
基于深度学习技术的模型主导了现代工业级推荐系统的行业格局。现代推荐系统在大量场景中获得了实际应用。在规模不断扩大的深度神经网络模型的推动下,它们取得了一系列令人难以置信的成果和进步。
然而,即使在工业级规模的数据中心内,此类模型的训练工作也是一大挑战。这一挑战的根源在于训练工作的计算过程所具备的极高异质性 —— 模型的嵌入层可能占整个模型大小的 99.99% 以上。整个过程非常耗费内存,而神经网络(NN)的其余部分则逐渐向计算密集的方向发展。
快手科技与苏黎世联邦理工学院的研究团队共同发布了基于革命性混合训练算法的高效分布式训练系统 PERSIA(混合加速并行推荐训练系统)。这种方法为拥有多达百万亿参数的巨型深度学习推荐系统提供了很高的训练效率和精度。研究人员精心设计了其中的优化方法和分布式系统架构。
Persia 的能力来源于多项技术成果。Persia 的核心技术假设将混合和异构的训练算法与异构系统架构设计结合在了一起。研究人员这样做的目标是将训练推荐系统的性能提升到当今无法达到的水平上。
这项研究将推荐模型的各项属性与其收敛性联系在了一起,以证明其有效性。研究人员描述了一种自然但不常见的混合训练技术,触及嵌入层和密集神经网络模块。此外,该研究还对其收敛行为做了详尽的理论描述。在快手,PERSIA 使用公开可用的基准测试和现实工作负载进行了评估。
研究人员最初提出了一种同步 - 异步混合方法,其中嵌入模块会进行异步训练。同时,密集神经网络会同步更新。在不牺牲统计效率的情况下,这种混合方法实现了与完全异步模式相当的硬件效率。
PERSIA 的设计基于两个基本理念:
训练工作流在不同集群中的分布
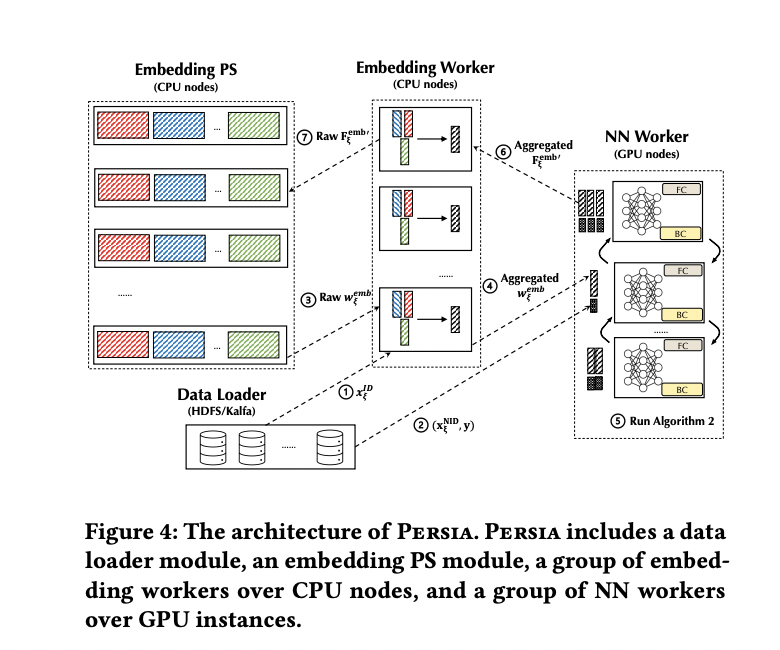
相关的混合基础设施训练进程PERSIA 有四个模块,为推荐系统提供高效的自动缩放能力:
从 Hadoop、Kafka 和其他分布式存储系统中提取训练数据的数据加载器;
一组嵌入 worker 使用优化算法从嵌入 PS 中提取嵌入参数。它们再将嵌入梯度放回嵌入 PS 和聚合嵌入向量(如果有的话)
嵌入参数服务器(简称嵌入 PS)负责监督嵌入层中参数的存储和更新。
许多 NN worker 运行神经网络 NN 的前向 / 后向传播。研究团队针对三个开源基准(Taobao-Ad、Avazu-Ad 和 Criteo-Ad)以及快手的真实生产级微视频推荐管道对 PERSIA 进行了测试。他们使用了 XDL 和 PaddlePaddle 这两个前沿分布式推荐训练系统作为基线参考。
与其他系统相比,新混合算法获得了更高的吞吐量。PERSIA 在 Kwai-video 基准测试中实现了比完全同步方法高 2.8 倍的吞吐量。即使模型大小增加到 100 万亿个参数,PERSIA 也表现出了稳定的训练吞吐量,达到完全同步模式吞吐量的 2.6 倍。
PERSIA 已在 GitHub 上作为开源项目提供,其中包含在谷歌的云基础架构上设置系统的详细说明。研究人员预计,他们的研究和发现将对学术界和工业界都有所帮助。
论文:https://arxiv.org/pdf/2111.05897.pdf
Github:https://github.com/persiaml/persia
原文链接:
https://www.marktechpost.com/2021/12/05/researchers-introduce-persia-a-pytorch-based-system-for-training-large-scale-deep-learning-recommendation-models-up-to-100-trillion-parameters

你也「在看」吗?👇








