如果做动态映射,可能会出现使用过程中字段类型冲突的情况,此时只能 reindex 进行重新重置索引,并进行数据同步。如果数据量特别大的情况, reindex 期间会极大地影响集群性能。一定要慎重。
宽表模式:顾名思义,就是字段很多的数据表,通常是指业务相关的各指标、维度、属性关联在一起的一张数据表。宽表包含维度层次比较多,也容易造成冗余,但是有利于进行海量数据提取与分析,广泛应用于 olap 领域。
nested 类型属于 ES 的对象类型,允许存储复杂嵌套的对象模型。nested 的出现提供了对象类型数组中的独立查询,保证了读取精度。nested 可以保证数组中每个对象的独立性。
在 ES 6.x 版本后父子文档使用 join 来替代。父子文档解决了 nested 的子文档不能独立更新的问题,保证了父与子更新的独立性。比较适合 1 个父对多个子,且子文档更新频繁的场景。
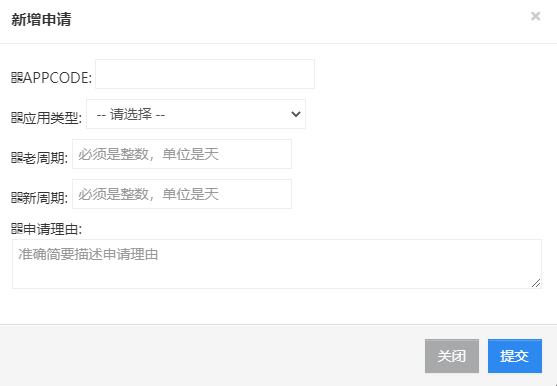
审批过后,该 appcode 对应的索引生命周期自动变成新的周期。
维护:日志集群将不同的 appcode 的索引生命周期数值存储到了 postgresql 中,从日志申请流程通过,即会写入新 appcode 与默认的存储时长。当每次有存储周期修改审批后,自助工单平台会操作修改 postgresql 进行时长的调整。
清理:根据 postgresql 的 appcode 存储数据,编写好清理脚本,并用 airflow 进行任务定时调度(每周一次),可以起到每周的索引清理工作。
注意:由于每周需要删除的索引众多(大约900~1000),不能一次删除,需要一个一个删除,并且中间进行 3-5s 的休眠。清理过程中,可以观察集群的 pending_tasks 是否飙高,集群 load 是否变高,来保障稳定性。可以选择集群使用率低的时间段来进行索引的清理操作。
5.2 索引settings设计
日志集群中索引 settings 设计主要需要考虑的点有:分片的周期评估与调整、性能优化的整体调整(主要包括total_shards_per_node 、refresh)、索引的提前创建。
5.2.1 分片周期调整
每周会有 airflow 定时任务进行索引分片评估计算。具体的逻辑如下:
a. 拿到本周的各 appcode 对应索引的主分片存储量,按照分片 SIZE (40G)来计算出分片数,可以参考如下 api 来执行
_cat/indices?format=json&pretty&bytes=b&h=index,pri,docs.count,pri.store.size
b. 获取到数据节点实例数,在 a 步骤得到的分片数和实例数取小值。如下:
计算方式:shard_count = MIN(shard_count, node_count)
api:_cat/nodes?format=json&h=name,ip,node.role
c. 计算 buffer ,buffer + shard_count 为最终的分片数。通常比例系数为30%,buffer为比例系数 * shard_count
日志类型数据分片大小建议在 30~50G 之间为佳。
具体 templates 的维护与设计管理,请见下章节。
5.2.2 total_shards_per_node 周期调整
total_shards_per_node 的周期调整可以和分片调整放到一起。以减少维护成本。
total_shards_per_node 默认为无限量。
调整原则为:保证单个索引在单个节点上保留最少的分片数,以避免数据分片倾斜的情况。
total_shards_per_node 的调整逻辑如下:
a. 首先设置 total_shards_per_node 几个范围,日志集群这边根据数据、节点情况设置了三个范围
total_shards_per_node: 1 => shard_count < node_counttotal_shards_per_node: 2 => node_count < shard_count < node_count * 1.3(比例系数)total_shards_per_node: 3 => node_count * 1.3 < shard_count
b. 根据上述的范围来计算不同索引的 total_shards_per_node 。5.2.3 refresh 周期调整
refresh 的调整相对比较简单:默认所有的索引 refresh_interval 设置为 60s
对于非高优先级的 appcode,total_shards_per_node >1 的,设置 refresh_interval 为 120s 。
5.2.4 索引周期创建
确立好上述索引的配置信息后,可以提前创建下一周期的索引。
索引创建时机很重要,日志集群按周来索引数据,需要周一之前创建好下一周期的索引。
创建索引主要注意的点:
a. 为节省资源,需要在创建前判断索引在当前周是否有索引数据,如果没有,则不创建下一周期(如果已经下线,则就不会创建新的索引)
b. 创建索引需要串行执行,且每个索引创建后,需要休眠 3-5s
c. 索引周期创建同样需要 airflow 定时任务。根据每周的索引数和执行时长,评估创建的时间范围,来进行定时任务的调整。
5.3 templates 设计管理
templates 是索引模板,可以定义好一类 index-pattern的settings 、mappings。而日志类索引正式由于得天独厚的分类优势可以划分为各个不同的 index-pattern ,进而创建 templates 。
日志集群的 templates 架构主要分为两块:default templates、index-pattern templates。
前者是提取日志数据的公共内容写入到统一的 templates ,供所有日志索引数据
5.3.1 default templates
default templates 是默认的模板,用来作为根模板使用,适用于放一些通用的配置,以达到方便配置管理的作用。
日志集群的 default templates 主要做了以下几点:
a. 提供默认的分片、refresh
注:使用 default templates 的分片数和 refresh 刷新频率主要是为了新增的日志提供默认的配置。日志集群做过统计基本上 95% 以上的索引周存储量都在 1TB 以内,所以默认创建 20 分片的索引能满足绝大多数需求。
number_of_shards: 20refresh_interval: 60s
根据各个业务线写入的数据字段类型,和 kafka 存储的日志源数据信息,提取了一些共用字段,举例如下:
@timestamp: datesend_time : long (时间戳)app_code : keywordsource_ip : keywordcontent : textlog_name : keyword
更进一步,我们可以根据字段类型进行自身的数据内容,使用情况来进行字段属性方面的调整,比如:app_code : 字段存储的是每个 appcode ,在单个 appcode 下没有检索意义。故而设置 index: false
content : 字段存储的是日志的主要内容,内容通常比较冗长。设置 norams: false, 不对 content 计算得分
根据上述,还对 source_ip、send_time 等字段都做了 index:false 的设置
一个较为完整的 default template 如下:
{ "order": 1, "index_patterns": [ "log_*" ], "settings": { "index": { "routing": { "allocation": { "total_shards_per_node": "1" } }, "refresh_interval": "60s", "number_of_shards": "20", "translog": { "durability": "async" }, "number_of_replicas": "1" } }, "mappings": { "properties": { "@timestamp": { "type": "date" }, "send_time": { "index": false, "type": "long" }, "source_host": { "ignore_above": 256, "type": "keyword" }, "log_name": { "ignore_above": 256, "type": "keyword" }, "content": { "norms": false, "type": "text" }, "app_code": { "ignore_above": 256, "index": false, "type": "keyword" }, "source_ip": { "ignore_above": 256, "index": false, "type": "keyword" } } }, "aliases": {}}
一般有如下情况下需要用到独立的 template :
a. 有独立于 default templates 的字段需要提前设置,比如增加字段
b. 针对 default templates 的现有字段有属性调整设置,比如调整 date 类型的 format
c. 创建独立的 shard_count、total_shards_per_node ,如上文 5.2 所示
比如其中一个日志索引存储的是 city 相关的日志数据,所以会增加 cityName 字段;@timestamp(date类型) 写入的格式为 yyyy-MM-dd HH:mm:ss.SSS ,则修改了 date 的 format ;而分片相关的设置会在定时任务中进行自动更新。一个独立的 template 参考如下:
{ "order": 99, "index_patterns": [ "log_order_info-*" ], "settings": { "index": { "number_of_shards": "256", "routing": { "allocation": { "total_shards_per_node": "2" } }, "refresh_interval": "120s" } }, "mappings": { "properties": { "cityName": { "type": "keyword" }, "@timestamp": { "format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss.SSS", "type": "date" } } }, "aliases": {}}
5.4 实战总结
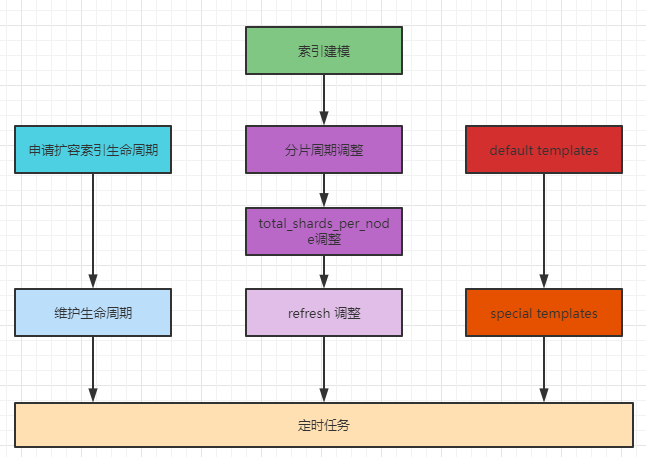
总结上述的实战,主要涉及到了三块:索引生命周期管理、索引 settings 设计管理、索引的 templates 管理,这几块既有配置类的设计管理,也有性能方面的考虑,还加入了生产中使用的 templates 进行设计管理,提升可维护性。并统一通过 airflow 定时任务进行自动化维护,保证了索引周期性设计的稳定性。具体流程参考下图:
6. 最佳实战建议
Settings层面
分片大小:单分片控制在 20~40G 内。单分片支持的 doc 数量在2,147,483,519。
分片数量:建议趋近于节点数,提升并发性能
副本数量:reindex 数据建议为 0 个;生产使用建议至少 1 个
total_shards_per_node:如果分片数小于等于节点数,建议1个。否则按比例增加即可。
refresh_interval: 时效性要求高建议用默认 1s ,否则建议设置在 30~60s 左右。
Mappings层面
templates 使用:对于同一类型索引进行提炼,提前做 templates ,方便后期灵活调整。
keyword、text:精准查询与聚合计算使用 keyword 、分词检索使用text;
动态templates:对于不确定的字段需要设置类型映射,可以考虑使用。
字段数量:单索引推荐字段数 1000 以内
对象嵌套:默认限制嵌套 20 层,建议不要超过 3 层
属性设置:根据业务情况,针对不同字段类型进行属性设置。比如对于不查询检索的字段,设置 index:false ,具体参见 3.3 章节。
7. 总结
文末,总结一下 ES 索引设计的核心考量因素:
业务模型已知的情况下,尽可能使用静态设计。对于不确定的字段,可以结合动态 mapping 进行控制
索引分片和副本一定要提前设计好,如果索引存储周期不定,数据量很大的情况,可以结合 rollover 控制单分片大小
Mapping 创建好后,无法更改,所以对于不确定的参数建议进行完备的测试,方可放入生产环节
根据业务提前设计要比后续遇到问题填坑省很多事情
相信读者认真看完此篇文章,结合业务场景,仔细思考,定能设计出性能更好、稳定性更强的索引。
8. 参考文献
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index-management.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/mapping-intro.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/mapping.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/indices-rollover-index.html
https://blog.csdn.net/laoyang360/article/details/83717399






