大家好!我是崔庆才。
今天告诉大家一个好消息:《Python3网络爬虫开发实战(第2版)》今天正式上市了!!!!
没错,就是这本:

2018 年 5 月我的《Python3网络爬虫开发实战》的第一版出版了,从上市到现在三年多销量约 10w 册(真的非常感谢各位读者的支持)。后来,由于一些技术更迭,我开始策划编写本书的第二版。
2021 年11月,这本书历经各种反复修改、审稿等阶段,到今天终于上市了!
这几个月我收到了太多读者的询问,第二版什么时候出来,真的抱歉实在是让大家久等了。
没错,就是今天,它来了!
第二版更新内容
大家第一个问题可能就会问,第二版比第一版更新了哪些内容?
因为技术总是在不断发展和进步的,爬虫技术也是一样,它在爬虫和反爬虫不断斗争的过程中也在不断演进。比如现在越来越多的网页采取了各种防护措施,比如前端代码的压缩和混淆、API 的参数加密、WebDriver 的检测,要做到高效的数据爬取,我们就需要懂得一些 JavaScript 逆向分析相关技术。App 也是一样,App 的抓包防护、加壳保护、Native 化、风控检测使得越来越多的 App 数据难以爬取,所以我们也不得不了解一些逆向相关技术,如 Xposed、Frida、IDA Pro 等工具的使用。除此之外,近几年深度学习和人工智能发展得也是如火如荼,所以爬虫也可以和人工智能结合起来,比如基于深度学习的验证码识别、网页内容的智能化解析和提取等技术我们也可以进行学习和了解。另外,一些大规模爬虫的管理和运维技术也在不断发展,当前 Kubernetes、Docker、Prometheus 等云原生技术也非常火爆,基于 Kubernetes 等云原生技术的爬虫管理和运维解决方案也已经很受青睐。然而,之前第一版书对以上提到的这些新兴技术几乎没有提及。
除此之外,第一版书在讲解数据爬取的过程中引用了很多案例和服务,比如猫眼电影网站、淘宝网站、代理服务网站,然而几年过去了,有些案例网站和服务早已经改版或者停止维护,这就导致第一版书中的很多案例已经不能正常运行了。这其实是一个很大的问题,因为程序运行不通会大大降低学习的积极性和成就感,而且会浪费不少时间。另外,即使案例对应的爬虫代码及时更新了,那我们也不知道这些案例网站和服务什么时候会再次改版,因为这都是不可控的。所以,为了彻底解决这个问题,我花费了近半年的时间构建了一个爬虫案例平台(https://scrape.center),平台包含了几十个爬虫案例,包括服务端渲染(SSR)网站、单页面应用(SPA)网站、各类反爬网站、验证码网站、模拟登录网站、各类 App 等,覆盖了现在爬虫和反爬虫相关的大多数技术,整个平台都是我来维护的,书中几乎所有案例都是从案例平台来的,从而解决了页面改版的问题。
所以,本书相比第一版来说,更新的内容主要如下:
绝大多数都迁移到了自建的案例平台,以后再也不用担心案例有过期或改版问题。
替换了原本第一章环境安装的章节,将环境配置的部分全部汇总并迁移到案例平台(https://setup.scrape.center)并在书中以外链的形式附上,以确保环境的配置和安装说明能够被及时更新。
增加了一些新的请求库、解析库、存储库等的介绍,如 httpx、parsel、Elasticsearch 等库的介绍。
增加了异步爬虫的介绍,如协程的基本原理、aiohttp 的使用和爬取实战介绍。
增加了一些新兴自动化工具的介绍,如 Pyppeteer、Playwright 的介绍。
增加了深度学习相关内容,如图形验证码、滑动验证码的识别方案。
丰富了模拟登录章节的内容,如增加了 JWT 模拟登录的介绍和实战、大规模账号池的优化。
增加了 JavaScript 逆向的章节,包括网站加密和混淆技术、JavaScript 逆向调试技巧、JavaScript 的各种模拟执行方式、AST 还原混淆代码、WebAssembly 等相关技术的介绍。
丰富了 App 自动化爬取技术的章节,如新兴框架 Airtest 的介绍、手机群控和云手机技术的介绍。
增加了 Android 逆向章节,如反编译、反汇编、Hook、脱壳、so 文件分析和模拟执行等技术的介绍。
增加了网页智能化解析章节,包括列表页、详情页内容提取算法和分类算法。
丰富了 Scrapy 相关章节的介绍,如 Pyppeteer 的对接、RabbitMQ 的对接、Prometheus 的对接等。
增加了基于 Kubernetes、Docker、Prometheus、Grafana 等云原生技术爬虫管理和运维解决方案的介绍。
以上就是第二版的主要更新内容,更多详情可以看《Python3网络爬虫开发实战(第2版)》内容介绍
章节介绍
为了让大家更直接地了解到全书的内容,这里就直接放目录了:


整体来说,新增了很多很多爬虫知识点,更新了全书爬虫案例并解决了案例过期的问题。
另外通过目录可以看到,全书一共 900 多页,(量了下有 4.3 厘米厚),定价是 139.8 元。
可以直接看第二版吗?
当然,有朋友也会担心,我需不需要先学习第一版,然后才能学第二版呢?
答案是:可以直接学第二版,第二版书爬虫的内容知识体系是完整的,一些旧的技术已经在第一版中移除,第二版的书籍是对所有爬虫知识体系的全新升级。
没有基础可以学吗?
有朋友也可能会问,没有爬虫或者 Python 基础可以学吗?
答案是:可以。本书就是专为零爬虫基础的朋友准备的,本书从最基础的环境配置、基础知识的讲解开始,循序渐进地对爬虫的各个知识点进行介绍,所以完全不用担心没有爬虫基础学不会的问题。如果没有 Python 基础,那也没关系(当然有会更好),书中也会提及 Python 环境的配置并附上一些 Python 入门学习资料和链接,同时也会通过各个 Python 代码片段来进行讲解,很多案例也很简单易懂,学爬虫的时候 Python 也就会逐渐掌握了。
大咖推荐
这本书同时还获得了 Python 之父的推荐(没错就是 Python 的创始人,Guido van Rossum)。另外我还有幸获得了微软亚洲互联网工程院副院长曾文峰、知名爬虫专家梁斌penny、中国人民大学高瓴人工智能学院长聘副教授宋睿华的推荐。
下面是推荐语的内容:

宣传彩页
另外编辑还为本书制作了几张宣传彩页,是对整本书的一个宣传介绍,大家可以看下:

有没有电子版?
看到这里,大家可能也会问了,有没有电子版呢?可能有的朋友习惯看电子版的书本来学习,有的朋友可能在海外也不方便购买,所以想要电子版。
但还是很遗憾地说:没有电子版。
因为你知道的,如果出了电子版,那么马上就会有各种盗版袭来,网上也会造成各种恶意传播。
所以,为了保护版权,这本书是没有上电子版的,还请各位读者谅解,谢谢。
购买链接
是的,最后就是大家最关心的部分了,到哪里能够买到呢?
上架之前,我与编辑经过各种沟通,原本是想给广大读者和粉丝们有个专属优惠的,但是这个比较难操作,所以最终决定,整本书现在全网统一 7 折销售了!
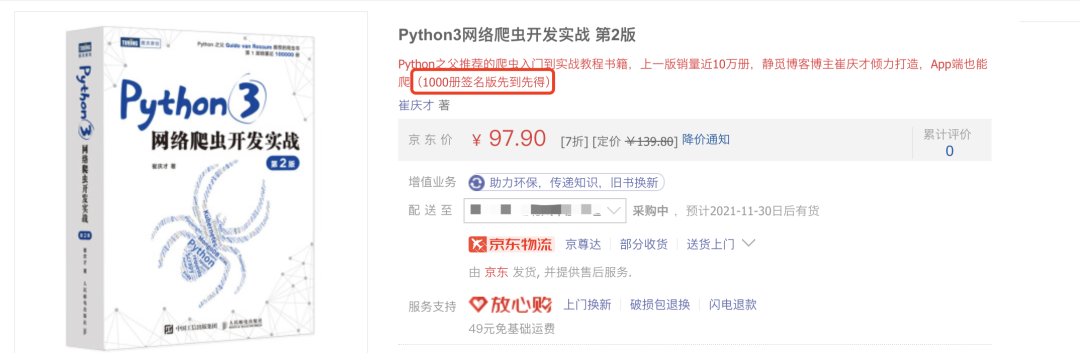
也就是说,原价 139.8 元,现在只需要 97.9 元就能买到了。
不过这个也是限时的,7 折优惠只到下周五,也就是 12 月 3 日,之后会恢复 84 折销售,也就是 117 元。
另外还有一个消息,前几天我不是签名了 1000 本书吗?所以,现在这个阶段,卖的全都是签名版(只在京东),一共 1000 本,卖完即止,先到先得。
大家拿到书之后,扉页就会有我的签名,是这样子的:

如果不想要签名版的朋友可以再等等,等签名版的卖完了就是非签名版的了。
下面是京东商品的截图,可以看到写着 1000 册签名版先到先得。
好了,废话不多说了,上购买链接,方便大家可以直接扫码购买~
新书上市,限时优惠

送书活动
快来留言说说你是怎样与爬虫或这本书结缘的,我们会选出点赞第1名,以及另外2名最佳留言,送出 3 本作者签名版图书给大家,截至2021.11.30。快来参与吧~








