要理解我们如何缩小模型,就要先理解模型文件如何被压缩。如下图所示,一个常见的 DNN 模型由神经元和它们之间的连接构成,模型的大小主要就是由这些 weights 构成。一个简单的 CNN 都有上百万的参数,我们知道训练的时候,它们的 dtype 都是 float 32,一个 float 32 占4个字节,上百万的参数往往就占据几十兆的空间大小。几十兆的模型?我们可能觉得这已经很小了,但是一个微型处理器就只有 256 Kb 的随机存储器。
为了把模型缩小到可以塞到这么小的处理器中,有以下几个框架:
- TensorFlow Lite from Google
- PyTorch Mobile from Facebook
tensorflow 提供一个 python 库 tensorflow_model_optimization,这个库优化模型的延迟,大小。直观上,优化模型大小,一个就是优化参数的数量,另一个就是优化每个参数的大小。主要的方式就是以下几种。
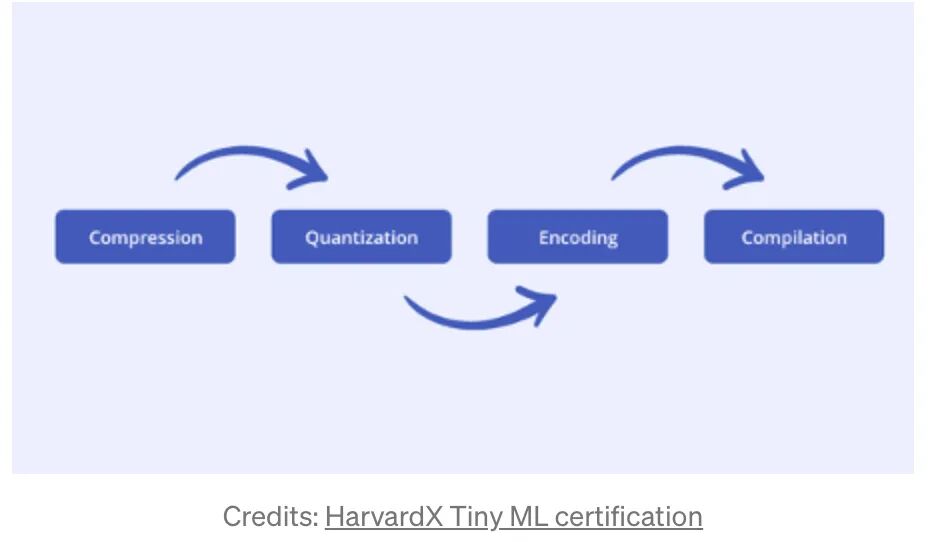
Compression or Distillation
模型训练完成后,如何在准确率可接受的情况下压缩模型,最常见的方式就是剪枝和蒸馏。
剪枝-删除对输出影响较低或者可能会引起过拟合的weights,再剪枝后稀疏的神经网络需要重新被训练。蒸馏炼丹师都比较熟悉了,用小模型去学习打模型即可。
Quantisation
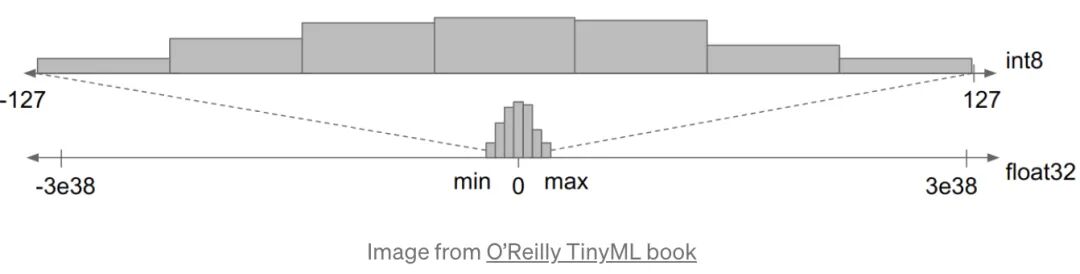
该方法用低精度的参数去学习一个同样效果的模型,这种方式提升了模型的处理能力和效率。这种方法主要是把 float 压缩到 int 8 上,如下图所示:
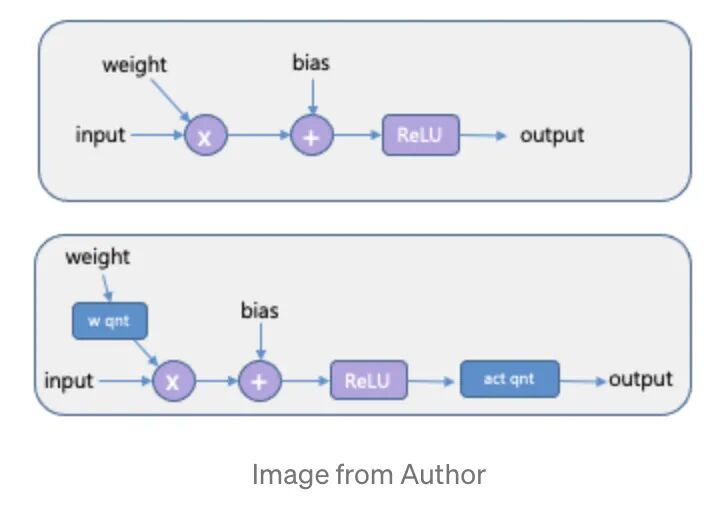
Quantisation Aware Training(QAT)这个方式是在模型训练过程中使用量化,如下图所示,该方法会带来噪声也会影响 loss,所以学到的模型更加鲁棒。
Post-Training Quantisation (PTQ) 该方法不用重训练模型,直接把float32量化到int8,这样直接把模型大小降低了4倍,预估性能也提升了两倍,精度也没有显著下降。
weight clustering 使用权重聚类/共享,降低了存储参数的数量,该方法把一层的参数聚成N个类,并共享索引,举例来说,如果我们把一层聚成8个类,每个参数都会只占 3bit(2^3 = 8)。从实验我们可以看到,使用该方法可以降低模型大小6倍,仅仅降低了0。6%的准确率。我们还可以通过 fine-tune 聚类的中心点,来提升模型精度。
 Encoding
Encoding
通过使用霍夫曼编码对模型进行压缩,使用01编码 weights,把最常出现的权重用较少的 bit 去编码,如下图所示,我们有已经被量化的权重矩阵:
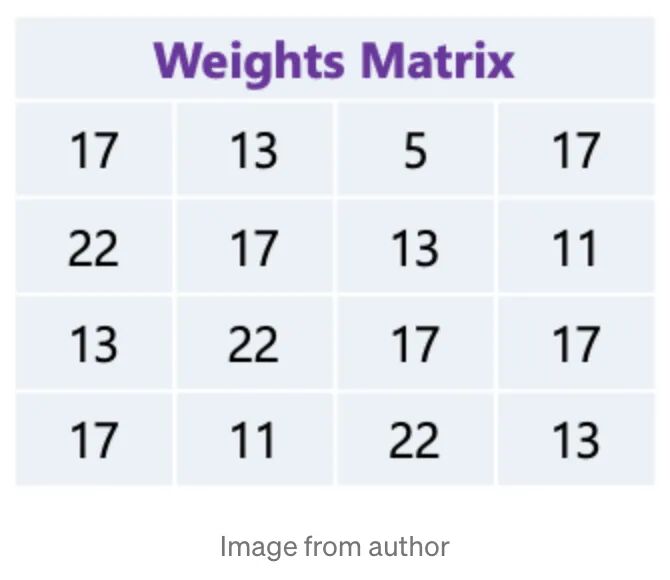
每个权重占5bit(0~31),如果使用霍夫曼编码,我们就会得到下面这颗树:
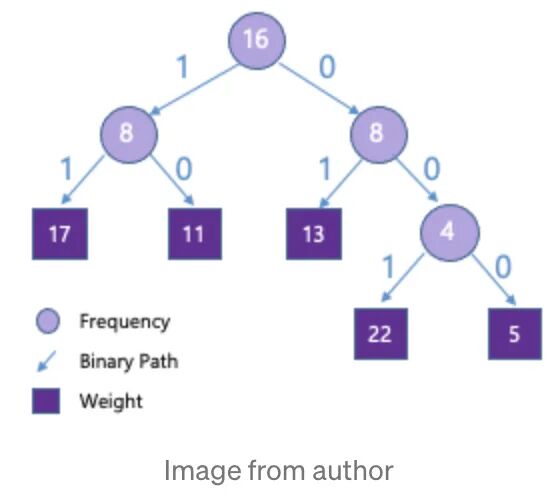
17会被编码成11,22编码为001,可以看到权重通过编码显著被压缩。
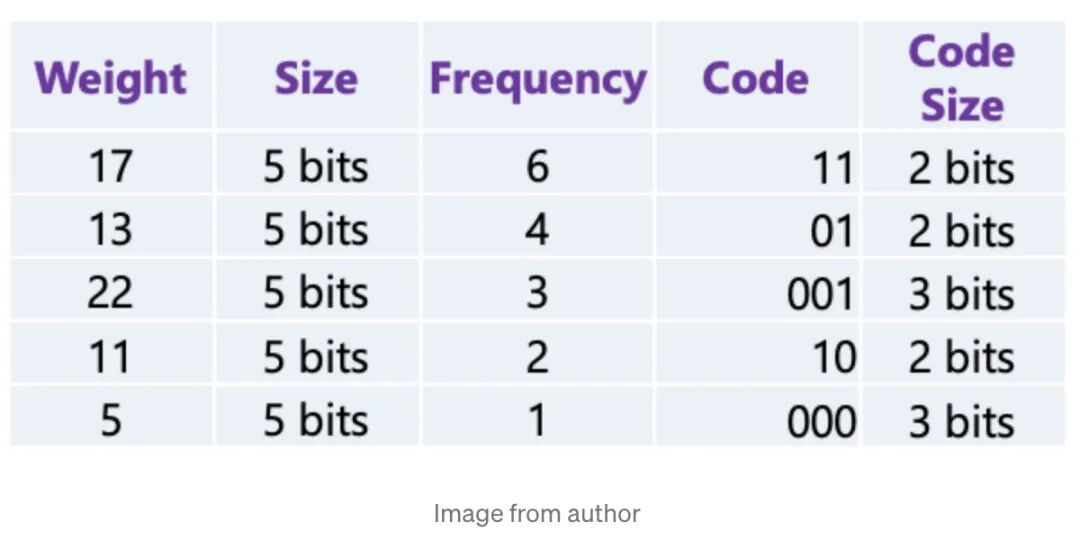
Compilation
剩下的就是工程上的优化了,如使用C++,相较于python更快更省内存。
参考文献
1.https://github.com/quic/aimet2.https://www.tensorflow.org/lite
3.https://developer.apple.com/documentation/coreml4.https://pytorch.org/mobile/home/5.https://medium.com/marionete/tinyml-models-whats-happening-behind-the-scenes-5e61d1555be9
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:极市平台









