这个项目登上了今天的GitHub Trending。
近一两年,Transformer 跨界 CV 任务不再是什么新鲜事了。自 2020 年 10 月谷歌提出 Vision Transformer (ViT) 以来,各式各样视觉 Transformer 开始在图像合成、点云处理、视觉 - 语言建模等领域大显身手。之后,在 PyTorch 中实现 Vision Transformer 成为了研究热点。GitHub 中也出现了很多优秀的项目,今天要介绍的就是其中之一。该项目名为「vit-pytorch」,它是一个 Vision Transformer 实现,展示了一种在 PyTorch 中仅使用单个 transformer 编码器来实现视觉分类 SOTA 结果的简单方法。项目当前的 star 量已经达到了 7.5k,创建者为 Phil Wang,ta 在 GitHub 上有 147 个资源库。
项目地址:https://github.com/lucidrains/vit-pytorch

首先来看 Vision Transformer-PyTorch 的安装、使用、参数、蒸馏等步骤。$ pip install vit-pytorch
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
最后是蒸馏,采用的流程出自 Facebook AI 和索邦大学的论文《Training data-efficient image transformers & distillation through attention》。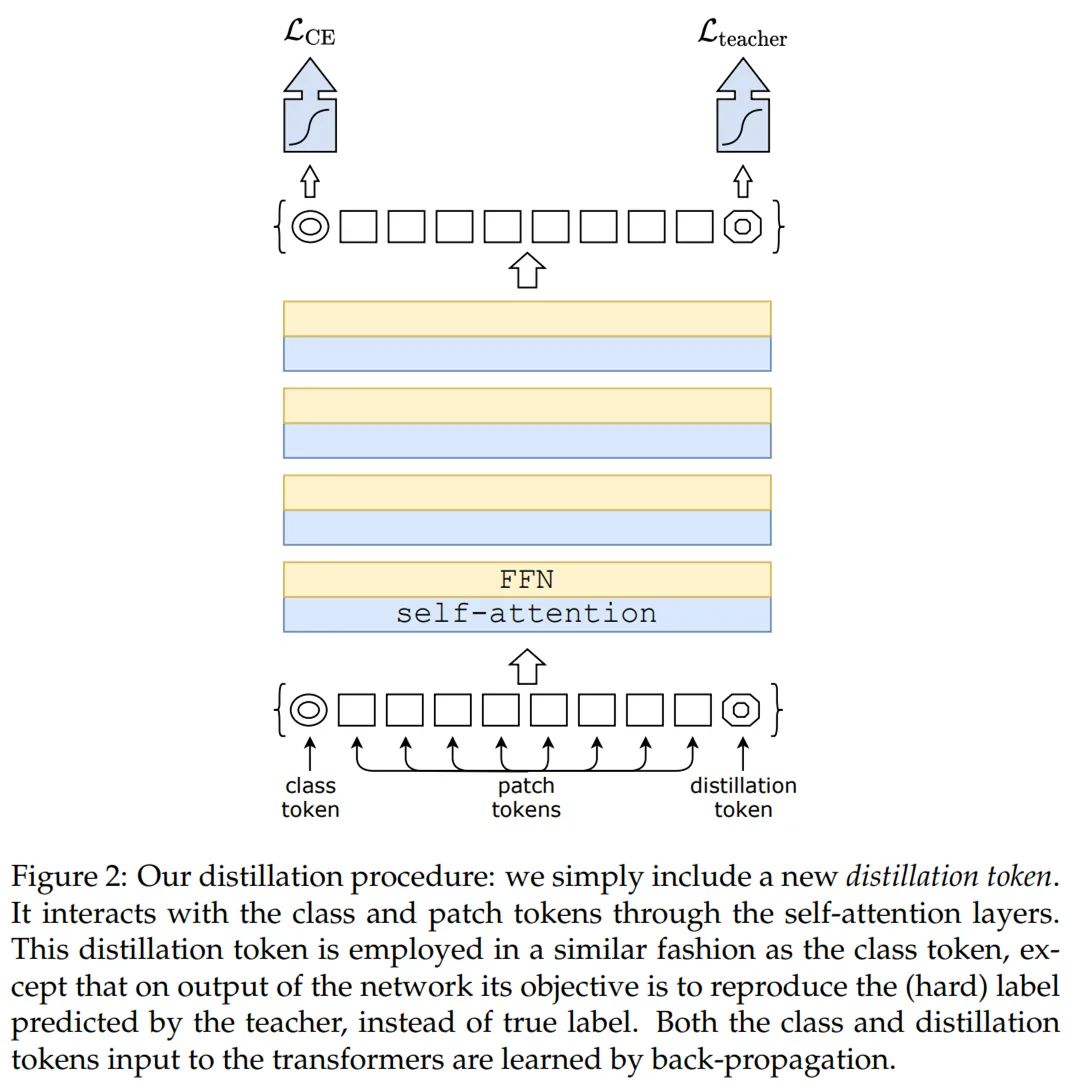
论文地址:https://arxiv.org/pdf/2012.12877.pdf
从 ResNet50(或任何教师网络)蒸馏到 vision transformer 的代码如下:import torchfrom torchvision.models import resnet50from vit_pytorch.distill import DistillableViT, DistillWrapperteacher = resnet50(pretrained = True)
v = DistillableViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
distiller = DistillWrapper(
student = v,
teacher = teacher,
temperature = 3, # temperature of distillationalpha = 0.5, # trade between main loss and distillation losshard = False # whether to use soft or hard distillation
)
img = torch.randn(2, 3, 256, 256)labels = torch.randint(0, 1000, (2,))
loss = distiller(img, labels)loss.backward()
# after lots of training above ...pred = v(img) # (2, 1000)
除了 Vision Transformer 之外,该项目还提供了 Deep ViT、CaiT、Token-to-Token ViT、PiT 等其他 ViT 变体模型的 PyTorch 实现。
对 ViT 模型 PyTorch 实现感兴趣的读者可以参阅原项目。
重磅!
AI有道年度技术文章电子版PDF来啦!

扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连 







