机器学习模型与算法包括线性回归、对数几率回归、LASSO回归、Ridge回归、LDA、k近邻、决策树、感知机、神经网络、支持向量机、AdaBoost、GBDT、XGBoost、LightGBM、CatBoost、随机森林、聚类算法与k均值聚类、PCA、SVD、最大信息熵、朴素贝叶斯、贝叶斯网络、EM算法、HMM、CRF和MCMC等。其中决策树、神经网络、支持向量机和聚类算法都各自代表了一大类算法,比如决策树具体包括ID3、C4.5和CART,神经网络包括DNN、CNN、RNN等网络模型。本文仅对大类算法做区分,分别从单模型和集成学习模型、监督学习模型和无监督学习模型、判别式模型和生成式模型、概率模型和非概率模型等多个维度来讨论这二十余种算法。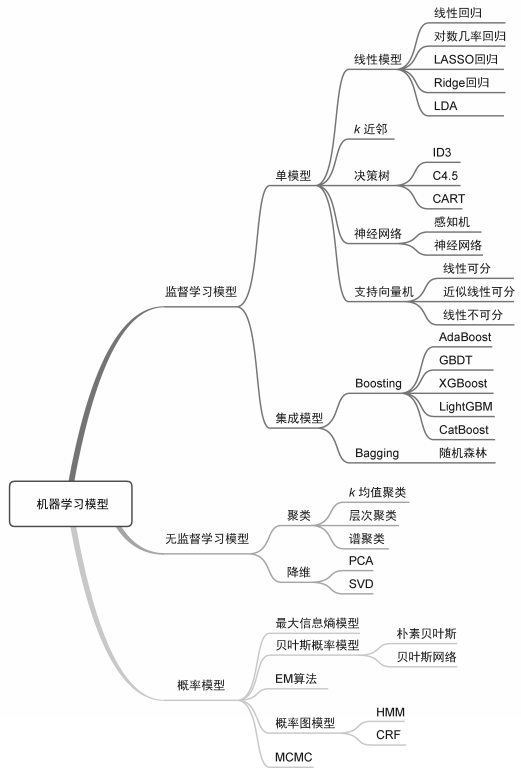
从模型的个数和性质角度来看,可以将机器学习模型划分为单模型(single model)和集成模型(ensemble model)。所谓单模型,是指机器学习模型仅包括一个模型,基于某一种模型独立进行训练和验证。本文所述监督学习模型大多可以算作单模型,包括线性回归、对数几率回归、LASSO回归、Ridge回归、LDA、k近邻、决策树、感知机、神经网络、支持向量机和朴素贝叶斯等。
与单模型相对的是集成模型。集成模型就是将多个单模型组合成一个强模型,这个强模型能取所有单模型之长,达到相对的最优性能。集成模型中的单模型既可以是同类别的,也可以是不同类别的,总体呈现一种“多而不同”的特征。常用的集成模型包括Boosting和Bagging两大类,主要包括AdaBoost、GBDT、XGBoost、LightGBM、CatBoost和随机森林等。单模型和集成模型分类如图2所示。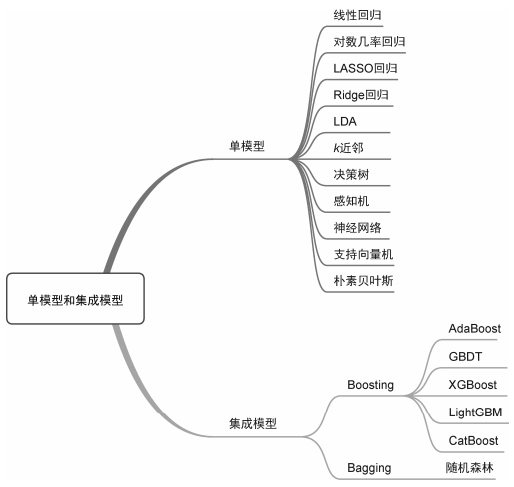
监督模型(supervised model)和无监督模型(unsupervised model)代表了机器学习模型最典型的划分方式,几乎所有模型都可以归类到这两类模型当中。监督模型是指模型在训练过程中根据数据输入和输出进行学习,监督模型包括分类(classification)、回归(regression)和标注(tagging)等模型。无监督模型是指从无标注的数据中学习得到模型,主要包括聚类(clustering)、降维(dimensionality reduction)和一些概率估计模型。
图2中所有单模型和集成模型都是监督模型,图1中的一部分概率模型也属于监督模型,包括HMM和CRF,它们属于其中的标注模型。无监督模型主要包括k均值聚类、层次聚类和谱聚类等一些聚类模型,以及PCA和SVD等降维模型。另外,MCMC也可以作为一种概率无监督模型。监督模型和无监督模型的划分如图3所示。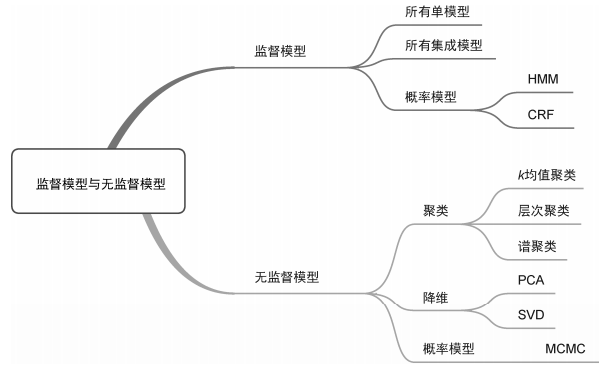
在机器学习模型中监督模型占主要部分,针对监督模型,我们可以根据模型的学习方式将其分为生成式模型(generative model)和判别式模型(discriminative model)。生成式模型的学习特点是学习数据的联合概率分布P(X,Y),然后基于联合分布求条件概率分布P(Y|X)作为预测模型,如下式所示:
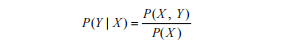
常用的生成式模型包括朴素贝叶斯、HMM以及隐含狄利克雷分布模型等。
判别式模型的学习特点是基于数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测模型,判别式模型关心的是对于给定输入X,应该预测出什么样的Y。常用的判别式模型有线性回归、对数几率回归、LASSO回归、Ridge回归、LDA、k近邻、决策树、感知机、神经网络、支持向量机、最大信息熵模型、全部集成模型以及CRF等。生成式模型与判别式模型的划分如图4所示。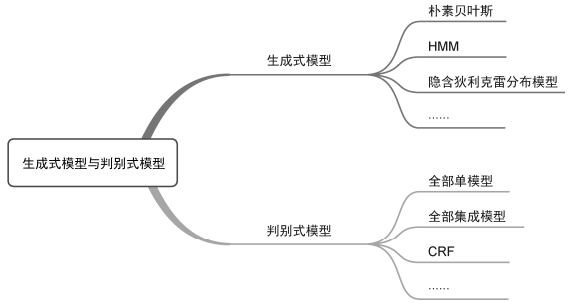
根据模型函数是否为概率模型,可以将机器学习模型分为概率模型(probabilistic model)和非概率模型(non-probabilistic model)。通过对输入X和输出Y之间的联合概率分布P(X,Y)和条件概率分布P(Y|X)进行建模的机器学习模型,都可以称为概率模型。而通过对决策函数Y=f(X)建模的机器学习模型,即为非概率模型。
常用的概率模型包括朴素贝叶斯、贝叶斯网络、HMM和MCMC等,而线性回归、k近邻、支持向量机、神经网络以及集成模型都可以算作非概率模型。需要注意的是,概率模型与非概率模型的划分并不绝对,有些机器学习模型既可以表示为概率模型,也可以表示为非概率模型。比如决策树、对数几率回归、最大信息熵模型和CRF等模型,就兼具概率模型和非概率模型两种解释。概率模型和非概率模型的划分如图5所示。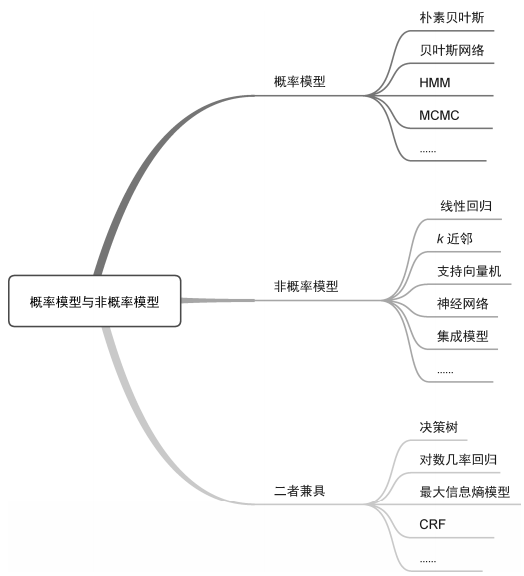

图书简介:作为一门应用型学科,机器学习植根于数学理论,落地于代码实现。这就意味着,掌握公式推导和代码编写,方能更加深入地理解机器学习算法的内在逻辑和运行机制。本书在对全部机器学习算法进行分类梳理的基础之上,分别对监督学习单模型、监督学习集成模型、无监督学习模型、概率模型四个大类共26个经典算法进行了细致的公式推导和代码实现,旨在帮助机器学习学习者和研究者完整地掌握算法细节、实现方法以及内在逻辑。









