从2015年开始,机器学习预测方法在很多行业都得到了应用,特别是2017年一年,信息安全领域特别是杀毒软件领域,已经出来完全取缔特征码的方式判断恶意软件,进入2018年,Top静态代码杀毒公司已经完全淘汰基于yara方法的多特征静态代码判断恶意软件的方式,完全使用机器学习分类器做为唯一判断依据。目前,比较成熟的商用静态恶意软件检测分类器引擎主要包括:Endgame、Cylance、SentinelOne、Sophos ML、CrowdStrike Falcon,那么它们都使用那些数据研究、使用那些机器学习算法做研究?接下来我们讨论一下。
 0x01 安全领域分类器受关注程度
0x01 安全领域分类器受关注程度
安全领域的分类可以通过监督的学习模型训练文件属性之间的复杂关系来区分恶意和良性样本, 但是,在公开研究中没有得到过多的关注。下面是Neural Information Processing Systems (NIPS) 从1987年到2017年12月份所有paper的研究方向统计
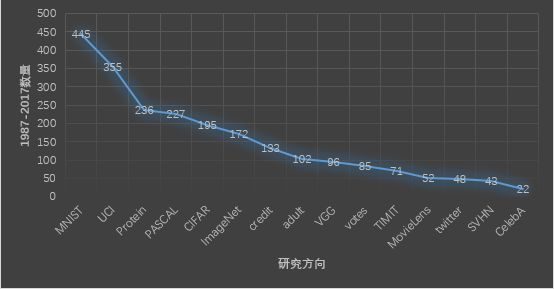
·手写数字分类(MNIST [445 papers])
·图像标记(CIFAR [195 papers]或ImageNet [172 papers])
·交通标志检测(VGG [96 papers])
·语音识别(TIMIT [71 papers])
在这里并没有找到很多papers,其它可参考的文献也没有更多papers

究其原因主要是没有一个很好用的研究的数据集。那么,问题在哪呢?我想挑战主要集中在以下几个方面
·法律上的限制
恶意的二进制文件共享可以通过像VirusShare和VX Heaven,但良性的二进制文件共享的有版权和法律的限制。良性和恶意二进制文件需要通过付费服务才能内部使用,例如:virustotal。
·标注的挑战
针对图像,文本和语音,这些可能会相对来说很快的被标记,针对安全数据标注,很多情况下非安全专家标注恶意还是良性文件是一个耗时的问题,甚至还需要培训。标注工作可以通过自动化软件标注(人类经验编码),VirusTotal这样的服务特别限制了供应商的共享反恶意软件标签。
·安全风险责任
发送大量的数据到非信息安全标注者,同时也不习惯例如沙箱的预防措施。
所以,通过endgame发布样本文件的SHA256哈希,使用开源的计算程序提取了PE 文件特征写入到每个样本中。
0x02、安全数据集
1、静态恶意软件检测历史
静态恶意软件检测尝试将样本分类为恶意或良性而不执行它们,而不是动态的根据恶意软件检测恶意软件其运行时行为包括时间相关序列的系统调用分析,基于机器学习的静态PE恶意软件检测器至少自2001年以来一直在使用,研究成果包括:RIPPER、朴素贝叶斯和整体分类器、byte-level N-grams NLP处理方法。
尽管端到端的深度学习预测方法在对象状态分类、机器翻译、语音识别方面有了质的飞跃,在许多这些方法中,原始图像,文本或语音波形被用作机器学习模型的输入,可以获得很有用的预测模型。但是,尽管在其他领域取得了成功,最近
恶意软件分类的端到端深度学习示例在[22]中进行了讨论,我们重新实现了这一点与第4节中的基准模型相比较
2、Demo测试
PE-Miner旨在生成基于机器学习的恶意软件检测器超过99%的真阳性率(TPR)以小于1%的误报率(FPR)和运行时间可与当天基于签名的扫描器相媲美
它在操作上训练了1 447个良性文件的数据集系统(从未发布),10,339个恶意PE文件VX Heaven 以及Malfease的5586个恶意PE文件,PE-Miner使用包含二元指示符的189个功能对于引用的特定DLL,各个部分的大小,来自COFF部分的摘要信息,摘要资源表等
3、virustotal数据集制作
收集2016年12月~2017年12月大约110万个样本包900K训练样本(300K恶意,300K良性,300K无标签)200K测试样本(100K恶意,100K良性)。
在制作EMBER数据集时,我们考虑需要解决
·比较恶意软件检测相关的机器学习模型。
·量化模型退化和概念漂移时间。
·研究可解释的机器学习。
·比较恶意软件分类的功能,特别是在EMBER中未表示的新特征数据集。 这需要一个可扩展的数据集。
·比较无特性提取的NLP深度学习。这可能需要从代码中提取特征新数据集或shas256哈希来构建一个原始二进制文件数据集以匹配EMBER。
·研究针对机器学习攻击的恶意软件和相应的防御策略。
EMBER数据集由JSON行集合组成文件,每行包含一个JSON对象。每对象在数据中包含以下类型:
·原始文件的sha256散列作为唯一标识符;
·粗略的时间信息(月份分辨率)建立文件第一次的估计可见;
·标签,对于良性可能为0,对于恶意可能为1或-1表示未标记
·八组原始特征,包括两个分析过的值以及格式不可知的直方图。
Byte Histogram:每个字节出现次数的简单计数
Byte Entropy Histogram:滑动窗口熵计算

Section Information:从导入的函数名称导入的每个库
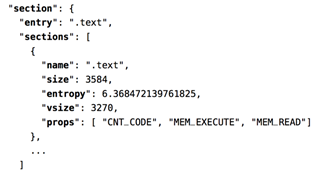
Import Information:导入函数名
Export Information:导出函数名
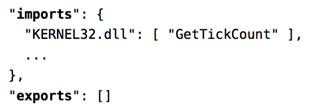
String Information :字符串信息
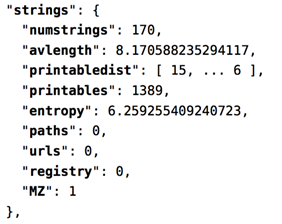
General Information:包含:导入,导出,符号的数量以及文件是否有重定位,资源或签名
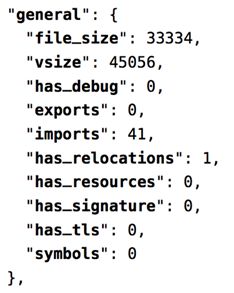
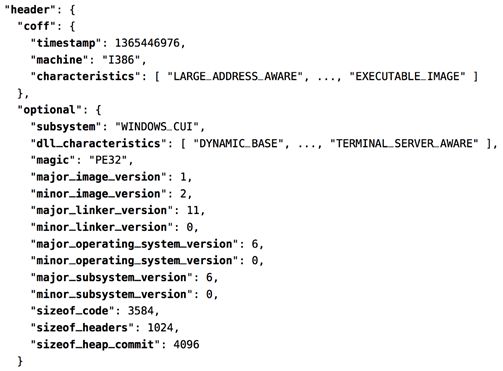
Header Information:关于文件编译的机器的详细信息。 连接器的版本,
图像和操作系统。
0x03 静态恶意软件分类器模型验证
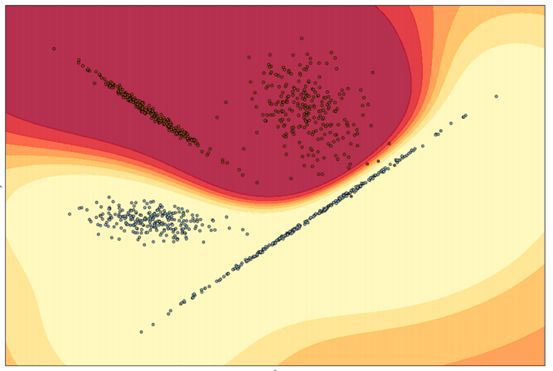
良性和恶意样本可以分布在特征空间中(使用文件大小和导入次数等属性)
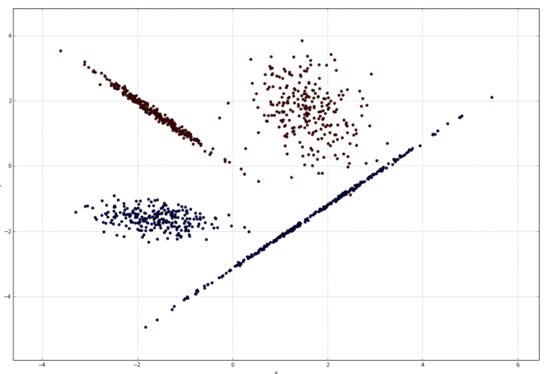
单一的yara规则只能区分两类,简单的yara是不可推广的
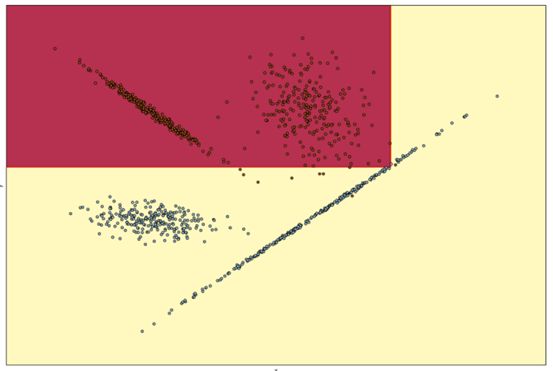
机器学习模型可以定义更好的边界,从而做出更准确的预测
模型:使用LightGBM使用默认模型参数训练的梯度增强决策树(GBDT)
import lightgbm as lgb X_train, y_train = read_vectorized_features(data_dir, subset="train”) train_rows = (y_train != -1) lgbm_dataset = lgb.Dataset(X_train[train_rows], y_train[train_rows]) lgbm_model = lgb.train({"application": "binary"}, lgbm_dataset)
Model Performance:
ROC AUC: 0.9991123269999999
Threshold: 0.871
False Positive Rate: 0.099%
False Negative Rate: 7.009%
Detection Rate: 92.991% ,商业模型一般都达到99%
0x04、总结
@1、这只是试验模型,真正商业化还需要长时间的参数调优工作。
@2、机器学习判断固然好,但是针对加密、加壳PE程序这种方法完全没用,还需要借助传统安全厂商的检测手段。
参考文献:https://arxiv.org/pdf/1508.03096.pdf












