随机森林是基于集体智慧的一个机器学习算法,也是目前最好的机器学习算法之一。
随机森林实际是一堆决策树的组合(正如其名,树多了就是森林了)。在用于分类一个新变量时,相关的检测数据提交给构建好的每个分类树。每个树给出一个分类结果,最终选择被最多的分类树支持的分类结果。回归则是不同树预测出的值的均值。
要理解随机森林,我们先学习下决策树。
决策树 - 把你做选择的过程呈现出来
决策树是一个很直观的跟我们日常做选择的思维方式很相近的一个算法。
如果有一个数据集如下:
data data
## x color
## 1 0.0 blue
## 2 0.5 blue
## 3 1.1 blue
## 4 1.8 blue
## 5 1.9 blue
## 6 2.0 green
## 7 2.5 green
## 8 3.0 green
## 9 3.6 green
## 10 3.7 green
那么假如加入一个新的点,其x值为1,那么该点对应的最可能的颜色是什么?
根据上面的数据找规律,如果x<2.0则对应的点颜色为blue,如果x>=2.0则对应的点颜色为green。这就构成了一个只有一个决策节点的简单决策树。
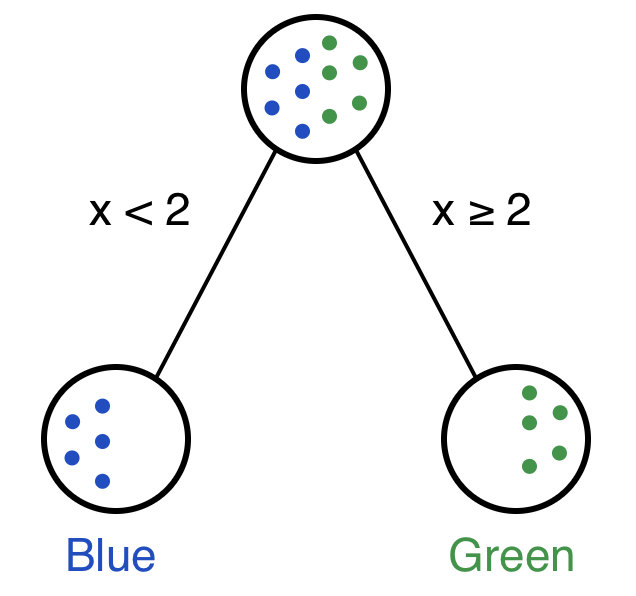
决策树常用来回答这样的问题:给定一个带标签的数据集(标签这里对应我们的color列),怎么来对新加入的数据集进行分类?
如果数据集再复杂一些,如下,
data y=c(1,0.5,1.5,2.1,2.8,2,2.2,3,3.3,3.5),
color=c(rep('blue',3),rep('red',2),rep('green',5)))
data
## x y color
## 1 0.0 1.0 blue
## 2 0.5 0.5 blue
## 3 1.1 1.5 blue
## 4 1.8 2.1 red
## 5 1.9 2.8 red
## 6 2.0 2.0 green
## 7 2.5 2.2 green
## 8 3.0 3.0 green
## 9 3.6 3.3 green
## 10 3.7 3.5 green
这时就需要再加一个新的决策节点,利用变量y的信息。
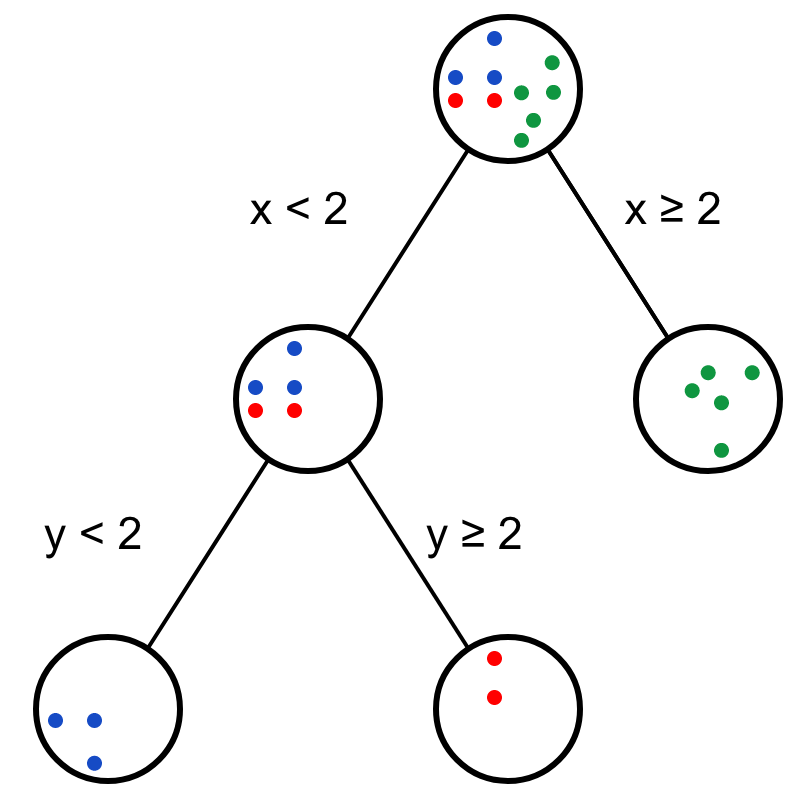
这就是决策树,也是我们日常推理问题的一般方式。
训练决策树 - 确定决策树的根节点
第一个任务是确定决策树的根节点:选择哪个变量和对应阈值选择多少能给数据做出最好的区分。
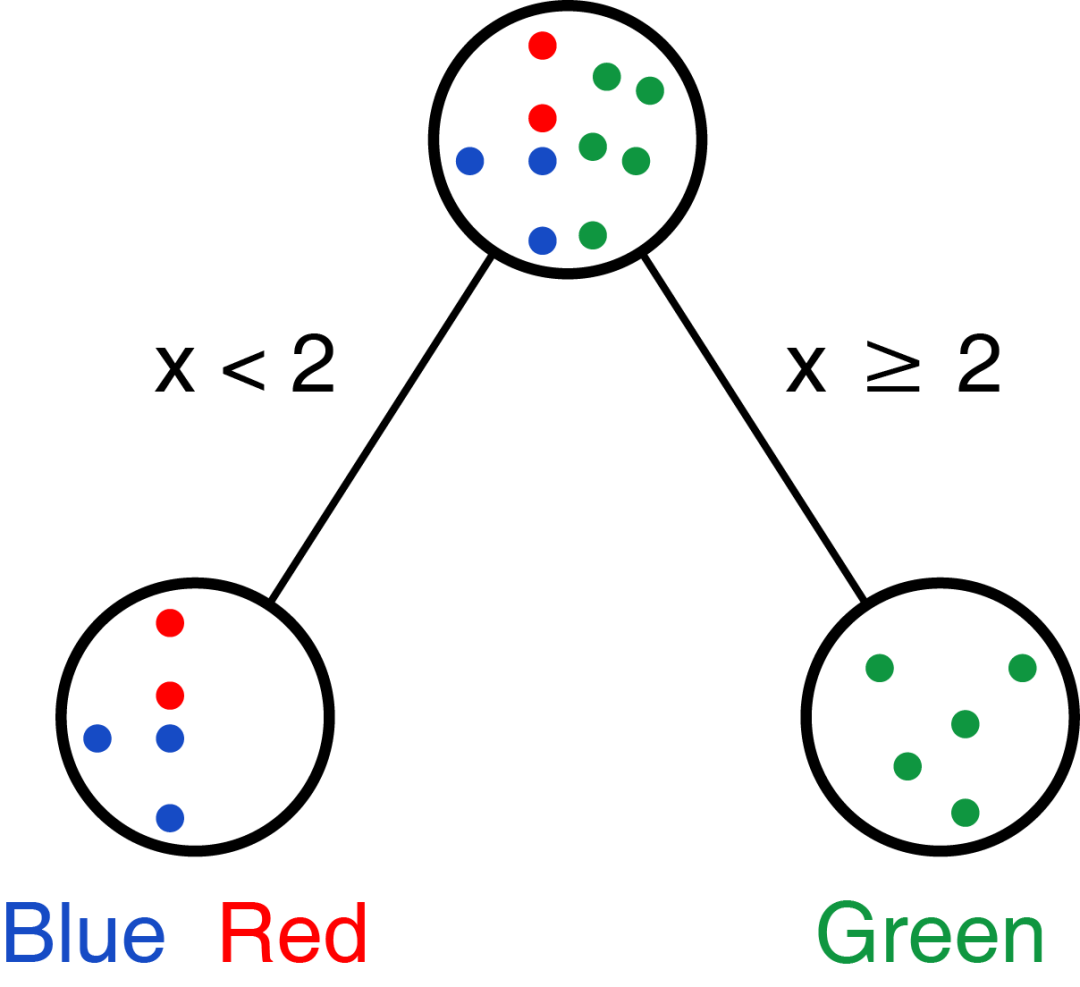
比如上面的例子,我们可以先处理变量x,选择阈值为2 (为什么选2,是不是有比2更合适阈值,我们后续再说),则可获得如下分类:
我们也可以先处理变量y,选择阈值为2,则可获得如下分类:
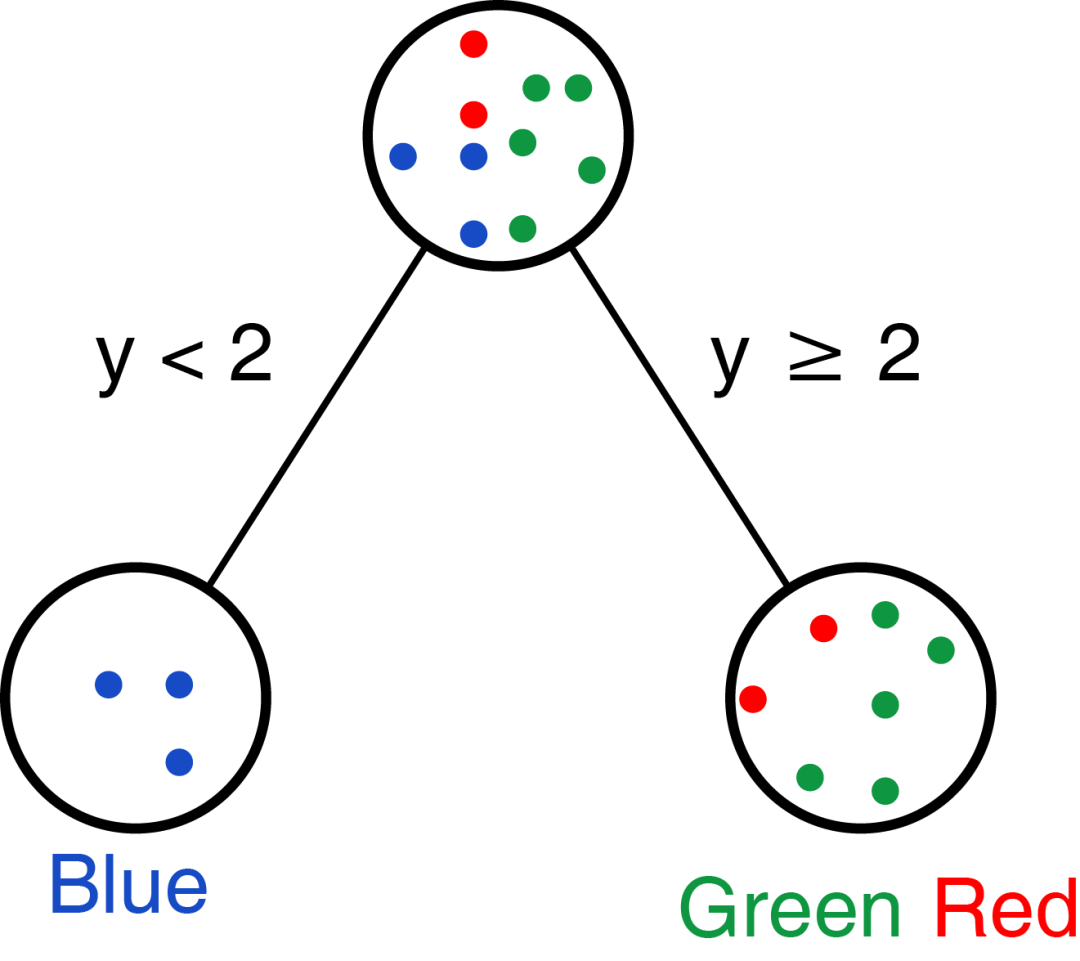
那实际需要选择哪个呢?
实际我们是希望每个选择的变量和阈值能把不同的类分的越开越好;上面选择变量x分组时,Green完全分成一组;下面选择y分组时,Blue完全分成一组。怎么评价呢?
这时就需要一个评价指标,常用的指标有Gini inpurity和Information gain。
Gini Impurity
在数据集中随机选择一个数据点,并随机分配给它一个数据集中存在的标签,分配错误的概率即为Gini impurity。
我们先看第一套数据集,10个数据点,5个blue,5个green。从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?如下表,错误概率为0.25+0.25=0.5(看下面的计算过程)。
probility "Pick Blue, Classify Green",
"Pick Green, Classify Blue",
"Pick Green, Classify Green"),
Probability=c(5/10 * 5/10, 5/10 * 5/10, 5/10 * 5/10, 5/10 * 5/10),
Type=c("Blue" == "Blue",
"Blue" == "Green",
"Green" == "Blue",
"Green" == "Green"))
probility
## Event Probability Type
## 1 Pick Blue, Classify Blue 0.25 TRUE
## 2 Pick Blue, Classify Green 0.25 FALSE
## 3 Pick Green, Classify Blue 0.25 FALSE
## 4 Pick Green, Classify Green 0.25 TRUE我们再看第二套数据集,10个数据点,2个red,3个blue,5个green。从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?0.62。
probility "Pick Blue, Classify Green",
"Pick Blue, Classify Red",
"Pick Green, Classify Blue",
"Pick Green, Classify Green",
"Pick Green, Classify Red",
"Pick Red, Classify Blue",
"Pick Red, Classify Green",
"Pick Red, Classify Red"
),
Probability=c(3/10 * 3/10, 3/10 * 5/10, 3/10 * 2/10,
5/10 * 3/10, 5/10 * 5/10, 5/10 * 2/10,
2/10 * 3/10, 2/10 * 5/10, 2/10 * 2/10),
Type=c("Blue" == "Blue",
"Blue" == "Green",
"Blue" == "Red",
"Green" == "Blue",
"Green" == "Green",
"Green" == "Red",
"Red" == "Blue",
"Red" == "Green",
"Red" == "Red"
))
probility
## Event Probability Type
## 1 Pick Blue, Classify Blue 0.09 TRUE
## 2 Pick Blue, Classify Green 0.15 FALSE
## 3 Pick Blue, Classify Red 0.06 FALSE
## 4 Pick Green, Classify Blue 0.15 FALSE
## 5 Pick Green, Classify Green 0.25 TRUE
## 6 Pick Green, Classify Red 0.10 FALSE
## 7 Pick Red, Classify Blue 0.06 FALSE
## 8 Pick Red, Classify Green 0.10 FALSE
## 9 Pick Red, Classify Red 0.04 TRUE
Wrong_probability = sum(probility[!probility$Type,"Probability"])
Wrong_probability
## [1] 0.62
Gini Impurity计算公式:
假如我们的数据点共有C个类,p(i)是从中随机拿到一个类为i的数据,Gini Impurity计算公式为:
$$
G = \sum_{i=1}^{C} p(i)*(1-p(i))
$$
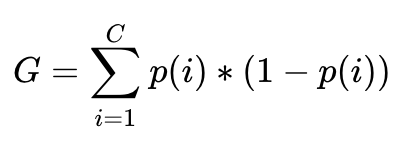
对第一套数据集,10个数据点,5个blue,5个green。从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?错误概率为0.25+0.25=0.5。
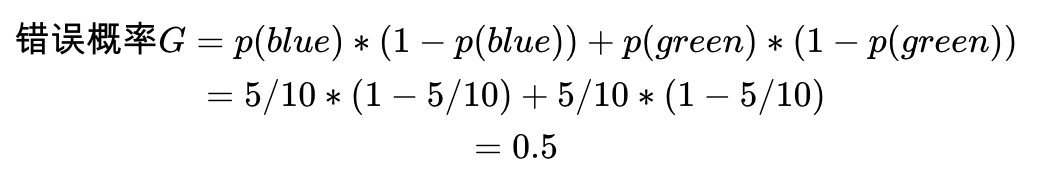
对第二套数据集,10个数据点,2个red,3个blue
,5个green。
从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?0.62。
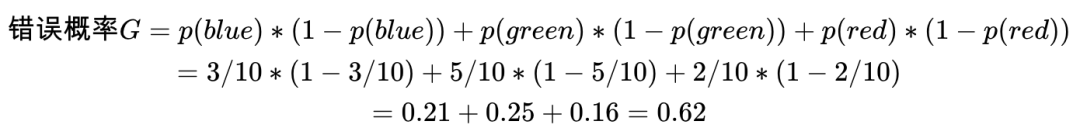
决策树分类后的Gini Impurity
对第一套数据集来讲,按照x<2分成两个分支,各个分支都只包含一个分类数据,各自的Gini
IMpurity值为0。
这是一个完美的决策树,把Gini Impurity为0.5的数据集分类为2个Gini Impurity为0的数据集。Gini Impurity== 0是能获得的最好的分类结果。
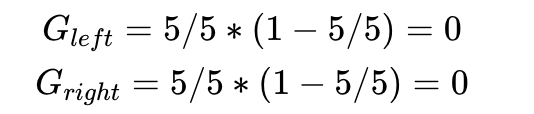
第二套数据集,我们有两种确定根节点的方式,哪一个更优呢?
我们可以先处理变量x,选择阈值为2,则可获得如下分类:
每个分支的Gini Impurity可以如下计算:
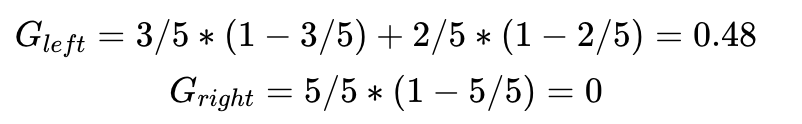
当前决策的Gini impurity需要对各个分支包含的数据点的比例进行加权,即
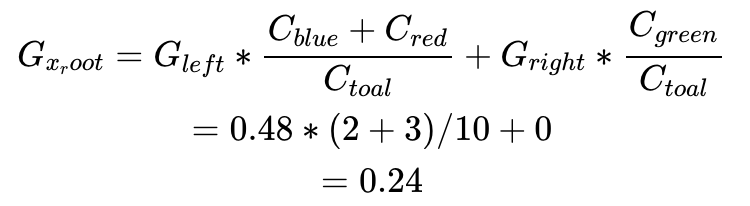
我们也可以先处理变量y,选择阈值为2,则可获得如下分类:
每个分支的Gini Impurity可以如下计算:
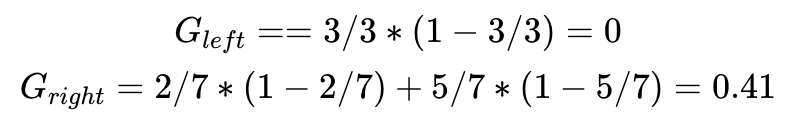
当前决策的Gini impurity需要对各个分支包含的数据点的比例进行加权,即
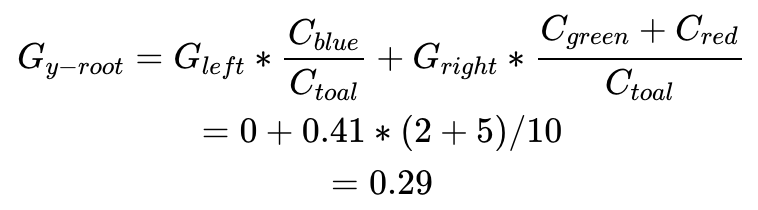
两个数值比较0.24<0.29,选择x作为第一个分类节点是我们第二套数据第一步决策树的最佳选择。
前面手算单个变量、单个分组不算麻烦,也是个学习的过程。后续如果有更多变量和阈值时,再手算就不合适了。下一篇我们通过暴力方式自写函数训练决策树。
当前计算的结果,可以作为正对照,确定后续函数结果的准确性。
训练决策树 - 确定根节点的分类阈值
Gini impurity可以用来判断每一步最合适的决策分类方式,那么怎么确定最优的分类变量和分类阈值呢?
最粗暴的方式是,我们用每个变量的每个可能得阈值来进行决策分类,选择具有最低Gini impurity值的分类组合。这不是最快速的解决问题的方式,但是最容易理解的方式。
定义计算Gini impurity的函数
data y=c(1,0.5,1.5,2.1,2.8,2,2.2,3,3.3,3.5),
color=c(rep('blue',3),rep('red',2),rep('green',5)))
data
## x y color
## 1 0.0 1.0 blue
## 2 0.5 0.5 blue
## 3 1.1 1.5 blue
## 4 1.8 2.1 red
## 5 1.9 2.8 red
## 6 2.0 2.0 green
## 7 2.5 2.2 green
## 8 3.0 3.0 green
## 9 3.6 3.3 green
## 10 3.7 3.5 green
首先定义个函数计算Gini_impurity。
Gini_impurity # print(branch)
len_branch if(len_branch==0){
return(0)
}
table_branch wrong_probability return(sum(sapply(table_branch, wrong_probability, total=len_branch)))
}
测试下,没问题。
Gini_impurity(c(rep('a',2),rep('b',3)))
## [1] 0.48
再定义一个函数,计算每次决策的总Gini impurity.
Gini_impurity_for_split_branch class_column, Init_gini_impurity=NULL){
total = nrow(data)
left left_len = length(left)
left_table = table(left)
left_gini
right =threshold,][[class_column]]
right_len = length(right)
right_table = table(right)
right_gini total_gini
result = c(variable_column,threshold,
paste(names(left_table), left_table, collapse="; ", sep=" x "),
paste(names(right_table), right_table, collapse="; ", sep=" x "),
total_gini)
names(result)
if(!is.null(Init_gini_impurity)){
Gini_gain result = c(variable_column, threshold,
paste(names(left_table), left_table, collapse="; ", sep=" x "),
paste(names(right_table), right_table, collapse="; ", sep=" x "),
Gini_gain)
names(result) }
return(result)
}
测试下,跟之前计算的结果一致:
as.data.frame(rbind(Gini_impurity_for_split_branch(2, data, 'x', 'color'),
Gini_impurity_for_split_branch(2, data, 'y', 'color')))
## Variable Threshold Left_branch Right_branch Gini_impurity
## 1 x 2 blue x 3; red x 2 green x 5 0.24
## 2 y 2 blue x 3 green x 5; red x 2 0.285714285714286
暴力决策根节点和阈值
基于前面定义的函数,遍历每一个可能得变量和阈值。
首先看下基于变量x的计算方法:
uniq_x delimiter_x impurity_x data=data, variable_column='x', class_column='color')))
print(impurity_x)
## Variable Threshold Left_branch Right_branch Gini_impurity
## 1 x 0.25 blue x 1 blue x 2; green x 5; red x 2 0.533333333333333
## 2 x 0.8 blue x 2 blue x 1; green x 5; red x 2 0.425
## 3 x 1.45 blue x 3 green x 5; red x 2 0.285714285714286
## 4 x 1.85 blue x 3; red x 1 green x 5; red x 1 0.316666666666667
## 5 x 1.95 blue x 3; red x 2 green x 5 0.24
## 6 x 2.25 blue x 3; green x 1; red x 2 green x 4 0.366666666666667
## 7 x 2.75 blue x 3; green x 2; red x 2 green x 3 0.457142857142857
## 8 x 3.3 blue x 3; green x 3; red x 2 green x 2 0.525
## 9 x 3.65 blue x 3; green x 4; red x 2 green x 1 0.577777777777778
再包装2个函数,一个计算单个变量为节点的各种可能决策的Gini impurity,
另一个计算所有变量依次作为节点的各种可能决策的Gini impurity。
Gini_impurity_for_all_possible_branches_of_one_variable uniq_value delimiter_value impurity Gini_impurity_for_split_branch, data=data,
variable_column=variable,
class_column=class,
Init_gini_impurity=Init_gini_impurity)))
if(is.null(Init_gini_impurity)){
decreasing = F
} else {
decreasing = T
}
impurity return(impurity)
}
Gini_impurity_for_all_possible_branches_of_all_variables one_split_gini Gini_impurity_for_all_possible_branches_of_one_variable,
data=data, class=class,
Init_gini_impurity=Init_gini_impurity))
if(is.null(Init_gini_impurity)){
decreasing = F
} else {
decreasing = T
}
one_split_gini[order(one_split_gini[[colnames(one_split_gini)[5]]], decreasing = decreasing),]
}
测试下:
Gini_impurity_for_all_possible_branches_of_one_variable(data, 'x', 'color')
## Variable Threshold Left_branch Right_branch Gini_impurity
## 5 x 1.95 blue x 3; red x 2 green x 5 0.24
## 3 x 1.45 blue x 3 green x 5; red x 2 0.285714285714286
## 4 x 1.85 blue x 3; red x 1 green x 5; red x 1 0.316666666666667
## 6 x 2.25 blue x 3; green x 1; red x 2 green x 4 0.366666666666667
## 2 x 0.8 blue x 2 blue x 1; green x 5; red x 2 0.425
## 7 x 2.75 blue x 3; green x 2; red x 2 green x 3 0.457142857142857
## 8 x 3.3 blue x 3; green x 3; red x 2 green x 2 0.525
## 1 x 0.25 blue x 1 blue x 2; green x 5; red x 2 0.533333333333333
## 9 x 3.65 blue x 3; green x 4; red x 2 green x 1 0.577777777777778
两个变量的各个阈值分别进行决策,并计算Gini impurity
,输出按Gini impurity由小到大排序后的结果。根据变量x和阈值1.95(与上面选择的阈值2获得的决策结果一致)的决策可以获得本步决策的最好结果。
variables Gini_impurity_for_all_possible_branches_of_all_variables(data, variables, class="color")
## Variable Threshold Left_branch Right_branch Gini_impurity
## 5 x 1.95 blue x 3; red x 2 green x 5 0.24
## 3 x 1.45 blue x 3 green x 5; red x 2 0.285714285714286
## 31 y 1.75 blue x 3 green x 5; red x 2 0.285714285714286
## 4 x 1.85 blue x 3; red x 1 green x 5; red x 1 0.316666666666667
## 6 x 2.25 blue x 3; green x 1; red x 2 green x 4 0.366666666666667
## 41 y 2.05 blue x 3; green x 1 green x 4; red x 2 0.416666666666667
## 2 x 0.8 blue x 2 blue x 1; green x 5; red x 2 0.425
## 21 y 1.25 blue x 2 blue x 1; green x 5; red x 2 0.425
## 51 y 2.15 blue x 3; green x 1; red x 1 green x 4; red x 1 0.44
## 7 x 2.75 blue x 3; green x 2; red x 2 green x 3 0.457142857142857
## 71 y 2.9 blue x 3; green x 2; red x 2 green x 3 0.457142857142857
## 61 y 2.5 blue x 3; green x 2; red x 1 green x 3; red x 1 0.516666666666667
## 8 x 3.3 blue x 3; green x 3; red x 2 green x 2 0.525
## 81 y 3.15 blue x 3; green x 3; red x 2 green x 2 0.525
## 1 x 0.25 blue x 1 blue x 2; green x 5; red x 2 0.533333333333333
## 11 y 0.75 blue x 1 blue x 2; green x 5; red x 2 0.533333333333333
## 9 x 3.65 blue x 3; green x 4; red x 2 green x 1 0.577777777777778
## 91 y 3.4 blue x 3; green x 4; red x 2 green x 1 0.577777777777778
再决策第二个节点、第三个节点
第一个决策节点找好了,后续再找其它决策节点。如果某个分支的点从属于多个class,则递归决策。
递归决策终止的条件是:
再添加分支不会降低Gini impurity
某个分支的数据点属于同一分类组 (Gini impurity = 0)
brute_descition_tree_result brute_descition_tree_result_index
brute_descition_tree Init_gini_impurity brute_force_result data, variables, class=class_variable, Init_gini_impurity=Init_gini_impurity)
print(brute_force_result)
split_variable split_threshold gini_gain = brute_force_result[1,5]
# print(gini_gain)
left right =split_threshold,]
if(gini_gain>0){
brute_descition_tree_result_index < brute_descition_tree_result[[brute_descition_tree_result_index]] < c(type=type, split_variable=split_variable,
split_threshold=split_threshold)
# print(brute_descition_tree_result_index)
# print(brute_descition_tree_result)
if(length(unique(left[[class_variable]]))>1){
brute_descition_tree(data=left, measure_variable, class_variable,
type=paste(brute_descition_tree_result_index, "left"))
}
if(length(unique(right[[class_variable]]))>1){
brute_descition_tree(data=right, measure_variable, class_variable,
type=paste(brute_descition_tree_result_index, "right"))
}
}
# return(brute_descition_tree_result)
}
brute_descition_tree(data, variables, "color")
## Variable Threshold Left_branch Right_branch Gini_gain
## 5 x 1.95 blue x 3; red x 2 green x 5 0.38
## 3 x 1.45 blue x 3 green x 5; red x 2 0.334285714285714
## 31 y 1.75 blue x 3 green x 5; red x 2 0.334285714285714
## 4 x 1.85 blue x 3; red x 1 green x 5; red x 1 0.303333333333333
## 6 x 2.25 blue x 3; green x 1; red x 2 green x 4 0.253333333333333
## 41 y 2.05 blue x 3; green x 1 green x 4; red x 2 0.203333333333333
## 2 x 0.8 blue x 2 blue x 1; green x 5; red x 2 0.195
## 21 y 1.25 blue x 2 blue x 1; green x 5; red x 2 0.195
## 51 y 2.15 blue x 3; green x 1; red x 1 green x 4; red x 1 0.18
## 7 x 2.75 blue x 3; green x 2; red x 2 green x 3 0.162857142857143
## 71 y 2.9 blue x 3; green x 2; red x 2 green x 3 0.162857142857143
## 61 y 2.5 blue x 3; green x 2; red x 1 green x 3; red x 1 0.103333333333333
## 8 x 3.3 blue x 3; green x 3; red x 2 green x 2 0.095
## 81 y 3.15 blue x 3; green x 3; red x 2 green x 2 0.095
## 1 x 0.25 blue x 1 blue x 2; green x 5; red x 2 0.0866666666666667
## 11 y 0.75 blue x 1 blue x 2; green x 5; red x 2 0.0866666666666667
## 9 x 3.65 blue x 3; green x 4; red x 2 green x 1 0.0422222222222223
## 91 y 3.4 blue x 3; green x 4; red x 2 green x 1 0.0422222222222223
## Variable Threshold Left_branch Right_branch Gini_gain
## 3 x 1.45 blue x 3 red x 2 0.48
## 31 y 1.8 blue x 3 red x 2 0.48
## 2 x 0.8 blue x 2 blue x 1; red x 2 0.213333333333333
## 21 y 1.25 blue x 2 blue x 1; red x 2 0.213333333333333
## 4 x 1.85 blue x 3; red x 1 red x 1 0.18
## 41 y 2.45 blue x 3; red x 1 red x 1 0.18
## 1 x 0.25 blue x 1 blue x 2; red x 2 0.08
## 11 y 0.75 blue x 1 blue x 2; red x 2 0.08
as.data.frame(do.call(rbind, brute_descition_tree_result))
## type split_variable split_threshold
## 1 Root x 1.95
## 2 2 left x 1.45
运行后,获得两个决策节点,绘制决策树如下:
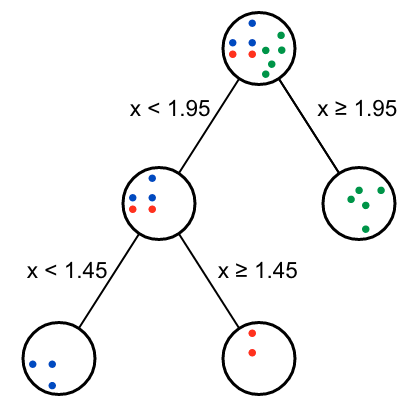
从返回的Gini gain表格可以看出,第二个节点有两种效果一样的分支方式。
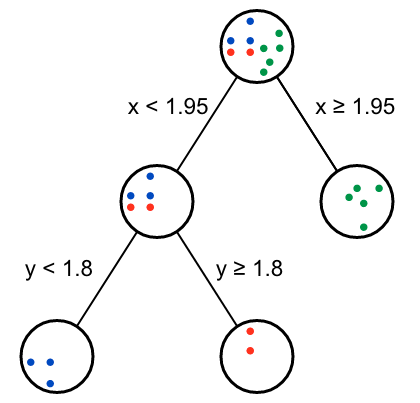
这样我们就用暴力方式完成了决策树的构建。
随机森林
data2
original_gini
uniq_x delimiter_x t(sapply(delimiter_x, split_branch_gini, data=data2, variable_column='x', class_column='color', original_gini=original_gini))
library(rpart)
library(rpart.plot)
library(rattle)
fit fancyRpartPlot(fit)
plot(fit, branch = 1)
https://stats.stackexchange.com/questions/192310/is-random-forest-suitable-for-very-small-data-sets
https://towardsdatascience.com/understanding-random-forest-58381e0602d2
https://www.stat.berkeley.edu/~breiman/RandomForests/reg_philosophy.html
https://medium.com/@williamkoehrsen/random-forest-simple-explanation-377895a60d2d
往期精品(点击图片直达文字对应教程)
机器学习
后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集