机器学习,深度学习已经变得越来越重要,其中的算法与模型也开始慢慢渗透到我们生活之中。圣诞假期读到一篇非常有趣的综述,主要的内容是讲作为生物学家,如何进行机器学习的学习。下面和大家一起学习这篇文章。
背景知识
简单来说,我们人类学习新事物就是一个机器学习的过程。人类通过观察周围的世界来理解周围的世界,并学习预测接下来会发生什么。比如,一个小孩想学习进行接球,他对控制抛球运动的物理定律一无所知;然而,通过观察、反复试验的过程,孩子调整了他或她对球运动的理解,以及如何移动他或她的身体,直到他或她能够可靠地接住球。换句话说,孩子已经学会了如何接球,方法是建立一个足够准确和有用的过程“模型”,根据数据反复测试这个模型,并对模型进行修正。
“机器学习”泛指将预测模型拟合到数据或识别数据中的信息分组的过程。机器学习领域本质上试图通过计算来近似或模仿人类识别模式的能力。生物的数据量不断扩大,并且其复杂性也在扩增,这促使机器学习在生物学中的应用越来越多。在这篇综述中,作者旨在为读者简要介绍一些关键的机器学习技术,包括最近开发和广泛使用的涉及深度神经网络的技术。并描述了不同的技术如何适用于特定类型的生物数据,并讨论了一些最佳实践和在开始涉及机器学习的实验时要考虑的要点。最后还讨论了机器学习方法中的一些新兴方向。
关键概念
本次推文,主要介绍机器学习中的一些关键概念。并且给出生物学相关的例子,帮助你去理解。
基础概念:
数据集包含许多数据点或例子,每个数据点或例子都可以被认为是实验中的单个观察结果。每个数据点由固定的数量的特征描述。例如,长度、时间、浓度和基因表达水平。机器学习任务是我们希望机器学习模型完成什么的客观输出。例如,对于研究随时间推移基因表达的实验,我们可能想要预测特定代谢物转化为另一个物种的速率。在这种情况下,特征“基因表达水平”和“时间”可以称为输入特征或模型的输入,而“转化率”将是模型的期望输出;也就是我们感兴趣预测的数量值。一个模型可以有任意数量的输入和输出。特征量可以是连续的(采用连续数值)或分类的(仅采用离散值)。很多时候,分类特征是二元的,要么为真(1),要么为假(0)。
有监督和无监督学习
监督机器学习是指模型与已标记的数据(或数据子集)的拟合,但其—存在一些 基本的已知变量,通常由人类通过实验测量或分配。比如,蛋白质二级结构预测和基因组调控因子的基因组可及性预测。在这两种情况下,基本的已知量来自实验室观察,但这些原始数据通常以某种方式进行了预处理。例如,在二级结构的情况下,可以利用数据来,分析蛋白质数据库中的蛋白质晶体结构数据。相比之下,无监督学习方法能够识别未标记数据中的模式,而无需以预定标签的形式向系统提供基本事实信息。例如在基因表达研究中找到具有相似表达水平的患者子集或从基因序列共变预测突变效应。有时这两种方法在半监督学习中结合使用,其中少量标记数据与大量未标记数据结合。这样的方法可以提高性能。
分类、回归和聚类问题
当问题涉及将数据点分配给一组离散数据时(例如,“癌性”或“非癌性”)时,该问题称为“分类问题”,任何执行此类的算法都可以叫作分类器。相比之下,回归模型输出一组连续的值,例如预测蛋白质中的残基突变后折叠的自由能变化。连续值可以被阈值化或以其他方式离散化,这意味着通常可以将回归问题重新表述为分类问题。例如,上面提到的自由能变化可以分为对蛋白质稳定性有利或不利的值范围。聚类方法用于预测数据集中相似数据点的分组,并且通常基于数据点之间的某种相似性度量。它们是无监督方法,不需要数据集中的示例具有标签。例如,在基因表达研究中,聚类可以找到具有相似基因表达的患者子集。
类和标签
分类器返回的离散值集可互斥,在这种情况下,它们被称为“类”。在这些值不相互排斥的情况下,它们被称为“标签”。例如,蛋白质结构中的残基可以仅属于多个二级结构类,但也可以同时看作非排他性标签(α-螺旋和跨膜)。
损失或成本函数
机器学习模型的输出永远不会是理想的,并且会偏离基本事实。衡量这种偏差的数学函数,或更笼统地说,衡量获得的输出和理想输出之间的“不一致”量的数学函数称为“损失函数”或“成本函数”。在监督学习设置中,损失函数将是输出相对于实况输出偏差的度量。比如,回归问题的均方误差。
参数和超参数
模型本质上是对一组输入特征进行运算,并产生一个或多个输出值或特征的数学函数。为了能够在训练数据上学习,模型包含可调整的参数,其值可以在训练过程中更改,以实现构建最佳模型。例如,在一个简单的回归模型中,每个特征都有一个乘以特征值的参数,然后将它们相加以进行预测。超参数是可调整的值,不被视为模型本身的一部分,因为它们在训练期间不会更新,但仍会对模型的训练及其性能产生影响。
训练、验证和测试
在用于进行预测之前,模型需要训练,这涉及自动调整模型的参数以提高其性能。在监督学习设置中,这涉及修改参数,以便模型通过最小化损失或成本函数的平均值。通常,使用单独的验证数据集来监控,但不影响训练过程,以检测潜在的过度拟合。在无监督的设置中,成本函数仍然被最小化,尽管它不在地面实况输出上运行。训练模型后,可以在未用于训练的数据上对其进行测试。
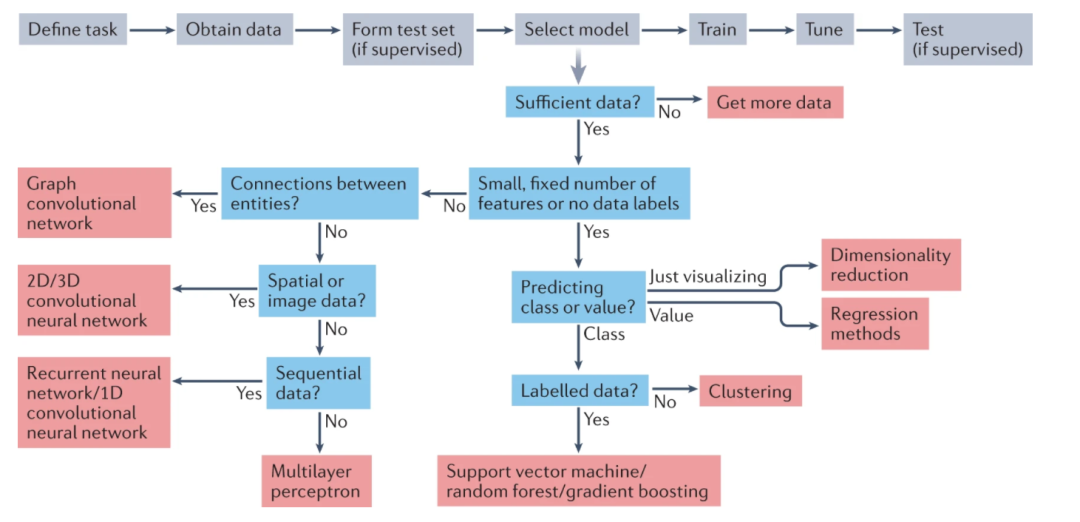
下图是机器学习中模型选择的决策树和机器学习训练的流程和方法:
过拟合和欠拟合
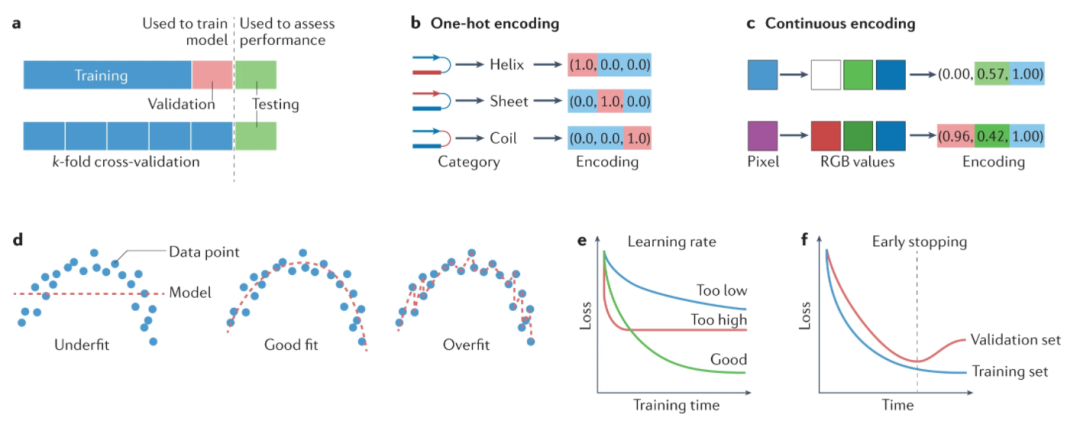
将模型拟合到训练数据的目的是捕捉数据中变量之间的“真实”关系,从而使模型对看不见的(非训练)数据具有预测能力。过拟合或欠拟合的模型,将对不在训练集中的数据产生较差的预测。过拟合的模型会在训练的数据上产生出色的结果(通常是由于参数过多的结果),但会在看不见的数据上产生较差的结果。上图过拟合模型 准确地通过每个训练点,因此它在训练集上的预测误差为零。然而,很明显,这个模型已经“记住”了训练数据,并且不太可能在看不见,或者没见过的数据上产生好的结果。相比之下,欠拟合模型无法充分捕捉数据中变量之间的关系。这可能是由于模型类型选择不正确、对数据的假设不完整或不正确、模型中的参数太少和/或训练过程不完整。在这种情况下,很明显变量具有非线性关系,这不能用简单的线性模型来充分描述,因此非线性模型会更适合。
归纳偏差和偏差-方差权衡
模型的“归纳偏差”是指在学习算法中做出的一组假设,它可以被认为是模型对学习问题的特定类型解决方案的偏好,而不是其他解决方案。不同模型类型中的不同归纳偏差使它们更适合,并且通常对特定类型的数据表现更好。另一个重要的概念是偏差和方差之间的权衡。可以说具有高偏差的模型对训练模型有更强的约束,而具有低偏差的模型对所建模的属性的假设较少,并且理论上可以对多种函数类型进行建模。模型的方差描述了经过训练的模型响应在不同训练数据集上训练而发生的变化。控制偏差-方差权衡是避免过拟合或欠拟合的关键。一般来说,我们希望模型具有非常低的偏差和低方差,尽管这些目标经常相互冲突,因为具有低偏差的模型,通常会在不同的训练集上,学习不同的信号。
今天的分享就到这里,希望大家对机器学习的基本概念有所了解,下一期推文会继续和大家学习这一篇文章。
参考文章:
A guide to machine learning for biologists
https://doi.org/10.1038/s41580-021-00407-0








