无需担心复杂的实现细节,只需简单调用 API,就可以为文本和图像创建 SOTA 表征向量。2018 年 9 月,Google 一篇 BERT 模型相关论文引爆全网:该自然语言模型,在机器阅读理解顶级水平测试 SQuAD1.1 中,连破 11 项 NLP 测试记录,两个衡量指标全面超越人类。BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/pdf/1810.04805.pdf这不仅开启了 NLP 的全新时代,也标志着迁移学习和预训练+微调的模式,开始进入人们的视野。2018 年 10 月,BERT 发布仅一个月后,BERT-as-service 横空出世。用户可以使用一行代码,通过 C/S 架构的方式,连接到服务端,快速获得句向量。访问 BERT-as-service:
https://github.com/jina-ai/bert-as-service
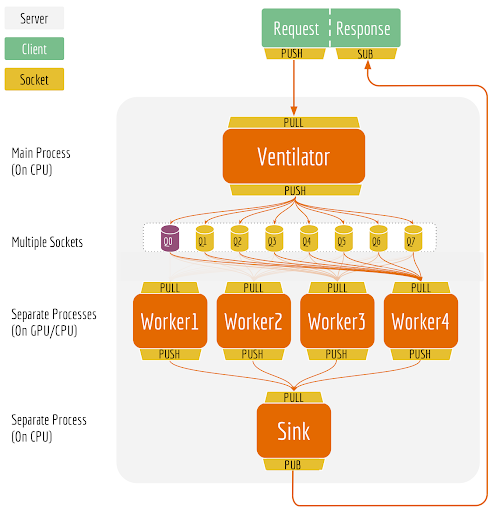
BERT-as-service 2018 年发布时的架构作为基于 BERT 的第一个微服务框架,BERT-as-service 通过对 BERT 的高度封装和深度优化,以方便易用的网络微服务 API 接口,赢得了 NLP 及机器学习技术社区的广泛关注。它简洁的 API 交互方式、文档写作风格,甚至连 README 排版,都成为之后众多开源项目的模板。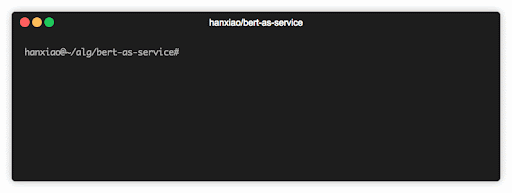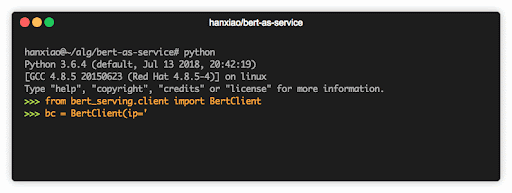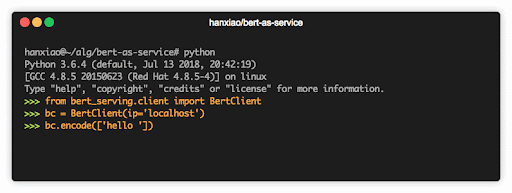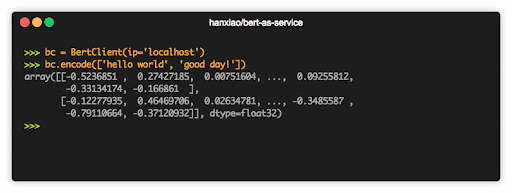
BERT-as-service 可以通过几行代码轻松获得句向量如果说 BERT 是迁移学习的里程碑,那么 BERT-as-service 的出现,可以称得上是迁移学习,在工程服务化的里程碑。GitHub 上 BERT 模型的不少贡献者,也积极参与了 BERT-as-service 的代码贡献。火遍全球的 Hugging Face 在 2018 年 11 月推出的 Pytorch-transformers 初版,也受到了 BERT-as-service 的启发。
尽管 BERT-as-service 在 2019 年 2 月后的更新逐渐暂停,但 3 年来该项目在 GitHub 上积累了 10,000 个 Star, 2,000 多个 Fork 和堆积成山的 Issue,都显示出社区对 BERT-as-service 的极大兴趣和热情。其中很多开发人员 Fork 了 BERT-as-service 并结合自身业务,开发出了一套自己的微服务系统。时隔三年,BERT-as-service 再度更新,升级为全新的 CLIP-as-service,不仅保留了原有的高并发、微服务、简单易用等特性,更可以同时生成文本和图像的表征向量。访问 CLIP-as-service GitHub:
https://github.com/jina-ai/clip-as-service
CLIP-as-service 的背后是由 OpenAI 在 2021 年 1 月发布的 CLIP (Contrastive Language-Image Pre-training) 模型,它可以基于文本对图像进行分类,打破了自然语言处理和计算机视觉两大门派「泾渭分明」的界限,实现了多模态 AI 系统。* 开箱即用:无需额外学习,只需调用客户端或服务端的 API,即可实时生成图像和文本的向量输出。* 速度快:为大型数据集和长耗时任务量身定制,同时支持 ONNX 和 PyTorch 模型引擎,以提供快速推理服务。* 高扩展:支持多核、单核 GPU 上并行扩展多个 CLIP 模型,并自动进行负载均衡。服务器端可以选择通过 gRPC、Websocket 或 HTTP 三种方式对外提供服务。* 神经搜索全家桶:开发者可以短时间内,快速融合 CLIP-as-service 及 Jina、DocArray,搭建跨模态和多模态搜索行业解决方案。同 BERT-as-service 的 C/S 架构一样,CLIP-as-service 也分为服务器端和客户端两个安装包。开发者可通过 pip 在不同的机器上选择性地安装 CLIP 客户端或服务端。1、安装 CLIP 服务端(通常是 GPU 服务器)
2、安装 CLIP 客户端(比如在本地笔记本电脑上)启动服务器意味着下载预训练模型,启动微服务框架,对外开放接口等一系列操作。所有这些操作都可以通过一句简单的命令完成。 🔗 Protocol GRPC 🏠 Local access 0.0.0.0:51000 🔒 Private network 192.168.3.62:51000 🌐 Public address 87.191.159.105:51000
这表示服务器已准备就绪,并以 gRPC 方式对外提供接口。服务端就绪后,即可通过 GRPC 客户端与之连接并发送请求。根据客户端和服务端的位置,可使用不同的 IP 地址。更多详情,请查看 CLIP-as-service 文档:
https://clip-as-service.jina.ai/
运行 Python 脚本,验证客户端和服务端之间的连接状况:from clip_client import Clientc = Client('grpc://0.0.0.0:51000')c.profile()
Roundtrip 16ms 100% ├── Client-server network 12ms 75% └── Server 4ms 25% ├── Gateway-CLIP network 0ms 0% └── CLIP model 4ms 100%
在这个示例中,我们将使用 CLIP-as-service 搭建立一个简单的 text-to-image 搜索案例,用户只需输入文本,即可输出相匹配的图像。本示例将借助 Totally-Looks-Like 数据集及 Jina AI 的 DocArray 来实现数据下载。注意:DocArray 作为上游依赖,已包含在 clip-client 中,无需单独安装。from docarray import DocumentArrayda = DocumentArray.pull('ttl-original', show_progress=True, local_cache=True)
Totally-Looks-Like 数据集包含 12,032 张图像,可能需要一段时间下载。2、加载完成后,使用 DocArray 内置功能 da.plot_image_sprites() 将其可视化,效果如下图所示:3、通过命令 python -m clip_server 启动 CLIP 服务端,并对图像进行编码 (encode)
from clip_client import Clientc = Client(server='grpc://87.105.159.191:51000')da = c.encode(da, show_progress=True)
4、输入 "a happy potato",查看搜索结果vec = c.encode(["a happy potato"])r = da.find(query=vec, limit=9)r.plot_image_sprites()
查询 "A happy potato" 后的输出结果尝试输入 "professor cat is very serious",输出结果如下:更多详细文档,请访问:
https://clip-as-service.jina.ai/
在下面这个例子中,我们使用《傲慢与偏见》整部小说的英文文本作为匹配目标。然后输入一张图片,就可以得到这张图片在《傲慢与偏见》中对应的文本。开始之前,先运行本地托管且支持客户端访问的 CLIP-as-service 服务端。https://github.com/alexcg1/neural-search-notebooks/blob/main/clip-as-service/server.ipynb
服务端启动并运行后,即可使用客户端向其发送请求并获得结果。使用 CLIP-as-service 客户端,建立多模态搜索实例,请访问 notebook 👉https://github.com/alexcg1/neural-search-notebooks/blob/main/clip-as-service/client.ipynbhttps://clip-as-service.jina.ai/CLIP-as-service GitHub Repohttps://github.com/jina-ai/clip-as-service/https://docarray.jina.ai/










