1 简介
就在几天前,著名的机器学习框架scikit-learn在pypi上释放了其1.0rc1版本,这里给大家科普一下,版本号中的rc是Release Candidate的简称,代表当前的版本是一个候选发布版本,一旦到了这个阶段,scikit-learn对于1.0版本的开发设计就基本上不会再新增功能,而是全力投入到查缺补漏的测试中去也就意味着:
❝经历了十余年的开发进程,scikit-learn即将迎来其颇具里程碑意义的一次大版本发布!
❞

在这次大版本更新中,scikit-learn也很有诚意地带来了诸多新特性,下面我们就来对其中一些关键性的内容进行简单的介绍。
2 scikit-learn 1.0 版本重要特性一览
2.1 强制要求使用关键词参数传参
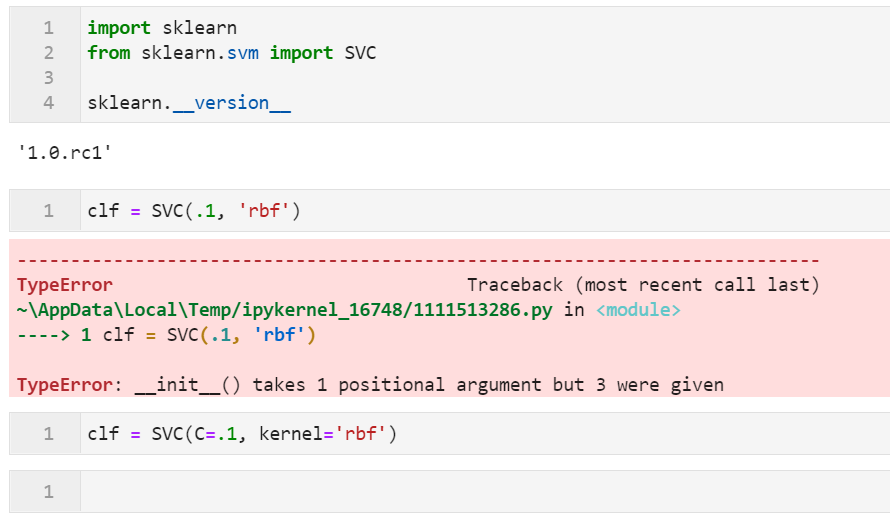
按照scikit-learn官方的说法,为了更加清楚明确地构建机器学习代码,在之后的版本中,绝大部分API都将逐渐转换为强制使用「关键词参数」,使用「位置参数」则会直接抛出TypeError错误,以SVC为例:
2.2 新增r_regression()
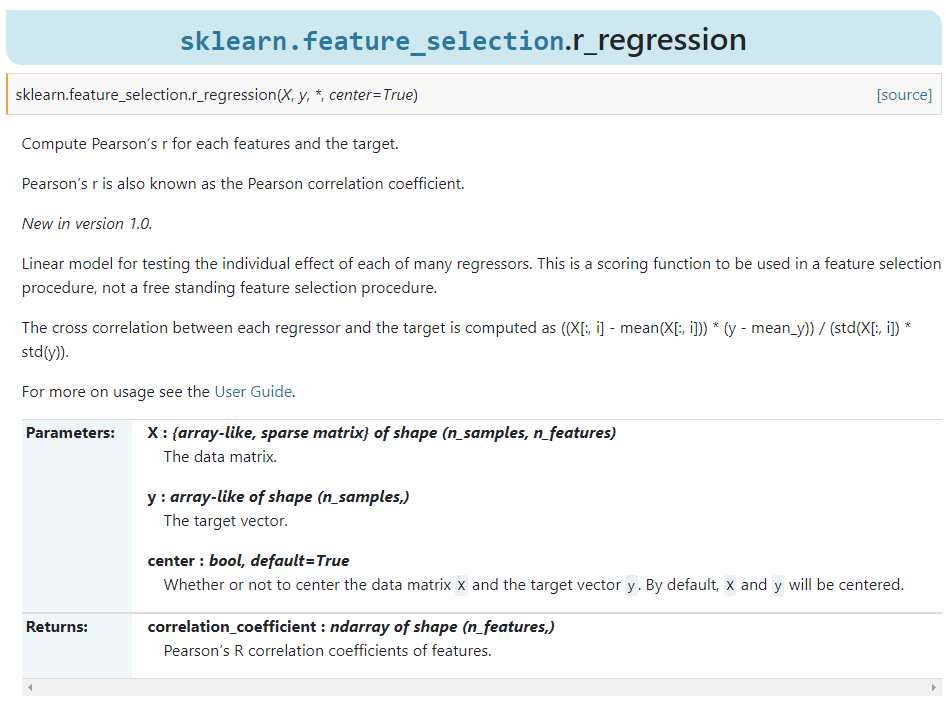
在新版本中新增了sklearn.feature_selection.r_regression(),可以用来快速计算各个自变量与因变量之间的皮尔逊简单相关系数来辅助特征工程过程。
2.3 新增线性分位数回归模型QuantileRegressor()
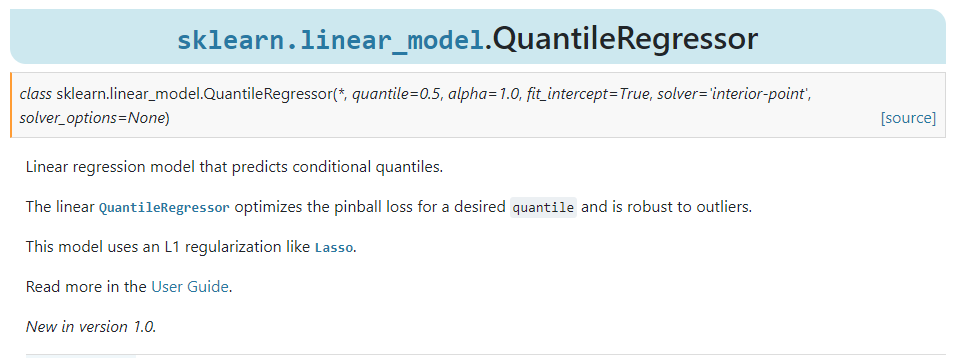
新版本中在sklearn.linear_model下添加了线性分位数回归模型QuantileRegressor(),可用于构建回归模型由自变量求出因变量的条件分位数,近年来在计量经济学中应用广泛。
2.4 新增基于随机梯度下降的OneClassSvm模型
在sklearn.linear_model中新增了基于随机梯度下降法的异常检测模型SGDOneClassSVM():

2.5 带交叉验证的Lasso回归与ElasticNet新增sample_weight参数
为sklearn.linear_model中的LassoCV()与ElasticNetCV()新增参数sample_weight,可帮助我们在模型建立的过程中通过构建权重提升部分样本的重要性。
2.6 为分位数回归模型新增模型性能度量指标
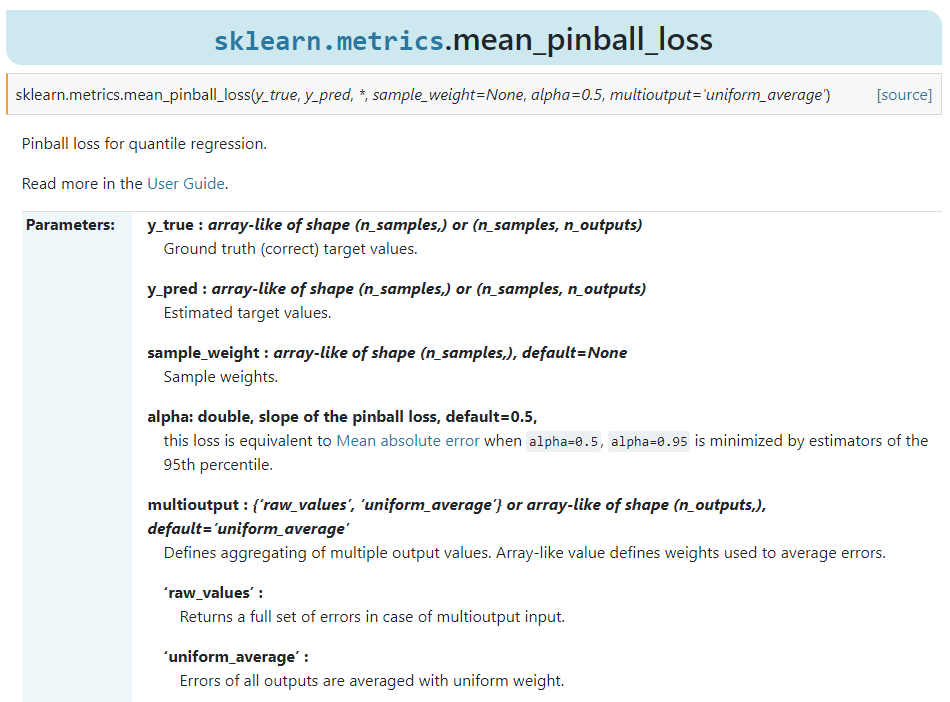
伴随着新的分位数回归模型,scikit-learn也顺势新增了专门用于度量分位数回归模型性能的Pinball loss系数:
2.7 模型选择新增StratifiedGroupKFold()
新版中将sklearn.model_selection中常用的StratifiedKFold()与GroupKFold()进行结合,使得我们可以快速构建分层分组K折交叉验证流程,详情参考:https://scikit-learn.org/dev/modules/generated/sklearn.model_selection.StratifiedGroupKFold.html#sklearn.model_selection.StratifiedGroupKFold
2.8 KMeans聚类中的k-means++初始化方法运算速度提升
新版本中cklearn.cluster中常用的KMeans()与MiniBatchKMeans()聚类模型,在默认的k-means++簇心初始化方法下运算速度获得大幅度提高,尤其是在多核机器上表现更佳。
2.9 多项式&交互项特征生成速度提升
新版本中sklearn.preprocessing中用于快速合成多项式&交互项特征的PolynomialFeatures()的运算速度更快了,且在输入为大型稀疏特征时效果更为明显。
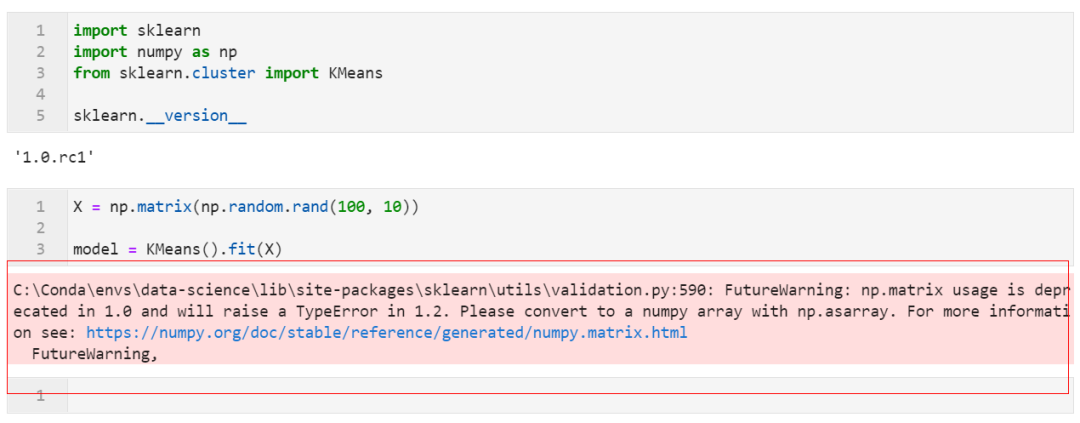
2.10 np.matrix型输入即将弃用
从1.0版本开始,scikit-learn中的各种算法模型在接受numpy中的matrix类型输入时,会打印「弃用警告」,且从未来的1.2
版本开始,当用户输入np.matrix类型时将会直接报错:
2.11 利用feature_names_in_获取pandas数据框输入下的特征名称
当输入的特征为pandas中的DataFrame类型时,对于训练好的模型,可以使用feature_names_in_属性获取到对应输入特征的字段名称:

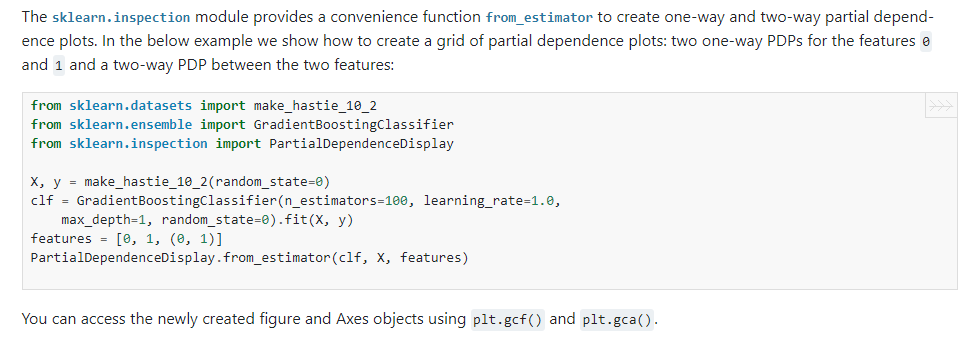
2.12 绘制局部依赖图的方式变化
在我们试图对模型进行解释时,局部依赖图是一个比较经典的工具,在以前的版本中我们可以使用sklearn.inspection中的plot_partial_dependence()来绘制局部依赖图,而在新版本中将会弃用这种方式,并且在1.2版本开始正式移除这个API,新的替代方案是使用sklearn.inspection.PartialDependenceDisplay的from_estimator():
除了这些之外,在scikit-learn新版本中还有众多的细碎的更新与调整内容,感兴趣的朋友可以前往https://scikit-learn.org/dev/whats_new/v1.0.html自行浏览学习。
以上就是本文的全部内容,欢迎在评论区与我进行讨论。







