好了,配置的问题算是解决了,让我们再运行以下程序吧:
import
pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'image = Image.open("e:/aa.png")
text = pytesseract.image_to_string(image)
print(text)
得到:
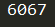
接下来我们还可以尝试含有英文或者中文的图片:
image = Image.open("e://sentence.png")
text = pytesseract.image_to_string(image,lang='chi_sim')
print(text)
下图的上部分为原图,下部分为python解析出来的结果:

值得注意的是在识别含有中文的图片时,需要在lang这个选项中指定chi_sim:
image = Image.open("e:/denggao.jpg")
txt= pytesseract.image_to_string(image,lang='chi_sim')
print(txt)

其实,我们仔细观察识别结果,个别字母没有被识别出来,或者个别汉字识别错误,但是总体上识别准确率还是挺高的。
最后我们将识别出来的结果保存到一个txt文档中,如果是中文,可以指定编码为utf-8编码:
with open("e://output.txt", "w",encoding='utf8') as f:
print(text)
f.write(str(text))












