取谷歌搜索结果
目的:创建一个脚本,可以根据查询条件从谷歌搜索获取数据。
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
def google(query):
query = query.replace(" "
,"+")
try:
url = f'https://www.google.com/search?q={query}&oq={query}&aqs=chrome..69i57j46j69i59j35i39j0j46j0l2.4948j0j7&sourceid=chrome&ie=UTF-8'
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
except:
print("Make sure you have a internet connection")
try:
try:
ans = soup.select('.RqBzHd')[0].getText().strip()
except:
try:
title=soup.select('.AZCkJd')[0].getText().strip()
try:
ans=soup.select('.e24Kjd')[0].getText().strip()
except:
ans=""
ans=f'{title}\n{ans}'
except:
try:
ans=soup.select('.hgKElc')[0].getText().strip()
except:
ans=soup.select('.kno-rdesc span')[0].getText().strip()
except:
ans = "can't find on google"
return ans
result = google(str(input("Query\n")))
print(result)
获取结果如下。
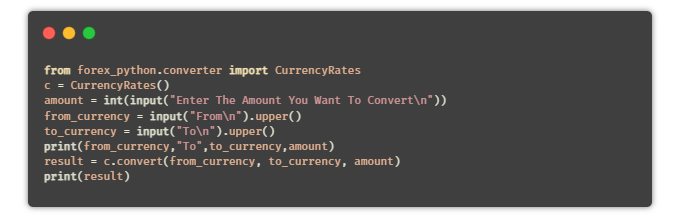
⑲ 货币换算器
目的:编写一个Python脚本,可以将一种货币转换为其他用户选择的货币。
提示:使用Python中的API,或者通过forex-python模块来获取实时的货币汇率。
安装:forex-python
⑳ 键盘记录器
目的:编写一个Python脚本,将用户按下的所有键保存在一个文本文件中。
提示:pynput是Python中的一个库,用于控制键盘和鼠标的移动,它也可以用于制作键盘记录器。简单地读取用户按下的键,并在一定数量的键后将它们保存在一个文本文件中。
from pynput.keyboard import Key, Controller,Listener
import time
keyboard = Controller()
keys=[]
def on_press(key):
global keys
#keys.append(str(key).replace("'",""))
string = str(key).replace("'","")
keys.append(string)
main_string = "".join(keys)
print(main_string)
if len(main_string)>15:
with open('keys.txt', 'a') as f:
f.write(main_string)
keys= []
def on_release(key):
if key == Key.esc:
return False
with listener(on_press=on_press,on_release=on_release) as listener:
listener.join()
㉑ 文章朗读器
目的:编写一个Python脚本,自动从提供的链接读取文章。
import pyttsx3
import requests
from bs4 import BeautifulSoup
url = str(input("Paste article url\n"))
def content(url):
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
articles = []
for i in range(len(soup.select('.p'))):
article = soup.select('.p')[i].getText().strip()
articles.append(article)
contents = " ".join(articles)
return contents
engine = pyttsx3.init('sapi5')
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[0].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
contents = content(url)
## print(contents) ## In case you want to see the content
#engine.save_to_file
#engine.runAndWait() ## In case if you want to save the article as a audio file
㉒ 短网址生成器
目的:编写一个Python脚本,使用API缩短给定的URL。
from __future__ import with_statement
import contextlib
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
try:
from urllib.request import urlopen
except ImportError:
from urllib2 import urlopen
import sys
def make_tiny(url):
request_url = ('http://tinyurl.com/api-create.php?' +
urlencode({'url':url}))
with contextlib.closing(urlopen(request_url)) as response:
return response.read().decode('utf-8')
def main():
for tinyurl in map(make_tiny, sys.argv[1:]):
print(tinyurl)
if __name__ == '__main__':
main()
-----------------------------OUTPUT------------------------
python url_shortener.py https://www.wikipedia.org/
https://tinyurl.com/buf3qt3
以上就是今天分享的内容。
总结:
项目中有些需要适当调整。比如自动发送邮件,可以选择使用QQ邮箱;查询天气信息也可使用国内一些免费的API;维基百科可以对应百度百科;谷歌搜索可以对应百度搜索等等。
那
我渐渐接受了自己做饭的事实,并勤劳地干了起来。起初还挺轻松,过了一会儿,活越来越多,跑东跑西,跑南跑北,像“小二”一样。渐渐地跑来跑去的力气都没有了。在地上,伸长舌头,头上直冒热汗,上气不接下气,差点气得我当场“去世”,气不打一处来,直接不干了。
刚走去,一位同学就来了。他稳重地说:“相信我,我要凉拌。”虽然我不相信,但看着他那自信而又坚定的眼神,好像有一个无形的力量拖着我的手,让我帮他切黄瓜。“拍拍拍。”一阵阵削铁如泥的刀声从碟子上传出来,正是那即无形又大力的力量切的。
“咕咚咕咚。”我惊讶了,一瓶又大又多又黑的醋他竟然径直地倒了下去,我用一种看科学怪人在倒材料的眼神看他。
一波未平,一波又起。我就走开了几秒钟,半瓶醋倒了下去。这,难道不是黑暗料理吗?我们实在是很好奇,便尝了一口,“呕”这味道,正如柠檬一样,酸到爆炸。
这些都是大家在运行过程中需要注意的。
如有文章对你有帮助,
“在看”和转发是对我最大的支持!

关注Python极客专栏






