↑↑↑关注后"星标"Kaggle竞赛宝典
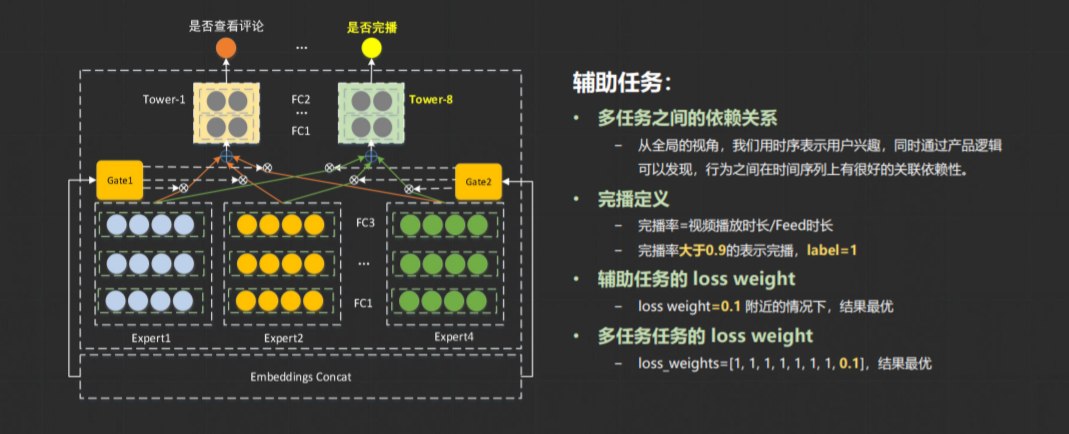
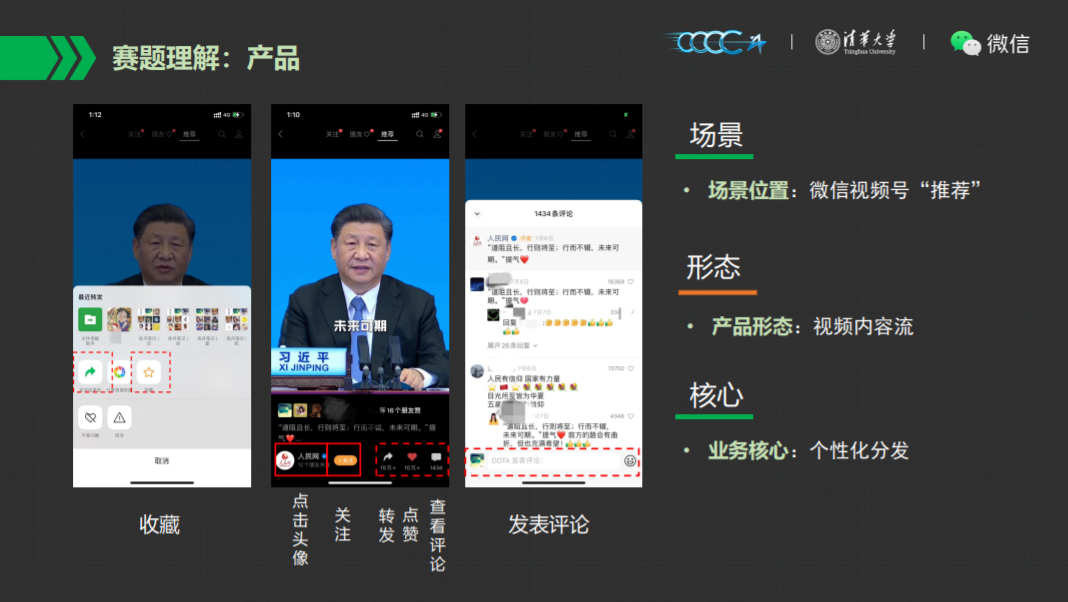
在多目标多任务训练的网络中,如果最终的loss为有时为多个loss的加权和,例如 loss = a*loss_x+b*loss_y+c*loss_y+... ,这个问题在微信视频号推荐比赛里也存在。任务需要对视频号的某个视频的收藏、点击头像、转发、点赞、评论、查看评论等进行多任务建模,也就产生了多个loss。
这里介绍在这次实践过程中测试过的几个方法。
GradNorm:ω(t+1)=ω(t)+λβ(t),该方法主要在对各损失函数权重的梯度进行处理,利用梯度更新公式动态更新权重ω。

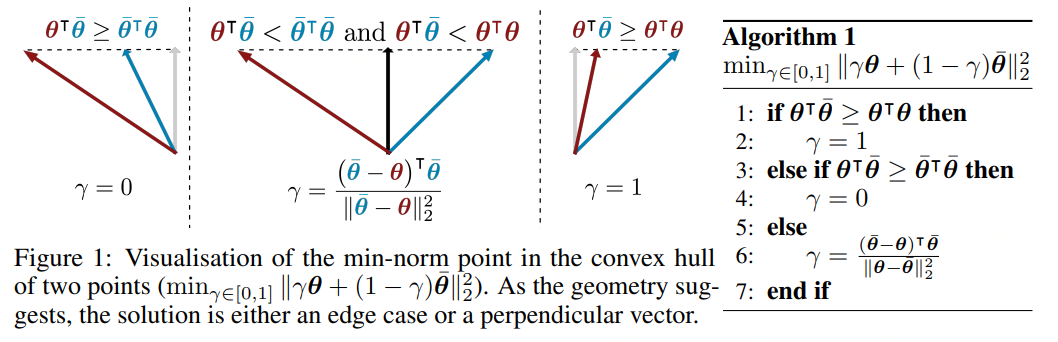
2.Multi-Task Learning as Multi-Objective Optimization 在处理多个loss时,引入Pareto用一次训练的方式将问题转化为求取Pareto最优解。有兴趣的可以看看原文:https://arxiv.org/pdf/1810.04650.pdf

最简单的多任务Loss的线性加权:
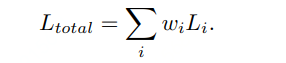
对于分类任务,经常通过softmax函数产生概率向量中抽取样本来构造多任务的最大似然函数。
class MultiLossLayer(nn.Module):
"""
计算自适应损失权重
implementation of "Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics"
"""
def __init__(self, num_loss):
super(MultiLossLayer, self).__init__()
self.sigmas_dota = nn.Parameter(nn.init.uniform_(torch.empty(num_loss), a=
0.2, b=1.0), requires_grad=True)
def get_loss(self, loss_set):
factor = torch.div(1.0, torch.mul(2.0, self.sigmas_dota))
loss_part = torch.sum(torch.mul(factor, loss_set))
regular_part = torch.sum(torch.log(self.sigmas_dota))
loss = loss_part + regular_part
return loss
上面说了太多方法调参,来点手动的经验吧。最简单的方法如下:
例如 loss = a*loss_x+b*loss_y+c*loss_y ,可以在a+b+c=1前提下,固定a,b,调整c,分别在2x、4x、6x等倍数去做尝试,最后相加为1;
权重缩放,固定其中一个为1,利用power(m,n)去调整尝试;
Weight Uncertainty 利用 Gaussian approximation 方式直接修改loss ,并同时以梯度传播的方式来更新里面的两个参数。