爬虫俱乐部之前推出的线下培训,得到了各位老师的一致好评。为了更加方便大家学习,满足更多Stata用户的学习需求,爬虫俱乐部已隆重推出在线直播课程,请大家奔走相告!课程报名链接:https://ke.qq.com/course/286526#tuin=9735fd2d,详情见推文《爬虫俱乐部隆重推出网上直播课程第一季》
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~
好消息:爬虫俱乐部即将推出研究助理供需平台,如果您需要招聘研究助理(Research Assistant or Research Associate),可以将您的需求通过我们的公众号发布;如果您想成为一个RA,可以将您的简历发给我们,进入我们的研究助理数据库。帮我们写优质的推文可以提升您被知名教授雇用的胜算呀!
文字是情感的含蓄表达,很多时候,语言无法表达的含义却可以在文字中巧妙传送~咳咳,收起泛滥的情感~今天为大家带来的是一个简单的词频统计的案例。为了使刚入门的童鞋更容易理解和上手,我们使用天然有空格分词的英文文本来做演示。
题目:在一个目录下存放了来自爬虫俱乐部二年级的阿宝同学2x18年1月的25篇寒假日记(txt格式),为了避免分词的问题,假设内容都是英文,请统计出每篇日记出现频率最高的词。
由于我们使用的是天然有空格分词的英文文本,因此不用过多考虑分词的问题。按照最简单的解题逻辑,只要统计单词出现的次数即可。但在这里要注意的是,英文文本有句首字母大写,句首大写的单词和句中小写的单词可能是同一个单词,因此我们需要使用str.lower()方法把所有字母小写化,即可解决这一问题。此外,我们还需要使用.replace()方法用空格替换文档中的逗号、句号、感叹号等,并使用str.strip()方法移除字符串首尾的空格或换行符。
首先,我们构建一个简单的词频统计的函数wordcount(),程序如下:首先,对字符串进行前期处理,在移除字符串首尾的空格或换行符,所有字母小写化后,按空格对英文文本进行分词;第二步,新建一个空的字典new_dict,如果字典中本身含有文本中的单词,则在原有的计数上+1,否则该单词被加入到字典中且计数为1;第三步,使用sorted()函数对字典中的元素进行排序操作,其中,可迭代对象为字典new_dict中的所有元素,用来比较的元素是字典中每个键的值,即单词的词频,按降序排序;最后,返回排序后的第1个键值。
def wordcount(strs):
strlist = strs.strip().lower().split(' ')
new_dict = {}
for strs in strlist:
if strs in new_dict.keys():
new_dict[strs] = new_dict[strs]+1
else:
new_dict[strs] = 1
count_list=sorted(new_dict.items(),key=lambda x:x[1],reverse=True)
return count_list[:1]
构建好词频统计的函数之后,我们对指定目录下的所有文档分别进行词频统计,程序如下:首先调用os模块,os 模块可用来便捷地处理文件和目录。os.listdir(path)方法可以返回一个path指定的文件夹包含的所有文件或文件夹名称的列表;第二步,使用for循环对path路径下的所有文档分别使用之前构造好的wordcount()函数进行词频统计;第三步,在屏幕上输出文档名称及词频统计结果。
import os
path = "E:/财大/爬虫俱乐部/推文/python-词频统计/日记"
files= os.listdir(path)
for file in files:
with open(path+"/"+file,'r') as f:
l=f.read()
wc=wordcount(l)
print(file,wc)程序运行的结果如下图:

似乎这一方法完成了基本的词频统计。但仔细观察,该方法统计出的最高词频很多都是没有意义的人称代词,助动词、介词以及空字符串,这并不是我们希望看到的结果。因此,我们需要进一步完善我们的词频统计。
在这一部分,笔者尝试根据本道题目的需求构建了一个简单的停用词表。停用词表的引入本质上还是建立一个词典,这个词典包括所有的停用词,这里,我们使用.fromkeys()方法创建一个新词典,字典的每个键都是自建停用词表的每一行的单词。我们来看看引入停用词表后,我们的输出结果会有怎样的变化,程序如下~:
首先,我们还是先构建一个词频统计函数wordcount(),其构建方法和第1部分的基本一致,只是在词典new_dict的构建中排除了停用词,这里不再赘述:第二步,接下来,我们通过构建停用词字典stopwords来引入停用词表:
import os
stopwords = {}.fromkeys(line.strip() for line in open('E:/财大/爬虫俱乐部/推文/python-词频统计/英文停用词表.txt'))
构建好词频统计的函数之后,我们对指定目录下的所有文档分别进行词频统计,程序与第1部分一致。程序运行后的结果如下图:

Ps.这一部分要前排感谢爬虫俱乐部前端Snowman的友情技术指导~
虽然停用词表可以排除介词等内容,但并未体现每个单词的重要程度。基于TF-IDF思想,如果某个词在一篇文章中出现的频率(TF)高,但在一个文件集中出现的频率(IDF)较低,则这个词的重要程度较高。我们按照这一思想对我们的词频统计进行改进。
首先,构建词频统计函数wordcount_snow(str),其思路与第1-2节基本一致:
def wordcount_snow(strs):
strlist=strs.replace(
',',' ').replace('.',' ').replace('?',' ').replace('!',' ').replace('\n','').strip().lower().split(' ')
new_dict = {}
for strs in strlist:
if str in new_dict.keys() :
new_dict[strs] = new_dict[strs]+1
else:
new_dict[strs] = 1
count_list=sorted(new_dict.items(),key=lambda x:x[1],reverse=True)
return count_list
接下来,构造函数readfile(),将每篇日记的词频统计结果放到一个列表countList中:
def readfile():
path = "E:/财大/爬虫俱乐部/推文/python-词频统计/日记"
files= os.listdir(path)
countList = []
for file in files:
with open(path+"/"+file,'r') as f:
l=f.read()
countList.append(wordcount_snow(l))
return countList
为了统计每个单词在所有日记中出现的频数,我们构建了函数searchindex()作为计数器,并构造函数cal_real_power(),将每个单词及其出现的总频数记入字典frequent_dict中:
def searchindex(keyword,countList):
count = 0
for unitList in countList:
for unit_element in unitList:
if keyword in unit_element:
count += 1
return count
def cal_real_power(countList):
frequent_dict = {}
for unitlist in countList:
for unit_element in unitlist:
frequent_dict[unit_element[0]] = searchindex(unit_element[0],countList)
return frequent_dict
到这里,我们已经把所有需要的函数都定义好了。接下来,就是执(jian)行(zheng)程(qi)序(ji)的时刻!首先运行readfile()函数得到包含每篇日记词频的列表countList,再运行cal_real_power()函数得到所有日记的总词频字典frequent_dict,其中,我们排除了数字的词频统计。对countList进行for循环,来遍历每篇日记的词频列表,接下来再对每篇日记的词频列表进行for循环,计算每个单词在该篇日记中出现的频数(docu_fre)和在所有日记中出现的频数(all_fre),真实权重real_power则为docu_fre和all_fre之比,我们可以根据需要对all_fre设置不同的权重,这里我们设的权重为5
countList = readfile()
frequent_dict = cal_real_power(countList)
for unitList in countList:
maxpower_keyword = ""
max_score = 0.0
for unit in unitList:
if unit[0].isdigit():
continue
else:
docu_fre = unit[1]
all_fre = frequent_dict[unit[0
]]
real_power = docu_fre / (5 * all_fre)
if real_power > max_score:
maxpower_keyword = unit[0]
max_score = real_power
print("max_keyword %s 's real_power is %s"%(maxpower_keyword,max_score))
在最后输出的部分,我们使用了字符串格式化的%方式,%后是我们要格式化传入的类型,s代表获取传入对象的__str__方法的返回值,并将其格式化到指定位置;()括号内为指定的key值。
程序运行结果如下。我们可以认为,每篇文章的最高频词汇的真实权重越高,则该单词的重要程度就越大。
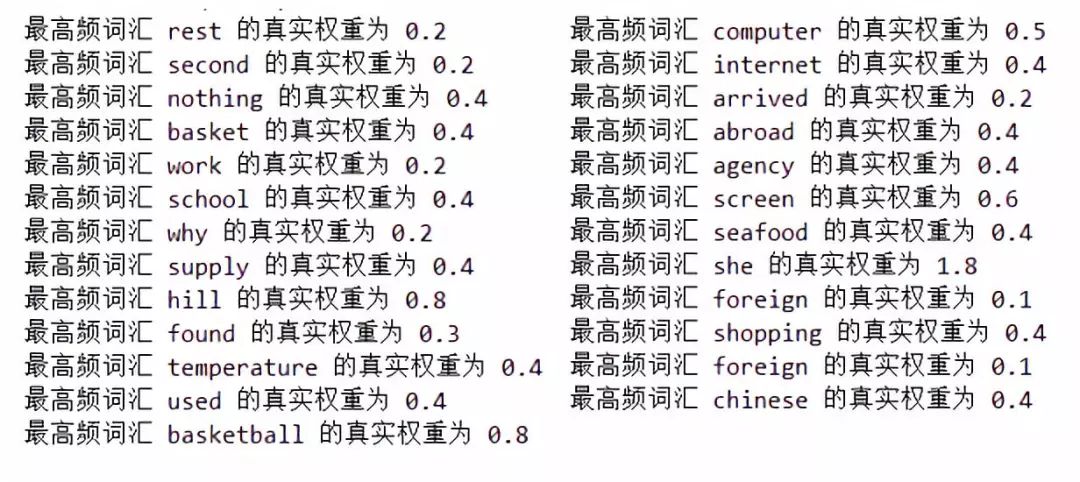
好啦,今天的介绍就到这里啦。其实笔者和大家一样,也是一个从0学起的Python小白,在学习的道路上,希望能与大家共同前行进步,么么哒~
Ps.日记内容来自网络,并由笔者进行了简单的整理。如果大家需要本文所用的完整程序,可以在本文下方留言哦~
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~

往期推文推荐:
1.爬虫俱乐部新版块--和我们一起学习Python
2.hello,MySQL--Stata连接MySQL数据库
3.hello,MySQL--odbcload读取MySQL数据
4.再爬俱乐部网站,推文目录大放送!
5.用Stata生成二维码—我的心思你来扫
6.Hello,MySQL-odbc exec查询与更新
7.Python第一天
8.Python第二天
9.事件研究大放送
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。








