前文中,我们已经介绍了如何接入、转换和存储数据。但是此时的数据依旧千头万绪,并没有清晰地表带出其中的含义。例如,这些数据可能存在缺失,或者有噪音有偏差,或者并不是全部的数据。所以,为了能够更好的理解数据,我们还需要清洗数据。这样才能更加有效地构建机器学习模型。这就是本文要介绍的内容。
1.利用描述性统计(Descriptive Statistics)更好的理解数据
在清洗数据之前,我们需要做的第一件事就是利用描述性统计更好地理解数据。描述性统计可以帮助我们洞察数据,更加有效的预处理数据,为机器学习模型做好准备。通常,描述性统计可以分为以下一些类型。
总体统计(Overall Statistics):包括数据的行列数。由于这些信息和数据的维度有关,所以很重要。例如,从其中可以看出数据是否有过多的特征。这就说明有高维度的问题,会导致模型表现变差。
多元统计(Multivariate Statistics):是指变量之间的相关性。这个我们在后面还会详细介绍。
特征统计(Attribute Statistics):这个主要针对数值型变量,包括平均值、标准差、方差、最大值和最小值等参数。
2. 多元统计
2.1相关性
由于数据之间的相关性会影响模型表现,所以发现这些相关性很重要。在有多个变量或者特征(Features)的时候,我们需要查看这些变量之间的相关性。如果两个变量之间的相关性很高,就会影响模型的表现。当变量之间的相关性过高,且应用于同一模型预测某一反映变量(Response Variable),就会带来问题。例如,模型的损失不收敛。所以,我们要注意数据中那些高度相关的变量。
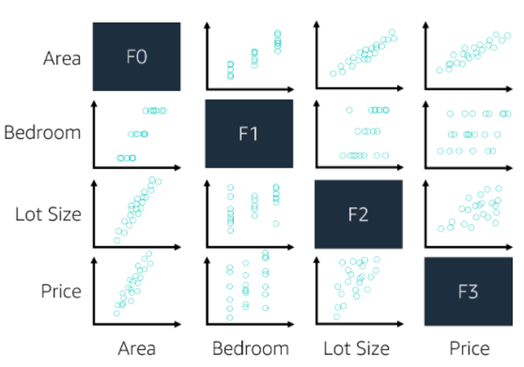
2.2散点图
我们可以利用散点图直观地表现数值型变量的关系。当一个数据集中有两个以上数值型变量的时候,我们可以用散点图画出它们的关系。这样就可以发现变量之间的特殊关系。例如,在下图中,我们可以看出,有一些变量之间具有强线性关系,而另一些变量之间则没有强线性关系。
2.3相关性矩阵
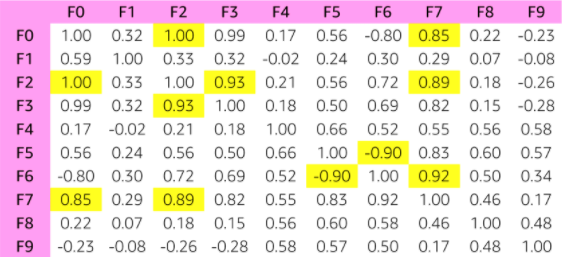
尽管散点图可以直观的展示出变量之间的关系,但是如何量化变量之间的线性关系呢?这就需要用到相关性矩阵。它可以定量地表达变量之间的线性关系,说明线性相关性的强弱。
相关性介于-1和+1之间。当相关性为+1时,说明两个变量之间完全正相关。或者可以说,变量Y和变量X同比例变化。当相关性为-1时,说明两个变量之间完全负相关。或者可以说,变量Y和变量X反比例变化。介于-1和+1之间的线性关系也可以用量化表达。如果相关性为0,则说明变量之间没有相关性。但是要特别强调,没有相关性并不代表没有关系。这里只是说这两个变量之间没有线性关系。
3.清洗数据
在理解了数据之后,我们可以开始清洗数据了。下面就来介绍这些内容。
3.1 标准化语言和语法
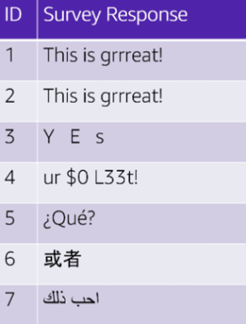
杂乱无章的数据有很多种形式。例如,我们的模型要求数据是英语,但事实上数据有很多种语言。而且可能还会有特殊字符、空格和乱码。因此,我们要对数据进行标注化操作。如果我们的模型要求是英语,那么就要确保数据是英语。
语法也有同样的问题。例如,我们可以把文本文件都改成小写字母。这样首字母大写和小写就没有区别了。
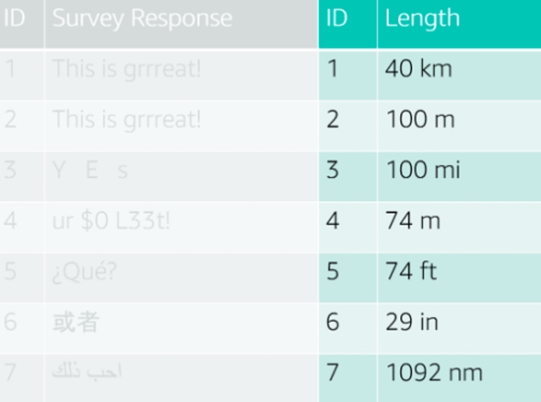
3.2 统一数据单位
数据中可能还会有单位的问题。例如长度可能是米,千米,英里等。这是一个常见问题,因为很多数据来源不同。当合并不同的数据集以后,就会出现这个问题。
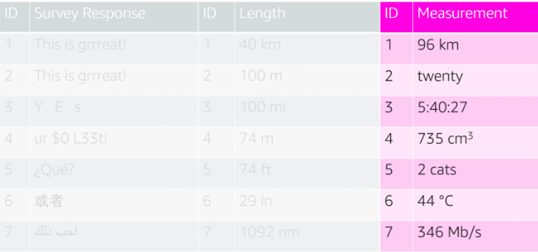
3.3每一列只有一个特征
有时数据的问题会更加复杂。一列数据可能会包括不同的特征。例如同样是叫做测量值(Measurement)的一列,里面可能有温度,距离,时间等等数值。这种情况下,就要对数据变形,使每一列对应一个特征。
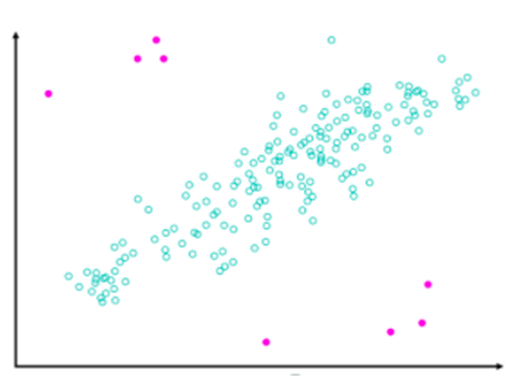
3.4异常值(Outlier)
另一个需要解决的是异常值问题。通常,数据中的异常值明显远离其他数据。由于这些数据包含了大量的信息,所以我们并不一定需要清洗它们。但是,它们的偏离会影响预测精度。因此,我们还是要注意这些异常值。
3.5缺失值
数据中总会有缺失值。例如,由于采集数据出错,数据中的某一列缺失。缺失值会增加解释数据关系的难度。因此,我们总要想办法解决缺失值。常用的办法包括
删除含有缺失值的行或列。
用平均值,0或者其他值代替缺失值。
但是这些方法也不是完美的,所以要针对对待缺失值的问题。总的来说,如果数据集比较小,不能删除数据,就只能选择一种替代缺失值的办法。这个被称为插补技术(Imputation Techniques)。








