大家好,我是曹鑫老师,今天要给大家分享的是网上数据的自动批量搜集整理,大家更熟悉的名字是「爬虫」。
欢迎观看完整视频

扫码预约九宫格数据
线下体验店
在课程开始之前,我要先说一段免责声明:这次课程对于数据抓取的相关知识,只做学术探讨,不要利用抓取到的数据做有损访问网站商业利益的事情,比如你也建立一个同样业务的网站;也不要对访问网站的服务器造成压力,影响正常用户的访问。以上也是大家以后在进行数据采集的时候需要注意的。那我们继续讲技术,数据采集对于我们日常的工作有什么帮助呢?我举个例子。
比如当我们来到CDA官网的直播公开课页面,我们可以看到这里有很多的课程,每个课程的组成部分是一致的,包含了它的主题海报、标题内容、授课老师的介绍和头像,同时我还可以翻页到下一页,看到更多的往期公开课,这种构造相信你在很多网站都看到过,你就要联想到,今天学到的内容,也差不多能应用到类似的网站去。
接下来,如果想要把这些内容全部整理到一张Excel表里面,你该怎么办?第一反应是不是:那就去挨个复制标题,复制老师的名字,复制介绍内容,一个个粘贴到Excel表里?没错,这是我们要做的,但真要拿着鼠标去挨个点,敲着键盘 `Ctrl+C`、 `Ctrl+V`,未免也太累了,这就是日常工作中比较典型的场景:任务操作一点不难,但需要不断重复操作,费时费力。
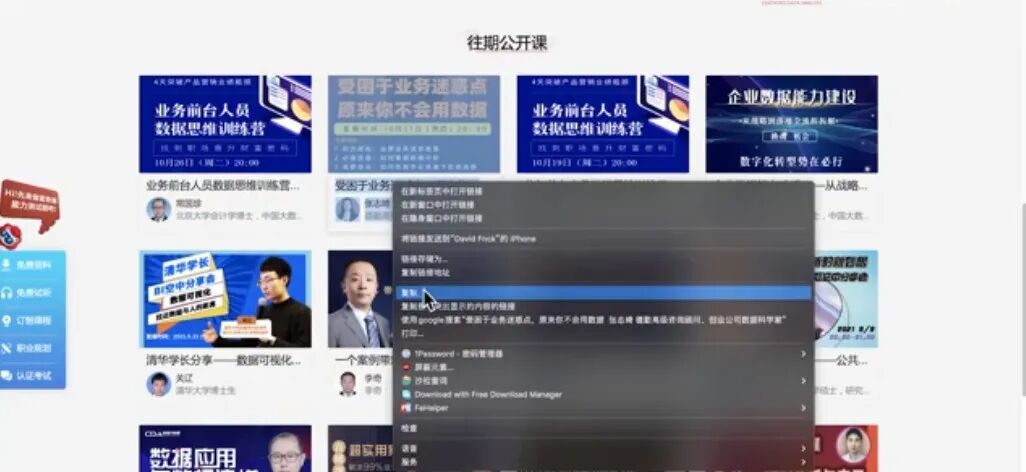
如果掌握了 Python 数据采集,我会怎么来解决这个重复操作的任务呢?我先给你演示一下效果。代码不难,就这么一段,你现在看肯定一头雾水,不要着急,我一段段带你来阅读理解。
第一部分:调用包
第二部分:启动浏览器打开指定网页
第三部分:生成一个空的数据表
第四部分:循环翻页获取数据
第五部分:结果输出成 Excel 表
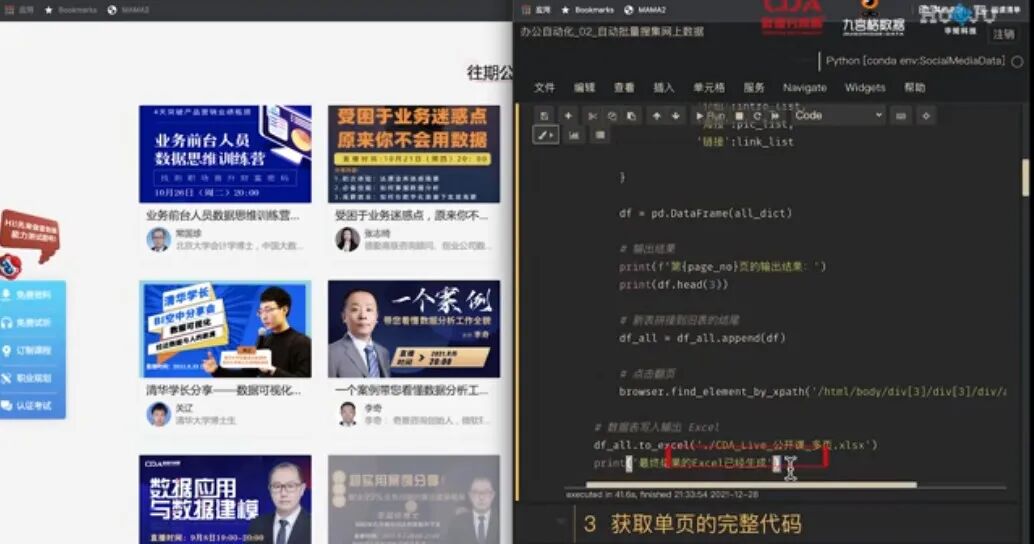
点击`Shift+回车`,我们运行一下代码看看:
1. 浏览器自动打开指定的页面,也就是直播公开课的第一页。
2. Anaconda 中,星号表示该代码区域正在运行,而在代码区域下方会输出打印的结果。
3. 紧接着循环获取数据,代码获取到了第一页的内容,并整理成表格打印出来。
4. 然后,浏览器自动翻页到第二页,又一次获取第二页的内容,并整理成表格打印出来。
5. 继续,第三页,同样的输出。
6. 最后,输出了一个 Excel 文件,我们打开看一下,全部页数我需要的数据都整理好了。
我们想要的效果实现了,有几个好处:
1. 我只点了一下鼠标移动到代码区域;敲了一下键盘 `Shift+回车`启动程序,接下来我就不用再点鼠标或者敲键盘了,全部交给 Python 程序
2. 我现在是获取3页,我要获取10页,100页,1000页,我只要改一下循环这里的数字,让它循环10次、100次甚至是1000次,再也不用多花更多时间和体力,始终就是一点一运行,剩下的体力活全部交给 Python 。
一旦掌握了数据采集技术,类似的重复性工作你都可以自动化完成。
下面是分享给大家的代码,可以自行操作试试哦。
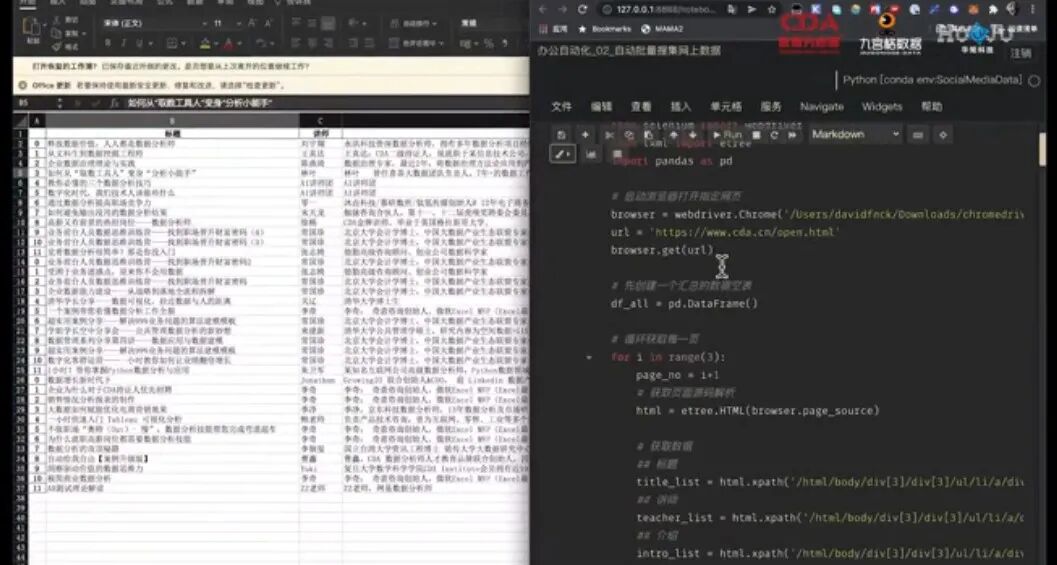
from selenium import webdriverfrom lxml import etreeimport pandas as pd
browser = webdriver.Chrome('/Users/davidfnck/Downloads/chromedriver')url = 'https://www.cda.cn/open.html'browser.get(url)
df_all = pd.DataFrame()
for i in range(3): page_no = i+1 html = etree.HTML(browser.page_source)
title_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/div/h2/text()') teacher_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/div/div/h4/text()') intro_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/div/div/p/text()') pic_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/img/@src') link_list = html.xpath('/html/body/div[3]/div[2]/ul/li/a/@href')
all_dict = {'标题':title_list, '讲师':teacher_list, '介绍':intro_list, '海报':pic_list, '链接':link_list }
df = pd.DataFrame(all_dict)
print(f'第{page_no}页的输出结果:') print(df.head(3))
df_all = df_all.append(df)
browser.find_element_by_xpath('/html/body/div[3]/div[2]/div/a[4]').click()
df_all.to_excel('./CDA_Live_公开课_多页.xlsx')print('最终结果的Excel已经生成')
当下企业数字化转型正快速发展,在越来越严苛的外部监管及越来越激烈的市场竞争驱动下,各行各业都在急迫地对数据进行最大化的价值挖掘。然而,大多数企业在推动落地时,都会遇到诸多问题。快速了解“数据从治理到分析”的落地流程与产出效果,以最低成本实现团队协同,快速解决深奥数据问题,成为越来越多企业加大数字化转型投入的核心动力。
CDA数据分析师作为专注于数字化人才培养及服务的教育品牌, 一直致力于大数据在产、学、 研的融合应用。以“培养企业需要的专业数字化人才, 搭建引领数字化时代的企业人才梯队” 为使命, 为DT时代数字化人才的数据能力提升及企业数字化转型提供标准化、 高效率、 可落地的数据应用侧解决方案。成立15年来, 始终在总结凝练先进数字化商业数据策略及技术应用实践, 以实际行动提升了数字化人才的职业素养与能力水平, 以建设高质量生态圈层促进了行业的持续快速发展。
CDA数据分析师携手华矩科技,以数据治理与数据分析为特色,联合开设九宫格数据体验店北京分店并对外运营。

图-CDA&华矩联合的九宫格数据·数据治理与分析体验店
在数据治理与分析体验店,您可以从技术、业务、管理三大方面全方位体验数据治理与分析。
技术体验方面,您可以体验从数据预处理、数据内码转化、数据结构化处理、数据质量诊断、数据查重与匹配、异构数据集成、特征工程、统计建模、机器学习、模型诊断与调优等技术科目;
业务体验方面,您可以基于模拟真实业务场景的数据体验客户统一视图、合规检查、遵从度检查、数据溯源、代码标准化、SKU标准库、商业策略优化、用户分群与画像、业务分析与预测及风险识别等数字化场景;
管理体验方面,您还可以从团队或项目管理的角度体验数据安全管理、数据治理与分析不同岗位角色及团队协作、数据问题跟踪管理、数据质量监控、数字化工作方法及BI可视化报告。
而CDA数据分析师与华矩科技的强强联合,也赋予了数据治理与分析体验店更多特色体验,主要包括:
数据治理与分析理论培训+实操演习
针对志在数据治理与数据分析发展领域的个人及企业提供相关理论培训课程及实操体验,旨在让零基础学员通过理论学习与技能习得掌握数据治理及数据分析应用,快速让数据价值变现。
数据治理+数据分析全流程体验
基于体验店提供的模拟场景测试数据,通过平台数据治理实操输出高质量的数据,导入相关数据分析算法模型,从而获得有价值的分析结果。该体验服务重点针对个人学员的技能习得,及企业数据团队协同,使其可以真正学会数据处理技能了解各环节的关系,从而可以真正用到自己的工作中。
区别于以往很重的数据治理咨询与实施,华矩科技首创的九宫格数据体验店模式让用户可以更轻更快地了解与体验数据治理,并在体验店获得场景模拟,团队协同和报告输出。主要包括:
直观感受数据价值
端到端全流程体验
场景化的模拟实验
技术业务快速协同
模拟真实测试数据
快速解决数据问题
模拟练习创新体验
项目前期团队实操
专业顾问咨询辅导
新店试业期间,九宫格数据·数据治理与分析体验店数个技术场景科目免费体验,从数据预处理、数据探查与诊断、数据清洗规则与标准化设计、数据集成、数据优化、数据质量监控到数据分析和数据挖掘等全流程场景,了解数据从产生到处理到应用的相关逻辑与实操路径,实现一个闭环体验并赋能个人技能习得或团队项目预演。
1. 体验店开放地点
广州店:广州市天河区体育东路122号羊城商贸中心西塔1010
深圳店:深圳市福田区新闻路华丰大厦303
北京店:北京市海淀区高梁桥斜街59号院1号楼13层1306
2. 体验店开放时间
周一至周五 9:00-18:00
3. 体验预约流程
填写预约申请表单——后台审核体验资格——沟通确认体验时间地点——上门体验
4. 体验内容说明
每个场景科目均包含高级顾问辅导与自由实操环节,以确保用户了解操作方法并能自主操作获得结果。如需更多操作原理与数据治理与分析理论方法,敬请关注体验店后续推出的培训课程。
5. 温馨提示
新店开业期间针对既定科目场景开放免费体验,限时限量,请尽快预约体验。
不同科目体验涉及不同时长,敬请注意体验期间差旅住宿餐饮等费用需自理。
*该活动最终解释权归九宫格数据·数据治理与分析体验店所有。









