编者荐语:
近年来深度学习在量化选股中的应用受到业界高度关注,1月11日,华西证券金融工程团队邀请到宽邦科技首席策略邵守田总,就《深度学习在量化选股中的实践》做主题分享,以下为分享内容整理。
以下文章来源于BigQuant ,作者BigQuant


1月11日晚,华西证券研究所举办金工行业路演,宽邦科技首席策略官邵守田受邀进行《深度学习在量化选股中的实践》分享,整个分享分为5个部分:
1、行业发展
2、宽邦科技简介
3、人工智能简介
4、学习常见网络概览:DNN、LeNet、seq2seq、RNN、CNN、Tabnet、Transformer
5、深度学习量化选股实践:因子生成、基准模型、对照测试、滚动训练
BigQuant整理文字实录如下,以飨读者。文字总共6300字,大概会花费您15分钟左右时间。
我们观察到有这样的趋势,以AI为代表的科技创新,目前正在重塑整个资产管理行业,一些类专业的投资管理公司,比如说券商、期货的资管、银行理财子公司,它们现在正在向买方专业投资机构进行升级。
再看看量化私募发展的情况,据中信研究所的估计,从规模来看,2021年三季度量化私募规模已经达到了1.4万亿,当然各家对这个数据的统计口径可能会有些差异。再从比例上来看,量化的占比已经达到了18%。如果从2016年的5%再看18%的比例,年均增长速度高达47%。这个标题指的是机器学习使用比例超过50%,这个数据是两年前国外一家对冲基金研究机构给出的数据。不仅如此。我们宽邦科技上个月联合多家机构做了《2021年中国量化白皮书调研》,我们发现国内只有不到20%的量化机构未使用AI量化。我们发现这些机构在想法分层生成、因子的挖掘、模型构建、组合构建、交易执行、风险管理都有使用,大部分还是在因子挖掘上面。
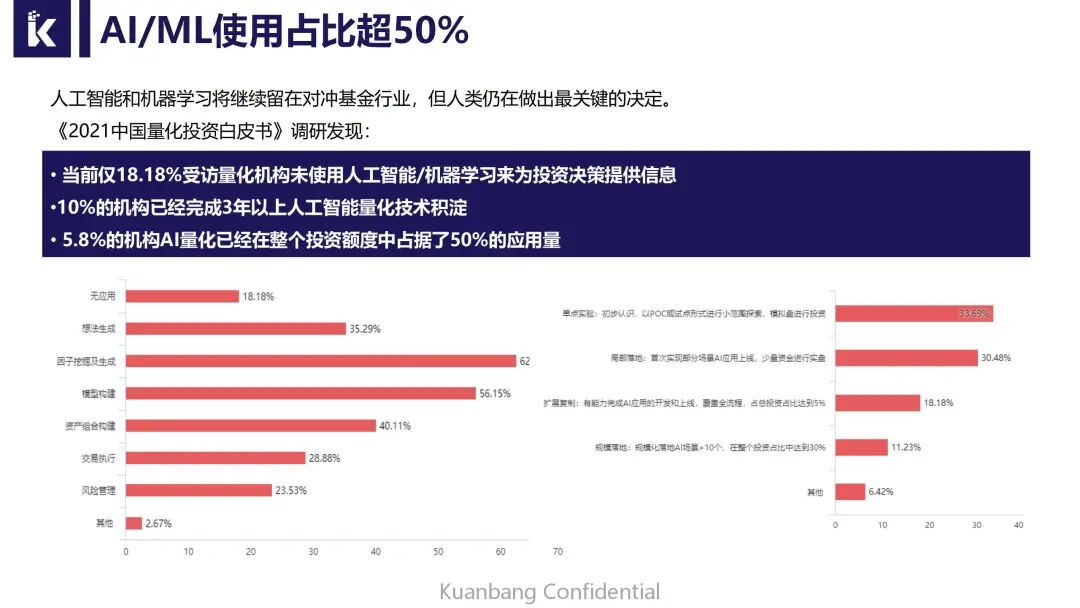
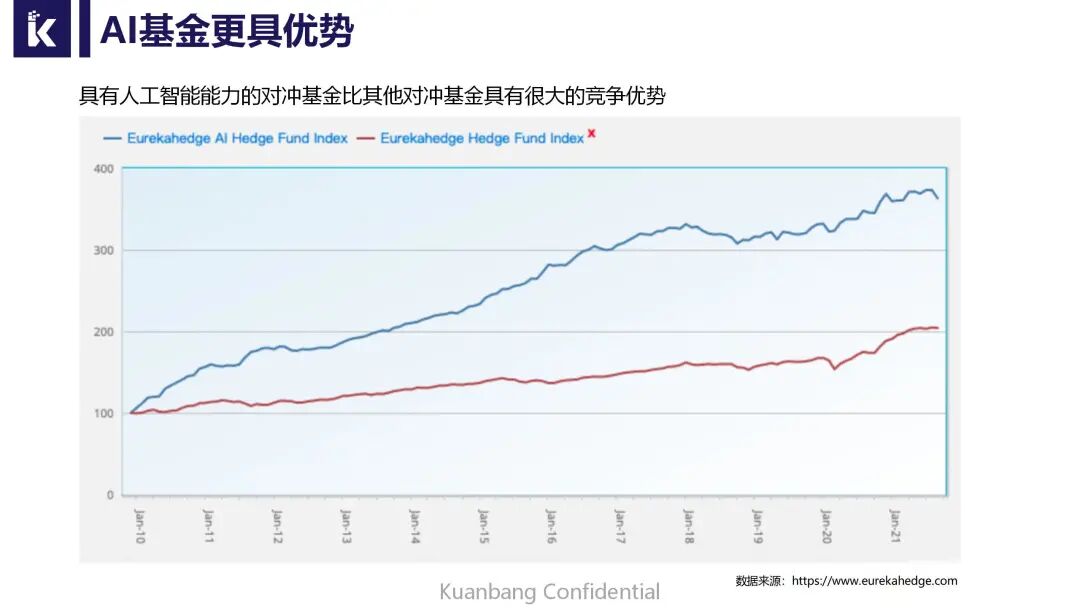
右边这个图也能看出来,其实已经超过11%的机构他们在落地AI量化,AI量化的场景超过10个,在他们的投资占比中高达30%。所以说我们看到AI机器学习,在量化投资里面欣欣向荣,并且未来有很大发展空间。这是国外的对冲基金调查结果,总体结果就是说蓝色这条线就是AI对冲基金的表现,红色是市场平均对冲基金。我们可以看到AI基金表现更加优秀,这也是很多大型机构他们愿意花巨资从高校、工业界去抢人的原因,因为确实AI量化能给他们带来一定的收益。
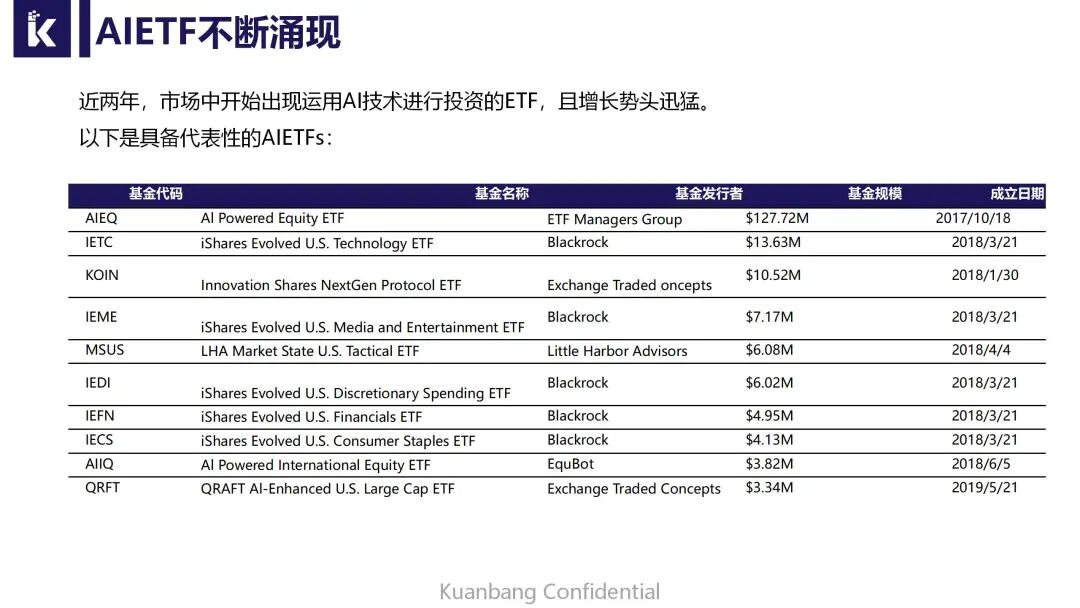
图表上列举了主要的国外AIETF,纯使用AI技术来进行投资的一些ETF。最早的AIETF叫AIEQ,是2017年在纽交所上市的一个纯人工智能的基金。
这些基金是通过全市场每天算法、程序,从数据里面去寻找规律,自动构建投资组合。
接下来简单介绍一下我们宽邦科技,宽邦科技是一家AI公司,成立于2016年,创始人为梁举。我们主要是想打造以大数据和AI为核心的下一代投资平台,引领投资管理行业进入智能投资时代。从右边这些图可以看出来,我们目前的客户是一些大型机构,比如银行、券商、资管、保险等等。梁举是创始人也是CEO,毕业于北京大学,后来在微软亚洲研究院从事必应搜索引擎的研究工作,看到了机器学习的价值,所以说他就想把AI的价值用在量化投资领域,所以我们就成立了宽邦科技。我们的核心团队是以复合AI和金融背景的(人员)组成团队。
我们详细介绍AI,更多会从深度学习进行介绍,因为AI也是一个很大的范畴。 深度学习是什么?深度学习是人工智能的子领域,人工智能是什么?其实并不遥远也并不神秘,就在我们身边。但是大众理解的人工智能和专家理解的人工智能,有很大的偏差和距离。大众理解的人工智能往往出现在类似于《终结者》或者是《星际穿越》这样的科幻电影里面,这些机器人它们能思考、能认知,甚至有情感,这是超强人工智能。人类社会距离超强人工智能,还有很长的距离。我们今天交流的人工智能,其实指的是弱人工智能,或者说专项人工智能。为什么是专项人工智能?是指这些AI技术只能在特定领域取得好效果,比如说语音识别、模式识别,这些领域AI可以发挥特定的效用。在学术界,深度学习也是一门系统性及理论性极强的自然学科。在进行深度学习研究的过程中,前期咱们其实也没有必要自研算法。因为在互联网界,很多互联网大厂比如说微软、谷歌,它们会开源很多工业界成熟的算法和论文,这些算法可以直接拿来使用。我们可以看到,其实金融界对于算法的使用,和互联网界相比,还是会有4-5年的时间差。比如说Transformer模型,这是最近比较火的模型,2017年就在谷歌开源了。深度学习最主要的框架就是TensorFlow和PyTorch,我们用这两个就差不多了,研究人员也没有必要开发自己的框架,造轮子的事情让大厂去做,我们能够用好这些轮子就行。
深度学习算法从智能上看到其内涵,“学习”指的是它能够从数据里面去获取智能,能够不断地学习到一些规律,不断进步。“深度”是指它有多个隐藏层,或者这个数据会进行多次非线性转换,每次转换我们进一步提高预测能力。深度学习的核心其实也是有意进行数据转换、数据变换,能够从我们的数据输入到数据输出,建立良好的预测能力。深度学习也是对人脑的模拟,其实人脑它是一个很强大的神经网络,至今也没有被我们研究人员完全理解。网络里面有很多节点我们称为神经元或者神经细胞,神经元是携带和传输信息,它的上游有一些信号,这些信号传给细胞,细胞进行处理通过连接传给其他的神经元,这就是大体的工作机制。我们的研究人员正是通过对大脑的模拟,就创建了人工神经元。人工神经元主要是通过求和或者是一些非线性的激活函数的操作,就可以对上游传过来的一些信号进行加工处理,并输出到下一个神经元,这就是我们通过神经网络模型,模拟我们大脑连接的情况。我们来看一个简单的神经网络,它具有一个输入层、两个隐藏层,以及一个输出层。每一个层其实就是神经网络基本的数据结构,每个层里面有多个神经元,最后一个层是输出层,比如说未来一段时间股票的收益率,就是一个神经元。如果我们不要中间两个隐藏层,就是金融里面的三因子模型。比如说预测收益率,我们的输入层就是各类因子等,所以说它是一个多因子模型。只是我们加入两个隐藏层以后,这个网络模型会更为复杂。神经元与神经元之间连接的箭头,就是我们理解的权重,是一个未知变量。深度学习或者训练的过程就是寻找连接的过程,把它的数值定化,这就是学习的过程。我们通过这个图可以看到,其实是把输入层的数据通过多个数据转换,其实就是多个隐藏层,得到一个预测结果,这个传递的方向最简单的模型就是前向反馈网络,得到反馈我们再跟真实值进行比较。通过比较,我们就可以建立一个损失函数,不断更新权重去减少损失函数,这样一个不断迭代的过程。我们损失函数求解降低到最低的时候,我们那组模型的权重就实例化了AI模型。损失函数可以衡量我们预测结果和实际目标值之间的差异。我们也可以通过优化器更新我们的权重,这个优化器就是更新网络模式的一个模式、制度、机制。我们会通过一些监控指标监控我们神经网络,它是一个怎样的训练结果。所以说损失函数、优化器、监控指标,就是我们构建神经网络的核心。过拟合也是AI被诟病最多的问题,我们可以通过工业界或者研究界一些最佳实践的方式、技巧规避这些过拟合。比如说我们增加更多的训练数据,这个是减少我们网络的容量,让我们的神经元数量减少,这样我们的模型会更简单,过拟合的概率也会更低。我们也会有其他的一些方式,比如说是否有一些dropout;是否有一些隐藏层数据的处理,比如说批归一化;以及我们是否需要设计一些提前停止这样的机制,或者是我们通过自动机器学习的方式,寻找到不管是参数或者是超参数等等,这些方式都是我们防止过拟合的一些常用的方法。
因为我们本次更多是AI量化的概览介绍,所以说也不会对算法做细节原理的介绍。后面有机会,我们可以进行专项介绍,今天更多是介绍一下常见模型。第一个模型是DNN,一个全连接神经网络。如果我们把隐藏层去掉,其实就是多因子模型,这也是简单的算法。我们量化白皮书调查过程中,了解到一些机构他们的AI应用就是简单的算法,比如说DNN。这里要谈到的就是卷积神经网络,CNN就是卷积神经网络的简称。CNN最开始是在计算机视觉问题上表现卓越,这个模型也主要是通过卷积、池化的一些操作,这些操作能提取到一些局部的特征。在我们金融里面构建因子的时候,比如说我们构建一些时序的移动平均因子,或者说最近多少天最大值、最近多少天最少值,这样一些操作就是池化的操作,所以说卷积和因子有天然的统一。
CNN最开始是人工智能三巨头之一杨乐昆他在80年代提到的,为了表彰他的贡献,业界也提出了LeNet,其实就是为了和杨乐昆姓名联系在一起。
这个网络既用到了全连接神经网络,又用到了卷积神经网络。在九十年代美国的银行业,在一些字符识别的场景里面取得很好的效果。下面一个模型是RNN模型,是循环神经网络,解决sequence to sequence的问题,比如说怎么翻译等等,最开始也用在NLP领域。在金融场景,因为我们的因子或者数据本身也是时序的特征,我们可以在预测未来的时序里面用股票的因子,就可以用到循环神经网络。对循环神经网络稍微进行改变就可以延伸很多模型,比如说GRU或者LSTM,长短期记忆网络的一些模型,这都是目前有应用的。下面一个模型是Tabnet,是谷歌2020年开源的算法,这个算法主要解决了决策树算法和全连接神经网络算法结合的问题,它能够既有DNN强大的预测能力,又能结合一些集成学习、决策树的模型,那些模型比如说有一些评价哪些因子的重要性。下面一个算法也是这两年比较火的算法,这个算法应该是谷歌在2017年就开源的算法,这个算法近两年也是在AI领域大杀特杀。不仅是在图像识别,还有NLP、翻译里面,在其他的一些预测里面,比如说智能推荐,也是有很高的应用。在金融里面,其实用Transformer来构建模型也有一定的应用,而且大家都会对这些算法进行略微的改动。最常见的改动,因为我们Transformer模型是基于注意力机制的模型,既带有编码器,又带有解码器,最开始解决sequence to sequence的问题,文本翻译的问题。但是我们金融里面又不是sequence的预测问题。所以说很多的改良,直接把解码器去掉了,在这个地方我们加入了一个全连接神经网络,也能取得一些好的效果,比DNN效果还好。
接下来进入到今天的正题,就是怎么基于深度学习进行量化选股的实践工作。
第一部分是因子生成。因为我们要介绍一个算法或者模型的效果或者最佳实践,我们这里没有采取一些信息含量比较好的因子,而是使用了一些比较基础的因子,基于一些简单的算法,构建了Deep Alpha-DNN、Deep Alpha-CNN,Deep Alpha-LSTM、Deep Alpha-Transformer等系列深度学习的一些研究。
我们算法里面肯定要传入一些是因子数据,这里为了检验我们因子的效果,尤其是量价因子的效果,以及看我们有效市场假说理论有没有依据,做出一些短周期行情的模型。所以我们没有用到财务因子或者其他一些基本面因子,而是只有高开低收这样的一些因子。因为如果市场有效,其实很多信息也会反映在价量里面。在使用价量的时候,我们也不是直接使用高开低收、成交额、成交量这样一些比较基础和原始的因子,而是通过表达式,比如说时序平均、时序最大值、时序最小值、标准差、时序排序、时序加权平均、时序相关性、偏移。我们通过因子的构建一共构建出了98个因子,这里介绍了这些因子的构建方法。 我们在使用Deep Alpha-DNN模型的时候,我们的训练集是2010年-2017年,我们的测试集是2018年-2022年。这个训练集和测试集最重要的是
注意到时间不要有交叉,不然会有未来函数。因为我们是短周期的模型,预测目标就是未来一段时间的收益率,我们设置的预测是未来5天的收益率。在数据处理方面,虽然使用的是一些价量因子,但是我们也进行了数据的预处理,包括特征的标准化、标注的标准化、去极值等等。我们的模型一共是有5层,包括了1个输入层和1个输出层,每个层采用的是一些常见的参数设置:学习率是0.01:Dropout比例是0.1。第一层有98个输入单元,对应98个因子数量。Batchsize是1024,尽量选择128的倍数。epoch是30个迭代,20个、30个都可以,这只是我们的超参数而已。我们损失函数就是均方误差,来衡量我们预测结果和实际结果的偏差,通过预测结果进行投资组合进行回测,目前设置了几十支股票,股票设置得越少,收益率越高,但是风险也会越大。如果我们是大基金,可以把数量设置为200支。这是截止到1月7日DNN模型的预测结果,没有进行任何参数的调优。看到DNN算法,确实有一定的选股效果,它的年化收益达到了26%,基准收益19%,夏普比率是0.87左右,这是没有进行任何参数调整的情形。我们看到使用这些深度学习的算法,确实是可以产生一定的预测能力。因为模型过拟合是为大家诟病最多的问题,所以说模型会不会不稳定、不稳健、波动很大,所以说我们进行了很多对照测试,看看对照测试的效果。我们在对照测试主要是使用了一些超参数、学习率、优化器、损失函数进行设置,包括batchsize,以及数据预处理是否进行一些标准化处理。总体而言,我们经过多次测试发现这个模型基本比较稳健,年化收益率基本上达到20%-30%,但是回撤也很大,因为本身这就是一个选股模型,没有进行择时或者风控,所以说回撤也很大,大概是这样的情况。 这是对照组的一些表现,我们看到它整体还是比较稳健,一个超参数稍微改动,不会有太大的波动。
因为我们刚刚的模型是用2017年以前的数据进行测试,检验后面的效果,这并不符合我们实际工作的方式,因为我们实际工作中,我们的模型也是定期去更新的,比如说每3个月、每半年、每一年。我们会不断根据最近市场的表现、风格更新我们的模型、权重。我们使用滚动训练的一个机制,比如说每4年的数据作为训练集,每1年的数据作为预测集。第一次相当于2013年以前的数据作为一个训练集的训练模型,并得到2014年的预测结果。第二个模型就是在2014年底的时候,因为我们又多了一年的数据,所以我们用最近4年的数据更新模型,预测2015年的结果,又得到2015年的数据,不断滚动。这样的好处是我们可以更新我们的模型,让我们的模型能够结合市场的表现,去做适当的调整。通过滚动训练我们发现,它的效果比我们刚刚看到的单次训练方式更好。这里我们也给出了它按年度回测的收益率。可以看出,2014年收益率很高,有120%。2015年更高,因为那年有牛市。2018年就亏了不少,亏了20%,和基准差不多,基准亏了25%左右。通过这样的一个年度收益的分布,我们其实看到这个模型在大部分的年份是赚钱的。它的表现也会结合市场的表现,如果大盘表现得不太好,这个模型表现也不会很好。这是我们把几年的数据分段回测拼接起来大概的结构图,2014年开始它的收益翻了几十倍,达到了35倍左右。2018年的回撤也是比较大的。也会有一段时间它的收益在盘整。因为我们是一个行情的价量短周期模型,这个模型对我们的手续费是否敏感,这个地方我们也进行了批量测试,这个测试主要是调高我们的手续费,尽可能考虑冲低成本对我们的策略收益的影响。从这个图可以看到,由于我们设置了更高的手续费,我们的年化收益会得到很大的侵蚀。这里设置了多组手续费,比如说买入卖出手续费0.0003,这是默认的情况,它的年化收益有60%多。我们不断加高这个手续费,加高到双边如果0.00的手续费,最后33%的年化收益,买入0.002,卖出是0.004,它的收益率基本上有30%左右。这个模型也是,因为我们自始至终都没有进行择时和风控,所以它的最大回撤是比较大的,在股灾那段时间会达到50%左右。接下来我们就结合咱们的算法,在2021年进行了一个实盘的跟踪,这个跟踪大家也可以通过连接查看它的跟踪表现。这个策略从2021年2月份进行跟踪,它最大的回撤是在年初,应该是在去年过年回来,最大回撤有9.6%左右。它在整个2021的表现比较可观,年化有60%左右,在2021年这个时间点不完全对的上,应该是到2022年1月7日,到这个时间点它的收益率是58%,我们是在9月1日的时候把这个策略公开出来的,大家可以看到这个策略整体的情况。如果我们设置选股的数量更多,这个策略的收益率也会分散,不会那么高。比如说我们买200只股票,收益率可能会降到百分之十几或者20%。我这边关于AI量化实践的介绍大概介绍到这个地方,后面有机会我们可以做更深入的分享和交流,谢谢大家。








