
作者:Tirthajyoti Sarkar
翻译:张逸
校对:冯羽
本文约3090字,建议阅读6分钟。
本文从非线性数据进行建模,带你用简便并且稳健的方法来快速实现使用Python进行机器学习。
使用Python库、流水线功能以及正则化方法对非线性数据进行建模。
在数据科学和分析领域中,对非线性数据进行建模是一项常规任务。但找到一个结果随自变量线性变化的自然过程很不容易。因此,需要有一种简便并且稳健的方法来快速将测量数据集与一组变量进行拟合。我们假定测量数据可能包含了一种复杂的非线性函数关系。这应该是数据科学家或机器学习工程师常用的工具。
我们要考虑以下几个相关的问题:
如何确定拟合多项式的顺序?
“我们能不能画出数据图形直接得到结论?”
数据如果能清楚的可视化表示(即特征维度为1或2)时,方法可行。一旦数据的特征维度等于3或者更多,这事儿就麻烦了。而且如果对结果产生影响的特征存在交叉耦合,这么做就完全是在浪费时间。下面我们画个图来感受一下:
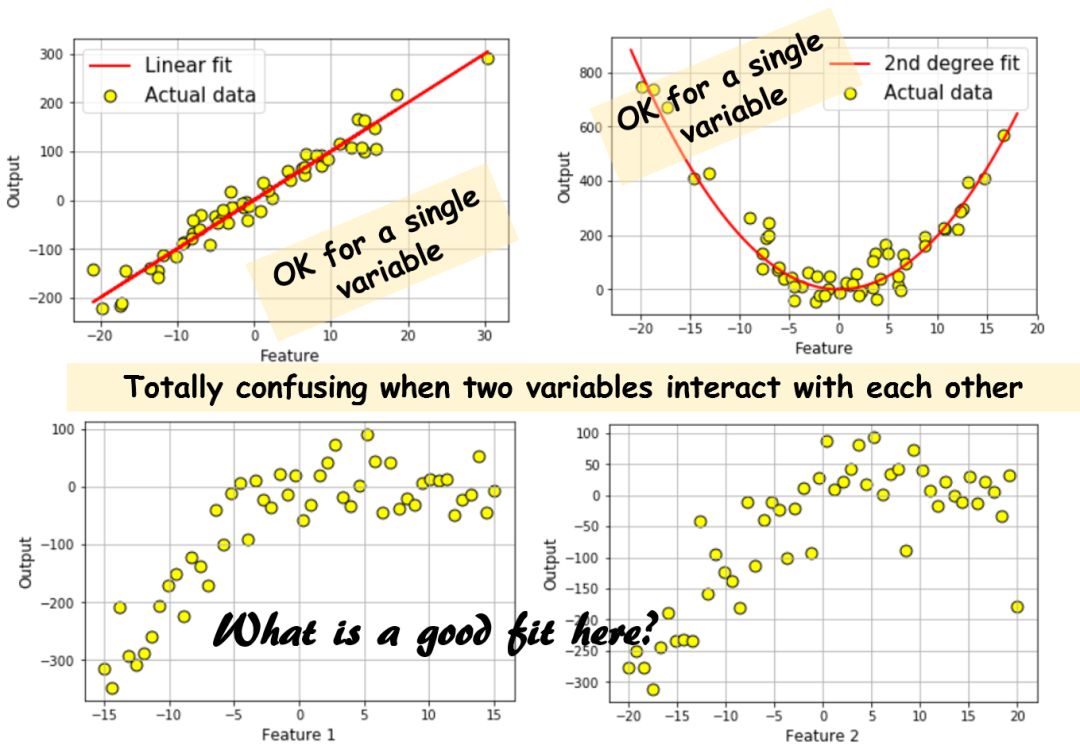
很明显,直接画图的方法最多也只能做到上面这种程度。对那些更高维度并且变量相互作用的数据集,如果你试图每次只查看单个输入变量和输出之间的关系,会得出完全错误的结论。而且目前没有什么好办法同时显示两个以上的变量。所以,我们必须采用某种机器学习的技术来拟合多维数据集。
实际上,已经有了不少好的解决方案。
在你看到“...但这些是高维非线性数据集...”这句话发出尖叫之前,线性回归应该是头一个能找到的工具。注意一点:线性回归模型中的“线性”二字指的是系数,而不是特征。特征(即自变量)可以是任意多维度的,甚至可以是指数、对数、正弦这些函数。更厉害的是,可以使用这些变换和线性模型(近似)对令人惊讶的大量自然现象进行建模。
来看看下边这个有三个特征、单输出的数据集。我们再一次使用了前边提到的画图方法,很明显它表现的差强人意。
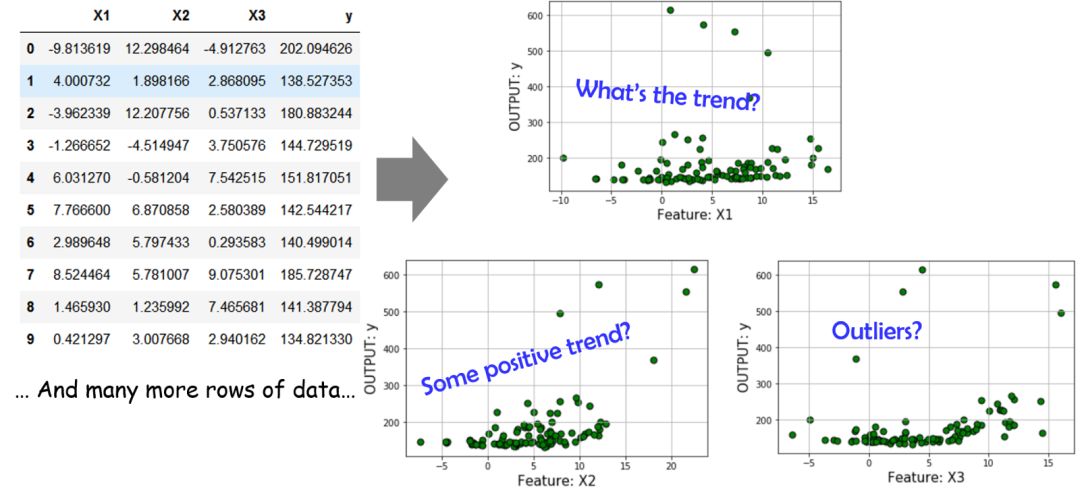
因此,我们决定学习一个具有高阶多项式项线性模型来拟合数据集。那么问题来了:
怎样确定什么多项式是有用的?
如果我们开始将一次项、二次项、三次项...逐个进行组合,什么时候停止比较合适呢?
我们怎么判定哪些交叉耦合的项是重要的?比如:是只需要_X_1²、_X_2³还是需要有_X_1._X_2以及_X_1².X3这种项?
最后,我们是不是必须手动将这些多项式转换的方程/函数式写出来并且应用到数据集上?
强大的Python机器学习库来帮忙
幸运的是,有一个很厉害的机器学习库--scikit-learn提供了很多成熟的类/对象来解决上边说的这些问题。
这儿有一个对使用scikit-learn进行线性回归进行概述的资料(原文中说是视频,但打开链接看了一下是这个库的使用文档,故直接翻译为了资料)
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression
还有一篇很好的文章供大家查看。
https://towardsdatascience.com/simple-and-multiple-linear-regression-in-python-c928425168f9?gi=69160943145f
但本文要介绍的不仅仅是一个简单的线性拟合,请大家接着往下看。(原文有一句提到代码在作者的GitHub,但是发现链接已经404,所以没加)
我们从引入scikit-learn中相关的包开始:
from sklearn.cross_validation#引入函数进行训练集和测试集的划分
import train_test_split
#引入函数自动生成多项式特征
from sklearn.preprocessing import PolynomialFeatures
# 引入线性回归和一个正则化的回归函数
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LassoCV
from sklearn.pipeline import make_pipeline
下面快速说明一下我们等会儿要用到的一些概念。
训练/测试集划分:表示将已有的单独数据集划分为两个子集。其中一个(训练集)用来建立模型,另外一个(测试集)用来评估模型的准确性和稳定性。这个步骤对任何一个机器学习任务来说都是必不可少的。经过处理,我们没有用所有的数据建立出一个看似异常准确的模型。(因为模型接触到所有的数据,当然会拟合的很好)这个模型通常在新数据(未知)数据上表现很差。
模型在测试集上的准确性比其在训练集上的准确性更有说服力。这儿有一篇关于这个话题延伸的文章,有兴趣的读者可以看看。
https://towardsdatascience.com/train-test-split-and-cross-validation-in-python-80b61beca4b6
下面你会看到Google car的先驱Sebastion Thrun对这个概念的说法。
多项式特征自动生成
Scikit-learn提供了一个从一组线性特征中生成多项式特征的方法。你需要做的就是传入线性特征列表,并指定希望生成的多项式项的最大阶数。它还可以让你选择是生成所有交叉耦合项还是只生成主要特征的阶数。这里有一个Python代码进行演示。
http://scikit-learn.org/stable/auto_examples/linear_model/plot_polynomial_interpolation.html#sphx-glr-auto-examples-linear-model-plot-polynomial-interpolation-py
正则化回归
正则化的重要性不言而喻,它是机器学习的一个中心概念。在建立线性模型时,最基本的想法是对模型的系数进行“惩罚”,使它们不会变得太大而过拟合数据(对噪声数据过于敏感)。有两个广泛使用的正则化方法,其中我们要用的被称为LASSO。下边这篇文章对两种正则化方法做了很好的概述。
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
机器学习流水线
一个机器学习项目几乎不会是单一的建模任务。它最常见的形式包括数据生成、数据清洗、数据转换、模型拟合、交叉验证、模型准确性评估和最终的部署。
列举一些相关的学习资料如下:
https://www.quora.com/What-is-a-pipeline-and-baseline-in-machine-learning-algorithms
https://medium.com/@yanhann10/a-brief-view-of-machine-learning-pipeline-in-python-5f50b941fca8
https://www.oreilly.com/ideas/building-and-deploying-large-scale-machine-learning-pipelines
http://scikit-learn.org/stable/tutorial
/statistical_inference/putting_together.html
怎样最终整合并建立一个稳健的模型?
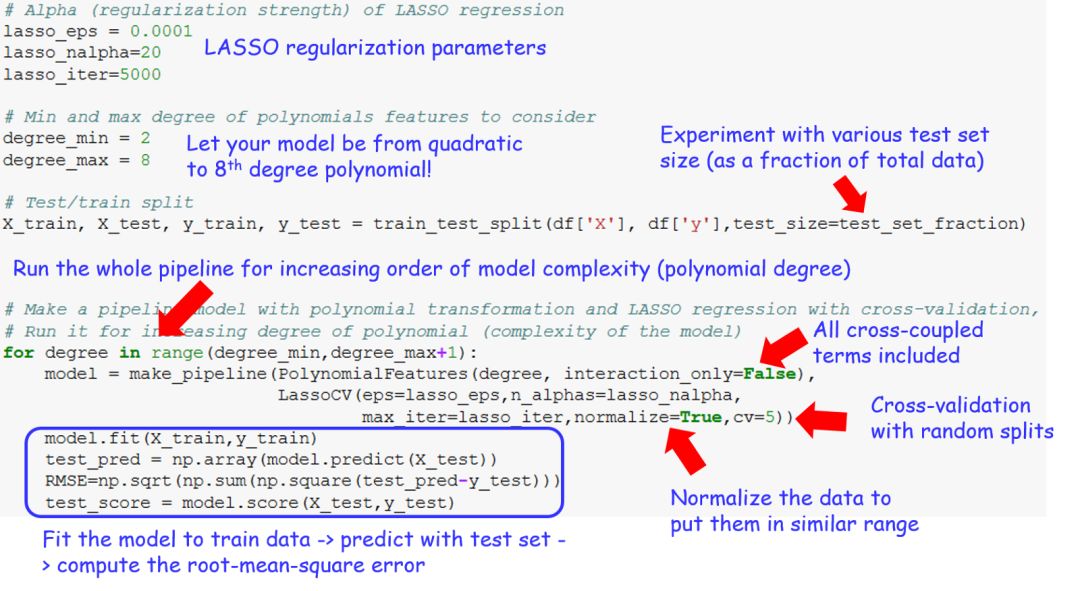
在这里,我们提供了一些代码样例,你可以对它进行修改,应用在你自己的数据集上。
# LASSO回归的参数设置
lasso_eps = 0.0001
lasso_nalpha=20
lasso_iter=5000
# 多项式特征项的最大、最小阶数
degree_min = 2
degree_max = 8
# 训练集、测试集划分
X_train, X_test, y_train, y_test =
train_test_split(df['X'], df['y'],test_size=test_set_fraction)
# 建立一个流水线模型
for degree in range(degree_min,degree_max+1):
model=make_pipeline(PolynomialFeatures(degree, interaction_only=False),LassoCV(eps=lasso_eps,
n_alphas=lasso_nalpha,max_iter=lasso_iter,
normalize=True,cv=5))
model.fit(X_train,y_train)
test_pred = np.array(model.predict(X_test))
RMSE=np.sqrt(np.sum(np.square(test_pred-y_test)))
test_score = model.score(X_test,y_test)
不过这些冷冰冰的代码是给机器看的,我们还准备了有详细注释的版本。
为了进一步提炼它,下面是更精简的流程图:
为了进一步提炼它,下面是更精简的流程图:
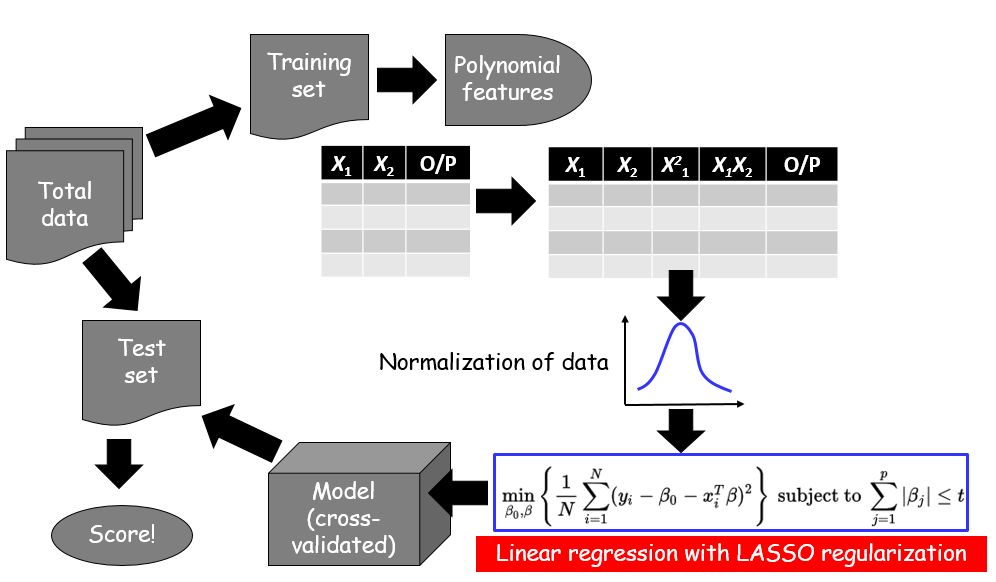
让我们来讨论讨论结果
对于所有的模型,我们给出了测试误差、训练误差(均方根)还有R²系数作为模型准确性的度量。然后把它们画出来:
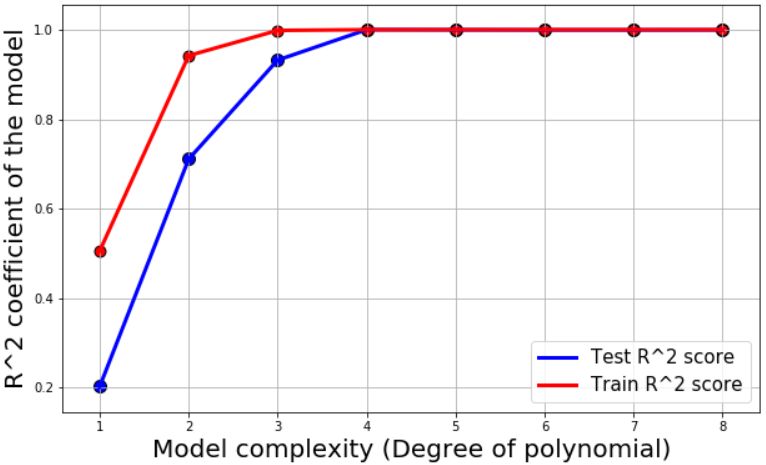
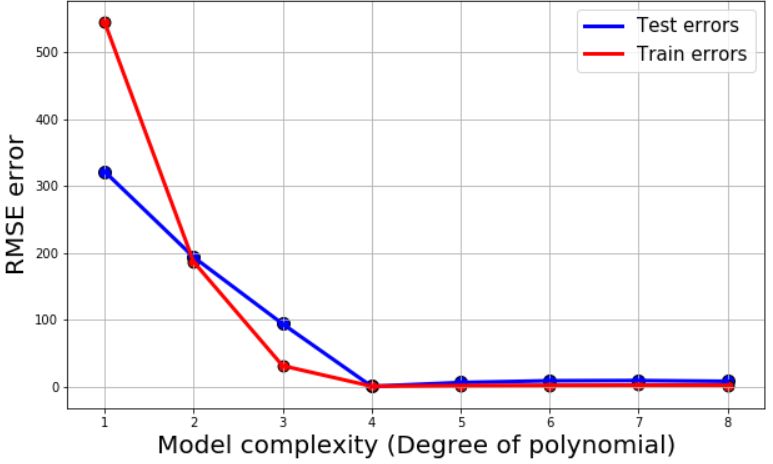
这些图回答了最早提出的两个问题。
可以看出,我们需要四阶和五阶的多项式项来进行拟合。线性、二次甚至三次模型对这个数据来说都不够复杂。
同时,我们也没必要使阶数超过5,这会使得模型过于复杂。

等等!问题来了:在这条曲线中,我们熟悉的表现出偏差和方差之间权衡(即过拟合与欠拟合)的形状在哪?为什么测试误差没有随着模型复杂度的增加急剧升高?
答案在于,使用LASSO回归之后,我们基本消除了复杂模型中的高阶项。对于更细节的东西,比如这个结果到底是怎么出现的,可以参考这篇文章。
https://dataorigami.net/blogs/napkin-folding/79033923-least-squares-regression-with-l1-penalty
实际上,这正是LASSO回归和L1正则的关键优势之一,它不是仅仅将模型中的部分系数减小,而是将它们直接变为零。这相当于提供了“自动特征选择”的功能。即便你一开始使用了很复杂的模型来拟合数据,经过这种处理后,也可以让那些不重要的特征自动被忽略。
为了进行对比,我们这次不做正则化处理,并且使用一个简单的线性模型来拟合数据。下边是得出的结果。这次可以看到那条熟悉的偏差/方差权衡曲线了(补充:表示训练误差及测试误差随着模型复杂度增长的变化,体现过拟合及欠拟合)
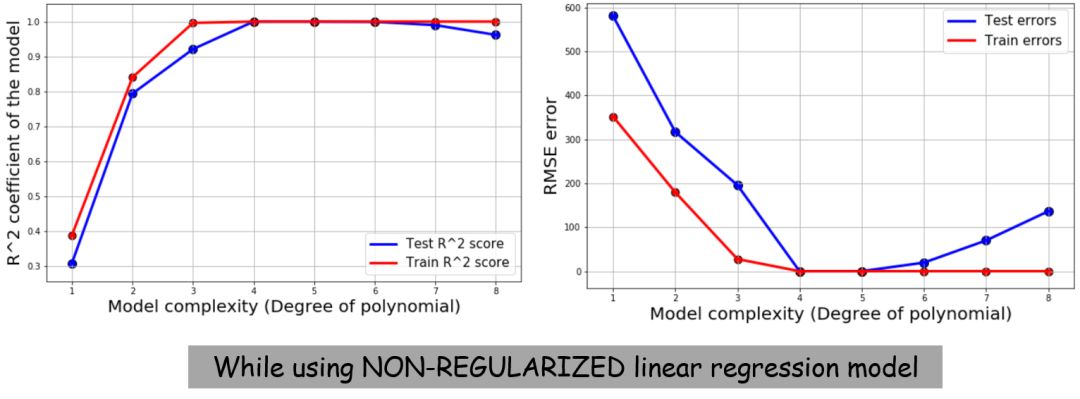
噪声数据会发生什么?
(这里作者有提到自己的代码,同样因为GitHub地址失效没有加进来)
数据中的噪声会让模型很难变得准确,甚至还会产生过拟合。因为模型会试图解释噪声,而不是发掘真正的模式。基本上,简单的线性回归模型在这种情况下都会失败,而正则化模型仍然表现良好。不过即便这样,在模型足够复杂时,过拟合现象也会现出端倪。
下面是总结:
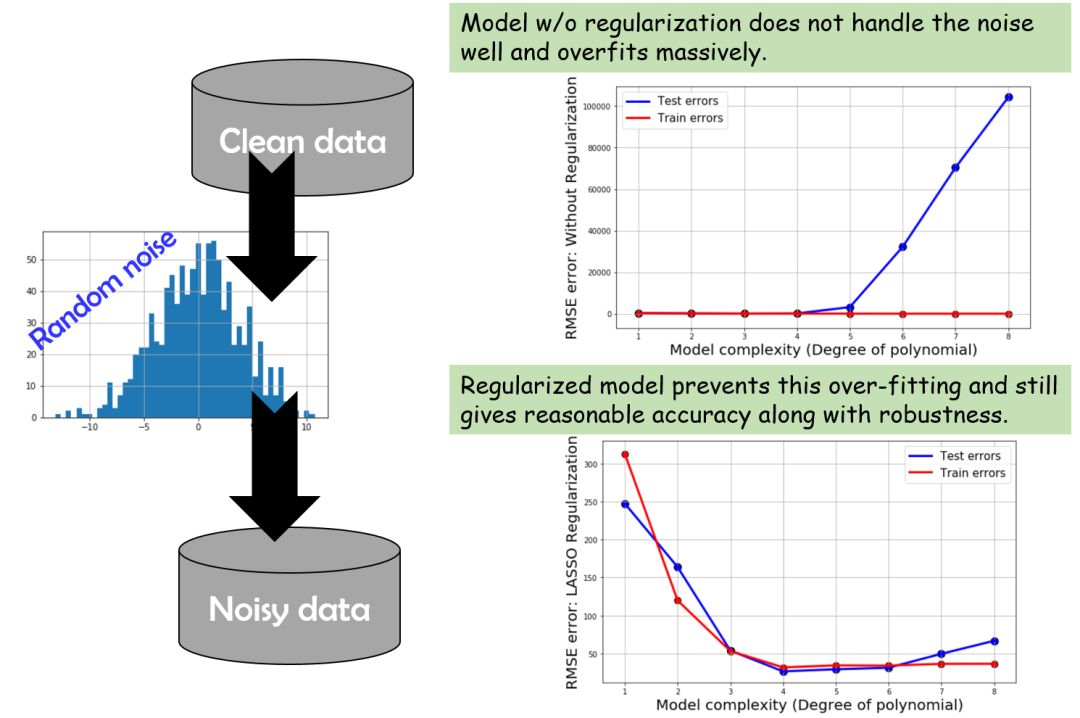
结语
简而言之,本文讨论了一个拟合多变量回归模型的方法,它适用于高度非线性、具有耦合项并且含有噪声的数据集。我们知道了如何利用Python的机器学习库来生成多项式特征、对数据进行正则化处理,防止模型中的系数变得过大、画图来评估模型的准确性及稳定性等。
对于更高级的具有非多项式特征的模型,你可以看看sklearn中关于核回归或支持向量机的内容。还有这篇文章有对高斯核回归的介绍。
http://mccormickml.com/2014/02/26/kernel-regression/
如果你有任何问题或者看法要分享,
可以点这里给作者发邮件。(mailto:tirthajyoti@gmail.com)
原文链接:
https://www.codementor.io/tirthajyotisarkar/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-hfgyw7i4f#how-to-decide-the-order-of-polynomial-and-related-dilemma
张逸,中国传媒大学大三在读,主修数字媒体技术。对数据科学充满好奇,感慨于它创造出来的新世界。目前正在摸索和学习中,希望自己勇敢又热烈,学最有意思的知识,交最志同道合的朋友。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。










