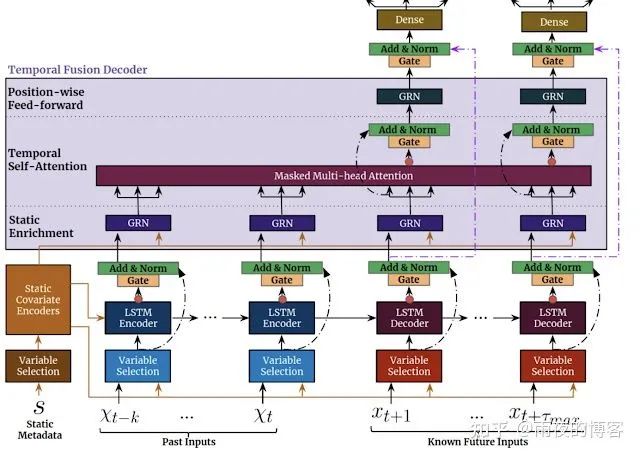
TFT 旨在有效地为每种输入类型(即静态、已知或观察到的输入)构建特征表示,以实现高预测性能。TFT的主要成分(如下所示)是:
跳过模型的任何未使用组件(从数据中学习)的门控机制,提供自适应深度和网络复杂性以适应广泛的数据集。
变量选择网络在每个时间步选择相关的输入变量。虽然传统的 DNN可能会过度拟合不相关的特征,但基于注意力的变量选择可以通过鼓励模型将大部分学习能力锚定在最显着的特征上来提高泛化能力。
静态协变量编码器集成了静态特征来控制时间动态的建模方式。静态特征可能对预测产生重要影响,例如,商店位置可能具有不同的销售时间动态(例如,乡村商店可能会看到更高的周末客流量,但市中心商店可能会在下班后看到每日高峰)。
从观察到的和已知的时变输入中学习长期和短期时间关系的时间处理。序列到序列采用层用于本地处理,因为它具有用于订购信息处理归纳偏置是有益的,而长期依赖性使用新颖的可解释的多头关注块捕获。这可以缩短信息的有效路径长度,即可以直接关注具有相关信息(例如去年的销售额)的任何过去时间步长。
预测区间显示分位数预测,以确定每个预测范围内的目标值范围,帮助用户了解输出的分布,而不仅仅是点预测。
作者将 TFT 与用于多水平预测的各种模型进行比较,包括具有迭代方法(例如DeepAR、DeepSSM、ConvTrans)和直接方法(例如 LSTM Seq2Seq、MQRNN)的各种深度学习模型,以及传统的模型如ARIMA,ETS和TRMF。TFT 在各种数据集上的表现优于所有基准测试。这适用于点预测和不确定性估计,与次优模型相比,TFT 的 P50 损失平均降低 7%,P90 损失平均降低 9%。








