今天详解一个 Python 库 Streamlit,它可以为机器学习和数据分析构建 web app。它的优势是入门容易、纯 Python 编码、开发效率高、UI精美。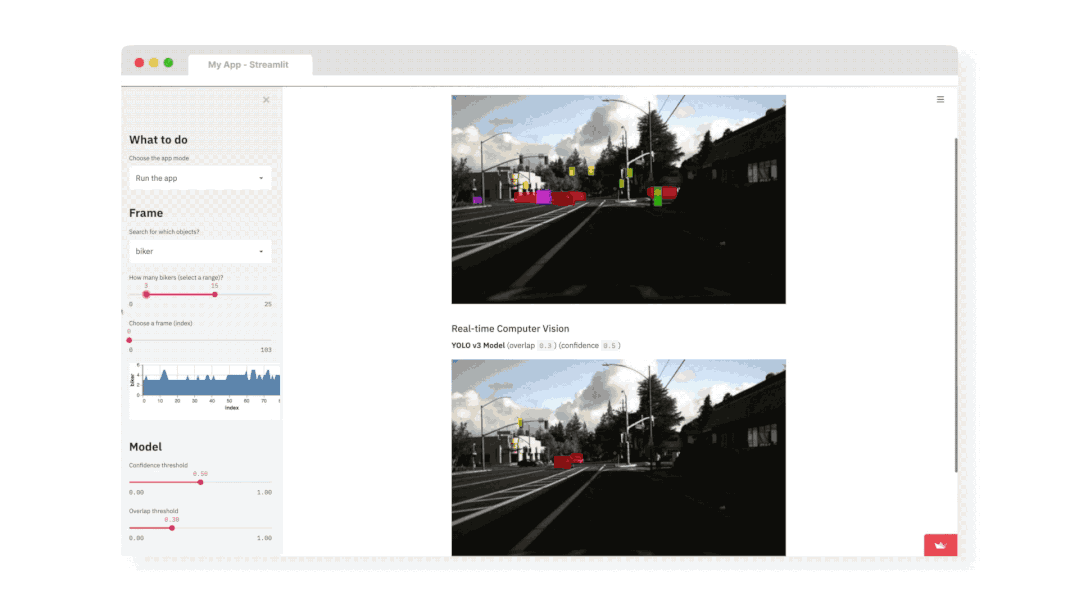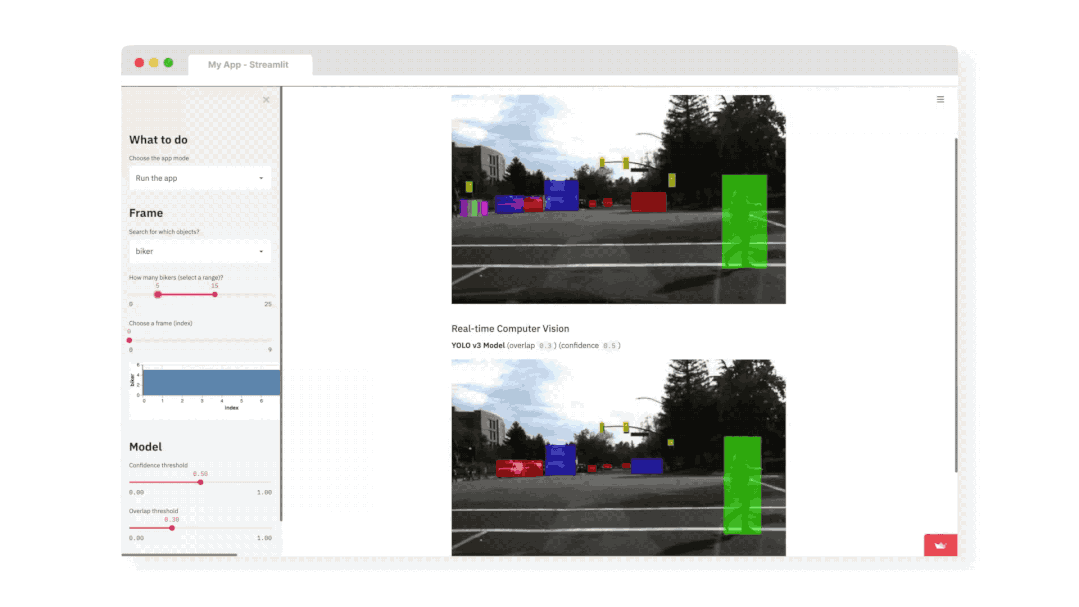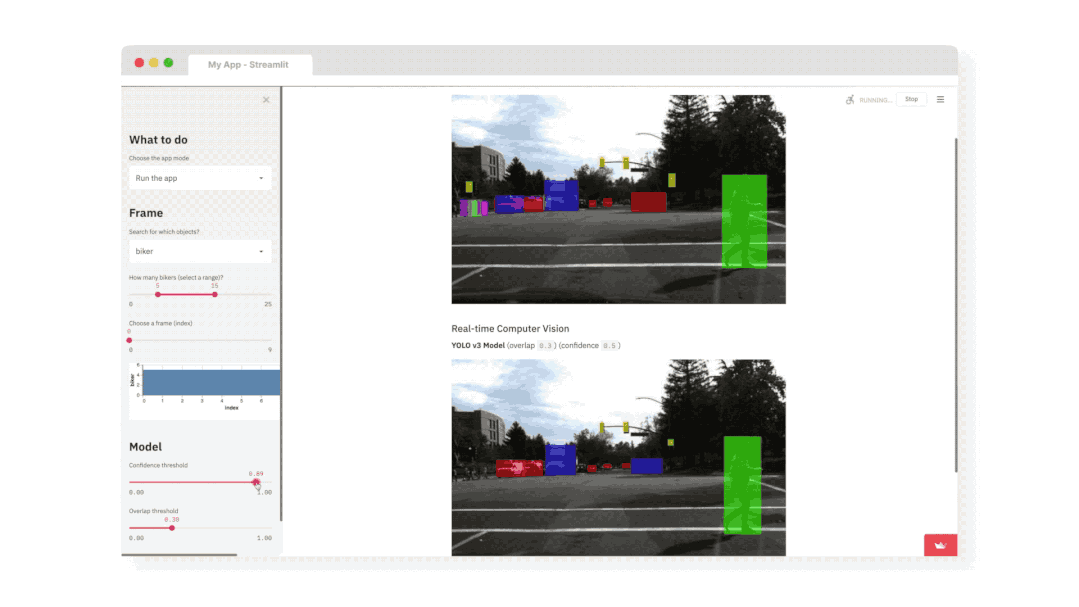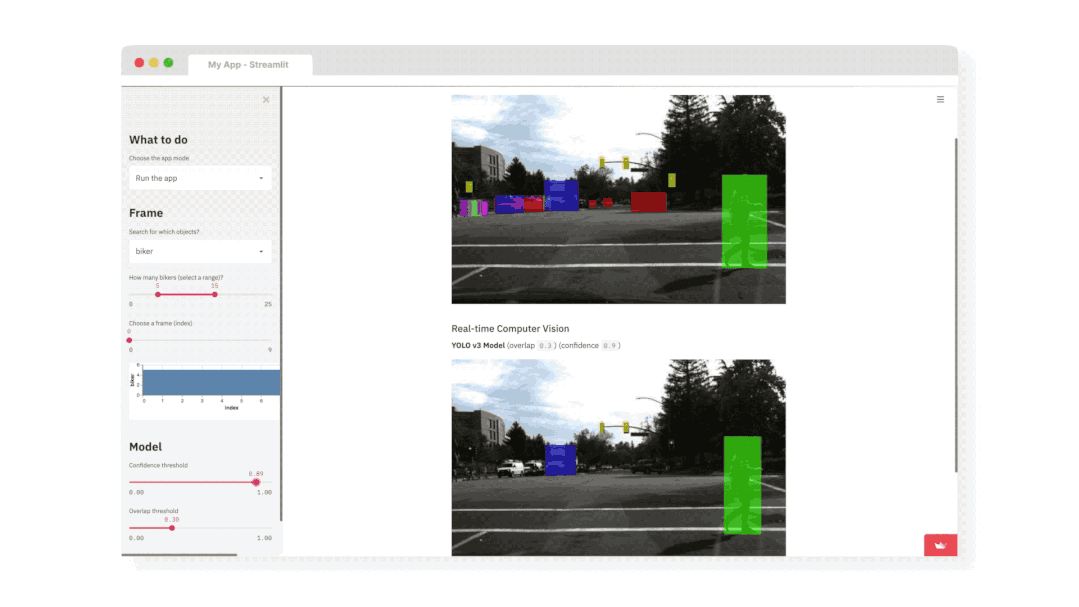
上图是用 Streamlit 构建自动驾驶模型效果的 demo,左侧是模型的参数,右侧是模型的效果。通过调整左侧参数,右边的模型会实时地响应。
由此可以看出,对于交互式的数据可视化需求,完全可以考虑用 Streamlit 实现。特别是在学习、工作汇报的时候,用它的效果远好于 PPT。
因为 Streamlit 提供了很多前端交互的组件,所以也可以用它来做一些简单的web 应用。今天我们也会用它来做个垃圾分类的 web app。
今天我们就按照 Streamlit 官网文档,对其做个详解。我使用的是 Python 3.8 环境,执行 pip install streamlit 安装。安装后执行 streamlit hello 检查是否安装成功。先来了解下 Streamlit 最基础的文本组件。
文本组件是用来在网页展示各种类型的文本内容。Streamlit 可以展示纯文本、Markdown、标题、代码和LaTeX公式。
import streamlit as st
# markdown
st.markdown('Streamlit is **_really_ cool**.')
# 设置网页标题
st.title('This is a title')
# 展示一级标题
st.header('This is a header')
# 展示二级标题
st.subheader('This is a subheader')
# 展示代码,有高亮效果
code = '''def hello():
print("Hello, Streamlit!")'''
st.code(code, language='python')
# 纯文本
st.text('This is some text.')
# LaTeX 公式
st.latex(r'''
a + ar + a r^2 + a r^3 + \cdots + a r^{n-1} =
\sum_{k=0}^{n-1} ar^k =
a \left(\frac{1-r^{n}}{1-r}\right)
''')
上述是 Streamlit 支持的文本展示组件,代码存放 my_code.py 文件中。编码完成后,执行 streamlit run my_code.py ,streamlit 会启动 web 服务,加载指定的源文件。
streamlit run garbage_classifier.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.10.141:8501
在浏览器访问 http://localhost:8501/ 即可。当源代码被修改,无需重启服务,在页面上点击刷新按钮就可加载最新的代码,运行和调试都非常方便。dataframe 和 table 组件可以展示表格。
import streamlit as st
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.random.randn(50, 5),
columns=('col %d' % i for i in range(5)))
# 交互式表格
st.dataframe(df)
# 静态表格
st.table(df)
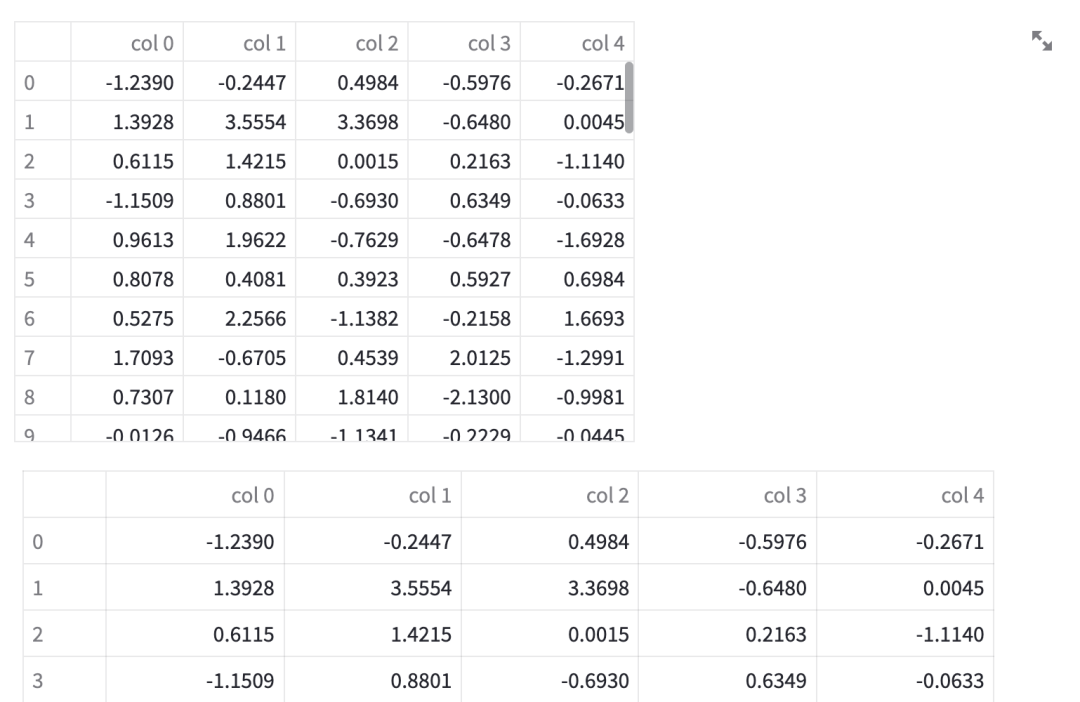
dateframe 和 table 的区别是,前者可以在表格上做交互(如:排序),后者只是静态的展示。它们支持展示的数据类型包括 pandas.DataFrame、pandas.Styler、pyarrow.Table、numpy.ndarray、Iterable、dict。metric 组件用来展示指标的变化,数据分析中经常会用到。
st.metric(label="Temperature", value="70 °F", delta="1.2 °F")

value 参数表示当前指标值,delta 参数表示与前值的差值,向上的绿色箭头代表相比于前值,是涨的,反之向下的红箭头代表相比于前值是跌的。当然涨跌颜色可以通过 delta_color 参数来控制。
st.json({
'foo': 'bar',
'stuff': [
'stuff 1',
'stuff 2',
],
})
Streamlit 会将 json 数据格式化,展示地更美观,并且提供交互,可以展开、收起 json 的子节点。Streamlit 的图表组件包含两部分,一部分是原生组件,另一部分是渲染第三方库。原生组件只包含 4 个图表,line_chart、area_chart 、bar_chart 和 map,分别展示折线图、面积图、柱状图和地图。
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns=['a', 'b', 'c'])
st.line_chart(chart_data)
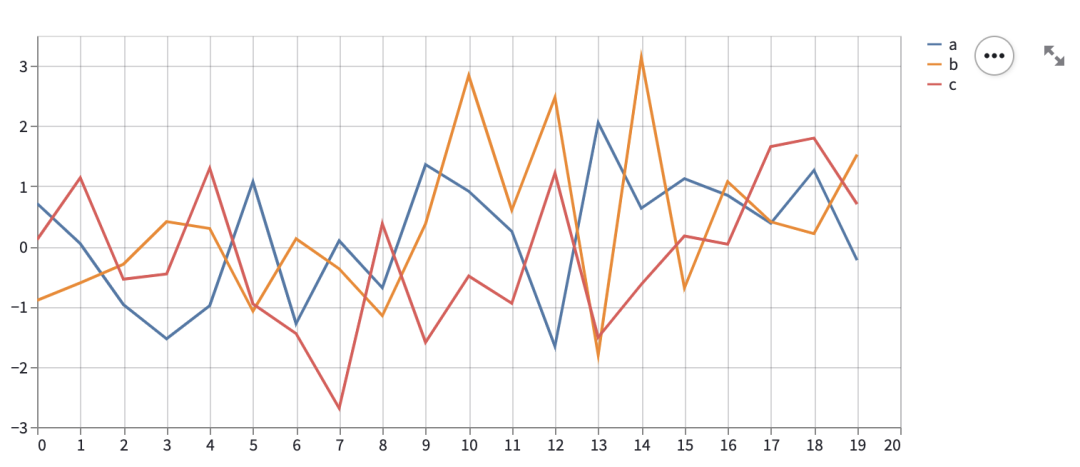
上述是 line_chart 的示例,其他图表的使用方法与之类似。Streamlit 图表可设置的参数很少,除了数据源外,剩下只能设置图表的宽度和高度。虽然 Streamlit 原生图表少,但它可以将其他 Python 可视化库的图表展示在 Streamlit 页面上。支持的可视化库包括:matplotlib.pyplot、Altair、vega-lite、Plotly、Bokeh、PyDeck、Graphviz。
以 matplotlib.pyplot 为例,使用方式如下:
import matplotlib.pyplot as plt
arr = np.random.normal(1, 1, size=100)
fig, ax = plt.subplots()
ax.hist(arr, bins=20)
st.pyplot(fig)
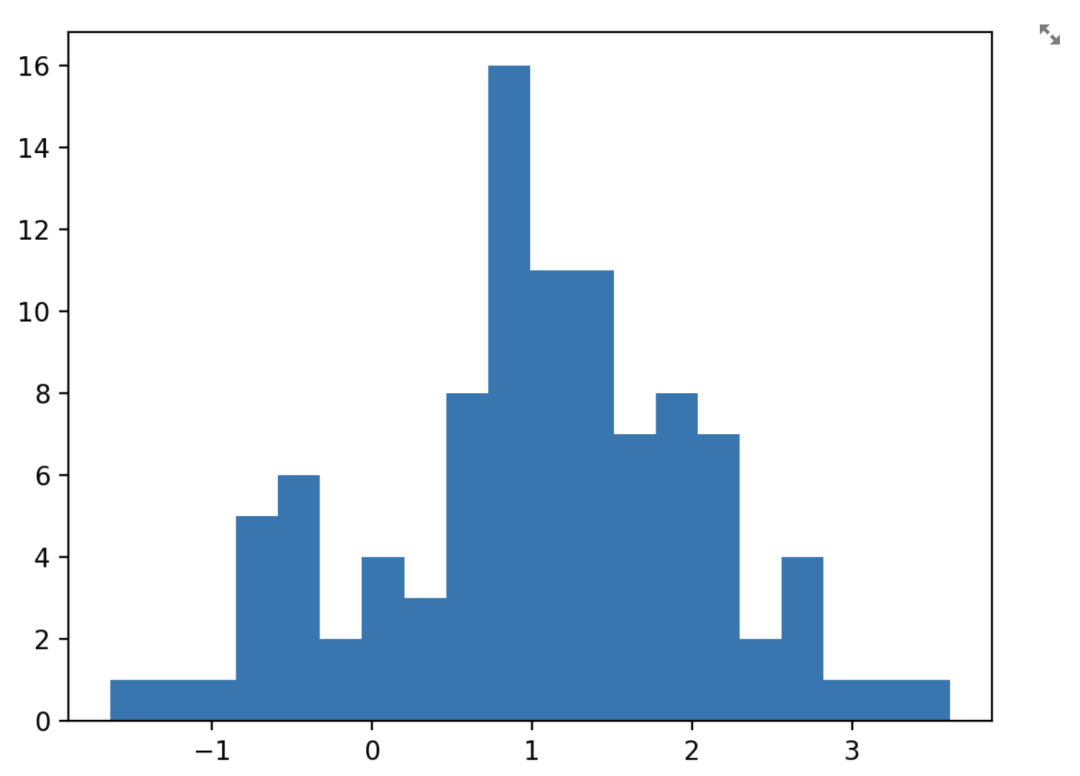
跟直接写 matplotlib.pyplot 一样,只不过最终展示的时候调用 st.pyplot 便可以将图表展示 Streamlit 页面上。其他 Python 库的使用方法与之类似。前面我们介绍的三类组件都是输出类、展示类的。对于交互式的页面来说,接受用户的输入是必不可少的。
Streamlit 提供的输入组件都是基本的,都是我们在网站、移动APP上经常看到的。包括:它们包含一些公共的参数:
- on_click / on_change:组件发生交互(如:输入、点击)后的回调函数
-
kwargs:回调函数的参数
下面以 selectbox 来演示输入组件的用法
option = st.selectbox(
'下拉框',
('选项一', '选项二', '选项三'))
st.write('选择了:', option)
selectbox 展示三个选项,并输出当前选中的项(默认选中第一个)。当我们在页面下拉选择其他选项后,整个页面代码会重新执行,但组件的选择状态 会保留在 option 中,因此,调用 st.write 后会输出选择后的选项。
st.write 也是一个输出组件,可以输出字符串、DataFrame、普通对象等各种类型数据。
其他组件的使用与之类似,组件效果图如下:
Streamlit 定义了 image、audio 和 video 用于展示图片、音频和视频。
可以展示本地多媒体,也通过 url 展示网络多媒体。

用法跟前面的组件是一样的,后面的垃圾分类 APP 我们会用到 image 组件。
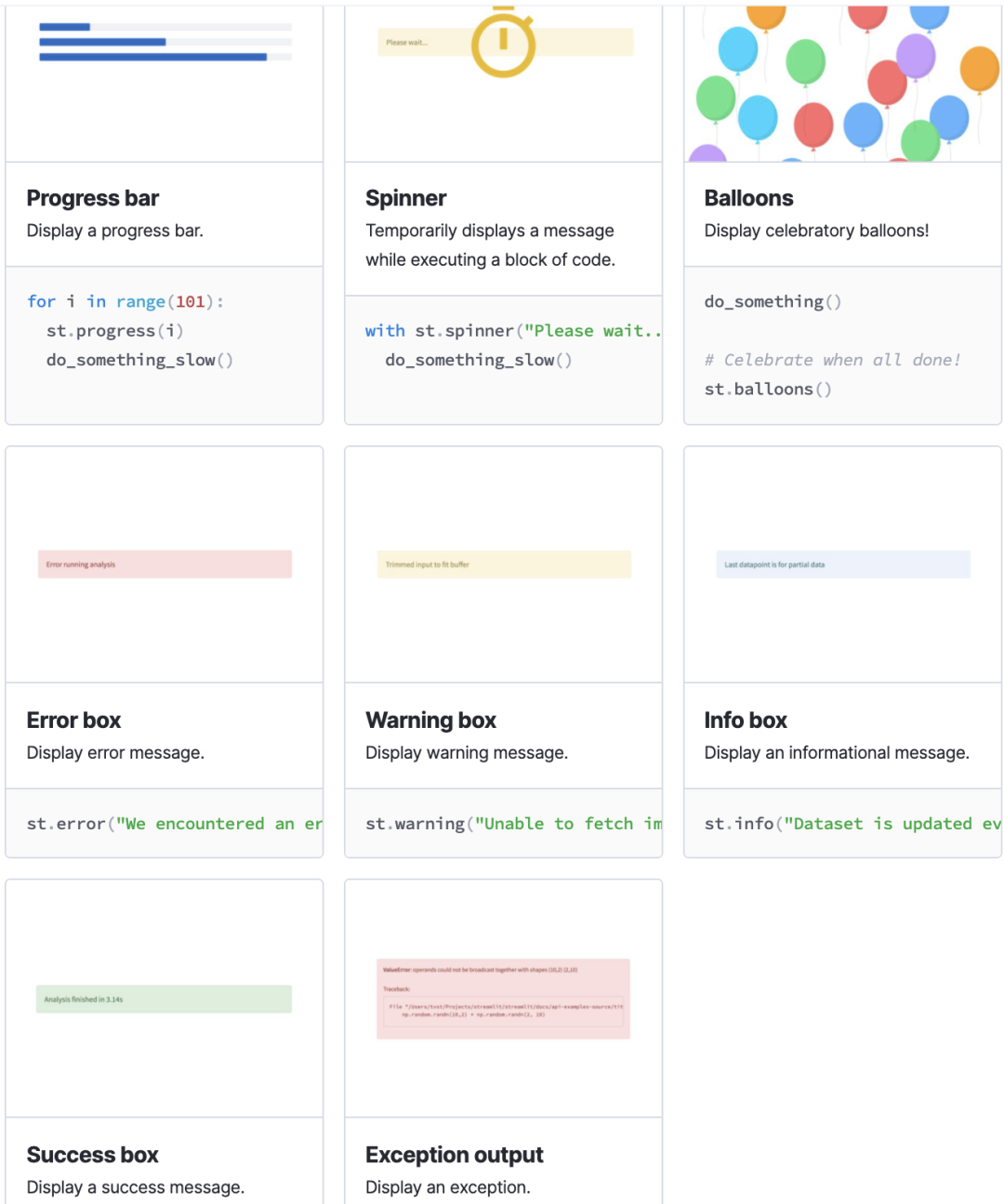
状态组件用来向用户展示当前程序的运行状态,包括:
progress:进度条,如游戏加载进度
spinner:等待提示
balloons:页面底部飘气球,表示祝贺
error:显示错误信息
warning:显示报警信息
info:显示常规信息
success:显示成功信息
效果如下:
到这里,Streamlit 的组件基本上就全介绍完了,组件也是 Streamlit 的主要内容。
这小节介绍一下其他比较重要的内容,包括页面布局、控制流和缓存。
页面布局。之前我们写的 Streamlit 都是按照代码执行顺序从上至下展示组件,Streamlit 提供了 5 种布局:
sidebar:侧边栏,如:文章开头那张图,页面左侧模型参数选择
columns:列容器,处在同一个 columns 内组件,按照从左至右顺序展示
expander:隐藏信息,点击后可展开展示详细内容,如:展示更多
container:包含多组件的容器
控制流。控制 Streamlit 应用的执行,包括
stop:可以让 Streamlit 应用停止而不向下执行,如:验证码通过后,再向下运行展示后续内容。
form:表单,Streamlit 在某个组件有交互后就会重新执行页面程序,而有时候需要等一组组件都完成交互后再刷新(如:登录填用户名和密码),这时候就需要将这些组件添加到 form 中
form_submit_button:在 form 中使用,提交表单。
缓存。这个比较关键,尤其是做机器学习的同学。刚刚说了, Streamlit 组件交互后页面代码会重新执行,如果程序中包含一些复杂的数据处理逻辑(如:读取外部数据、训练模型),就会导致每次交互都要重复执行相同数据处理逻辑,进而导致页面加载时间过长,影响体验。
加入缓存便可以将第一次处理的结果存到内存,当程序重新执行会从内存读,而不需要重新处理。
使用方法也简单,在需要缓存的函数加上 @st.cache 装饰器即可。
DATE_COLUMN = 'date/time'
DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
@st.cache
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
最后讲解垃圾分类APP的代码,前面介绍几大类组件在该 APP 都有涉及。
垃圾分类模型我用的是天行 API ,大家可以去 https://www.tianapi.com/ 注册账号,获取 appkey,开通“图像垃圾分类” 接口即可。
除了key外,其他 3 个参数需要用 Streamlit 组件实现,代码如下:
import base64
import requests
import streamlit as st
import pandas as pd
import numpy as np
add_selectbox = st.sidebar.selectbox(
"图片来源",
("本地上传", "URL")
)
uploaded_file = None
img_url = None
if add_selectbox == '本地上传':
uploaded_file = st.sidebar.file_uploader(label='上传图片')
else:
img_url = st.sidebar.text_input('图片url')
cls_mode = {'严格模式': 0, '模糊模式': 1}
mode_name = st.sidebar.radio('分类模式', cls_mode)
mode = cls_mode[mode_name]
使用了 3 个输入组件,因为 img 和 imgurl 是二选一,所以我们用下拉单选框控制仅展示一个组件。# 请求结果
img_base64 = None
if uploaded_file:
st.image(uploaded_file, caption='本地图片')
base64_data = base64.b64encode(uploaded_file.getvalue())
img_base64 = base64_data.decode()
if img_url:
st.image(img_url, caption='网络图片')
使用 image 多媒体组件即可。如果是本地图片,需要将其转成 base64 编码的字符串。
if img_base64 or img_url:
cls_res = get_img_cls_res(img_base64, img_url, mode)
lajitype_to_name = {0: '可回收物', 1: '有害垃圾', 2: '厨余垃圾'
, 3: '其他垃圾', 4: '无法识别'}
if cls_res.status_code == 200:
cls_df = pd.DataFrame(cls_res.json()['newslist'])
cls_df['分类'] = cls_df.index.astype(str) + '-' + cls_df['name'] + '-' + cls_df['lajitype'].apply(lambda x: lajitype_to_name[x])
cls_df['置信度'] = cls_df['trust']
cls_df.set_index(["分类"], inplace=True)
print(cls_df)
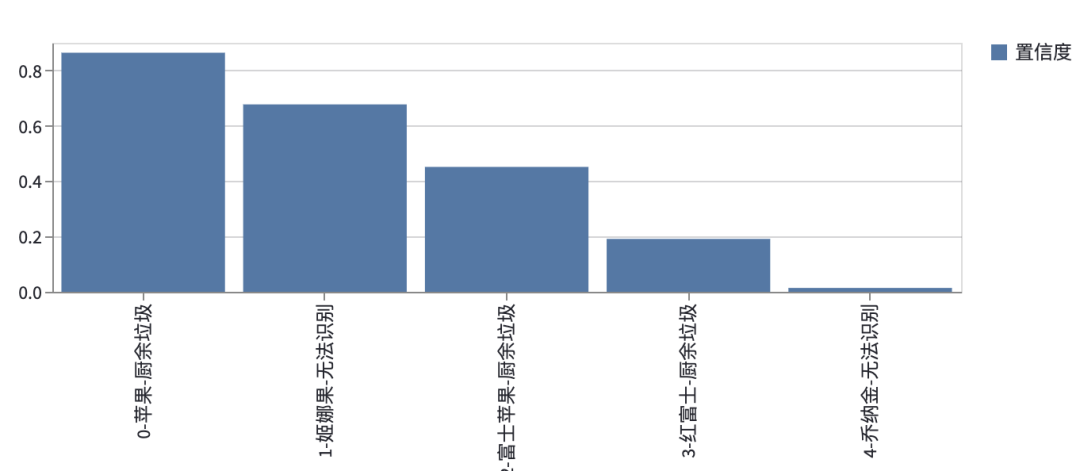
st.bar_chart(cls_df[['置信度']])
else:
st.write(cls_res)
get_img_cls_res 函数是请求接口的函数
def get_img_cls_res(img_base64, img_url, mode):
url = 'https://api.tianapi.com/txapi/imglajifenlei/index'
headers = {
'Content-Type': 'application/x-www-form-urlencoded'
}
body = {
'key': 'APPKEY',
'mode': mode
}
if img_base64:
body["img"] = img_base64
if img_url:
body['imgurl'] = img_url
response = requests.post(url, headers=headers, data=body)
return response
根据返回的数据格式,将数据按照置信度(trust)展示成一个柱状图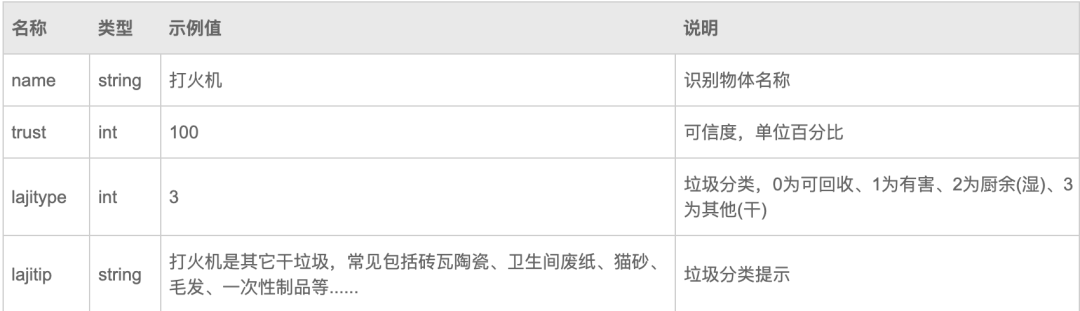
完整代码回复 “垃圾分类v2” 获取。今天的内容基本上把 Streamlit 讲完了,细节的内容大家可以自行参考官方文档,相信读完该教程,再看官方文档就很容易了。重磅!Python交流群已成立
为了给小伙伴们提供一个互相交流的技术平台,特地开通了Python交流群。群里有不少技术大神,不时会分享一些技术要点,更有一些资源收藏爱好者不时分享一些优质的学习资料。(免费,不卖课!)
▲长按扫码









