开发的过程有个任务,利用DataX从MySQL同步数据到Doris,此篇从技术验证与简单使用层面展开学习。主要以下几个方面进行学习。
编译 doriswriter
doriswriter 插件
https://github.com/apache/incubator-doris/tree/master/extension/DataX
步骤(按需修改源代码)
- 从github上拉取源码(或者直接在上面地址下载包)
git clone https://github.com/apache/incubator-doris.git
不过执行 init 即可
2. 运行 init-env.sh
主要做了下面几件事,减少了繁杂的操作。
(1)将 DataX 代码库 clone 到本地。
(2)将 doriswriter/ 目录软链到 DataX/doriswriter 目录。
(3)在 DataX/pom.xml 文件中添加doriswriter模块。
(4)将 DataX/core/pom.xml 文件中的 httpclient 版本从 4.5 改为 4.5.13(因为有bug)
(1)命令
mvn clean install -pl plugin-rdbms-util,doriswriter -DskipTests
(2)编译完地址
../target/datax/datax/
../datax/plugin/
具体可看Doris官网
http://doris.incubator.apache.org/zh-CN/extending-doris/datax.html
MySQL同步数据到Doris
创建Doris表
CREATE TABLE `mars_micro_user_events` (
`id` bigint,
`user_id` bigint DEFAULT NULL ,
`group_type` int DEFAULT NULL,
`group_id` int DEFAULT NULL,
`event_type` varchar(45) DEFAULT NULL,
`event_name` varchar(45) DEFAULT NULL,
`event_count` int DEFAULT NULL,
`event_time` bigint DEFAULT NULL,
`created_time` bigint DEFAULT NULL,
`updated_time` bigint DEFAULT NULL
) ENGINE=OLAP
DUPLICATE KEY(id)
COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "3"
);
DataX 配置JSON文件 (mysqlToDoris.json)
{
"core":{
"transport": {
"channel": {
"speed": {
"byte": 104857600,
"record": 200000
}
}
}
},
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "dev",
"password": "123456",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://mysql.xxx.cn:3306/event_db"
],
"querySql": [
"select id,user_id,group_type,group_id,event_type,event_name,event_time,created_time,updated_time from eventc_db.user_events where event_time>=${StartTime} and event_time<${EndTime};"
]
}
]
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"username": "root",
"password": "",
"database": "event_db",
"table": "events",
"column"
: [ "id", "group_type","group_id","event_type","event_name","event_time","created_time","updated_time"],
"preSql": [],
"postSql": [],
"jdbcUrl": "jdbc:mysql://cdh3:9030/",
"feLoadUrl": ["cdh3:8030"],
"beLoadUrl": ["cdh1:8044", "cdh2:8044", "cdh3:8044"],
"loadProps": {
},
"maxBatchRows" : 200000,
"maxBatchByteSize" : 104857600,
"lineDelimiter": "\n"
}
}
}
]
}
}
core与job参数介绍
| 配置 | 说明 |
|---|
| core.transport.channel.speed.byte | 单个channel容纳最多的字节数 |
| core.transport.channel.speed.record | 单个channel容纳最多的record数 |
| job.setting.speed.channel | 该job所需要的channel的个数 |
| job.setting.speed.byte | 该job最大的流量 |
| job.setting.speed.record | 该job最大的record流量 |
doriswriter 参数介绍
| 配置 | 说明 |
|---|
| username | 数据库的用户名 |
| password | 数据库的密码 |
| database | 表的数据库名称 |
| table | 表的表名称 |
| jdbcUrl | 数据库的 JDBC 连接信息 |
| loadUrl | FE的地址用于Stream Load |
| feLoadUrl | FE的地址 |
| beLoadUrl | BE的地址 |
| column | 需要写入数据的字段 |
| preSql | 写入数据到目的表前,会先执行这里的标准语句 |
| postSql | 写入数据到目的表后,会执行这里的标准语句 |
| loadProps | Stream Load 的请求参数 |
| maxBatchRows | 每批次导入数据的最大行数 |
| maxBatchByteSize | 每批次导入数据的最大数据量 |
| labelPrefix | 每批次导入任务的 label 前缀 |
| lineDelimiter | 每批次数据包含多行,,每行的的分隔符 |
| connectTimeout | Stream Load单次请求的超时时间, 单位毫秒 |
执行任务
python /opt/app/datax/bin/datax.py /opt/app/datax/bin/mysqlToDoris.json -p "-DStartTime=1546272000000 -DEndTime=1650791448000"
性能测试
mysql events表数据量有 8310077条
Doris FE一台机器,BE三台
CPU 8核,内存64G
测试A
| 配置 | 值 |
| core.transport.channel.speed.byte | 1048576 |
| core.transport.channel.speed.record | 10000 |
| doriswriter maxBatchByteSize | 104857600 |
| doriswriter maxBatchRows | 10000 |
测试B
| 配置 | 值 |
|---|
| core.transport.channel.speed.byte | 1048576 |
| core.transport.channel.speed.record | 100000 |
| doriswriter maxBatchByteSize | 104857600 |
| doriswriter maxBatchRows | 100000 |
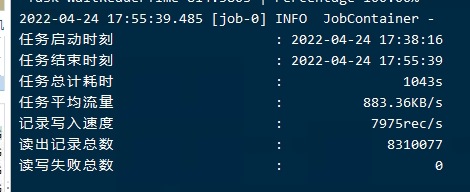
测试C
| 配置 | 值 |
|---|
| core.transport.channel.speed.byte | 104857600 |
| core.transport.channel.speed.record | 100000 |
| doriswriter maxBatchByteSize | 104857600 |
| doriswriter maxBatchRows | 100000 |
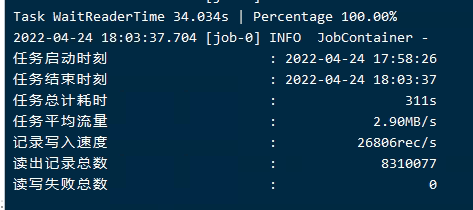
测试D
| 配置 | 值 |
|---|
| core.transport.channel.speed.byte | 104857600 |
| core.transport.channel.speed.record | 500000 |
| doriswriter maxBatchByteSize | 104857600 |
| doriswriter maxBatchRows | 500000 |
挂了
测试E
| 配置 | 说明 |
|---|
| core.transport.channel.speed.byte | 104857600 |
| core.transport.channel.speed.record | 200000 |
| doriswriter maxBatchByteSize | 104857600 |
| doriswriter maxBatchRows | 200000 |
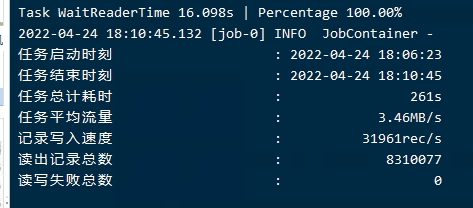
对于我用的测试机器,基本上维持高值3M左右
Bug 记录
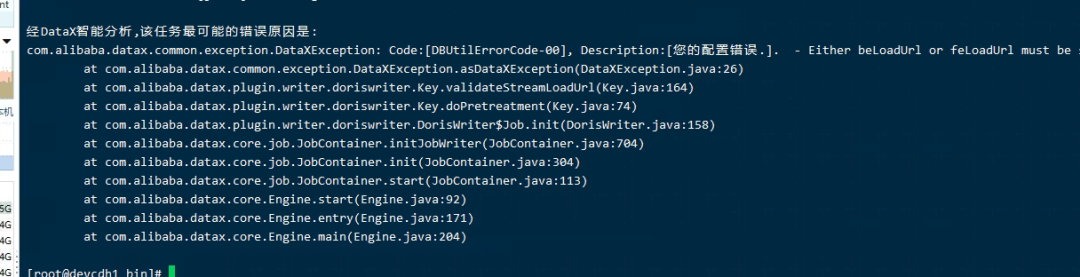
1. 配置beLoadUrl地址
注意FE,BE对应版本的地址与端口号。
2. 建表语句
建Doris表的时候没有报错问题,但是执行插入的时候数据进不去。
原来的建表语句
CREATE TABLE events
(
`id` bigint,
`user_id` bigint ,
`group_type` int,
`group_id` int,
`event_name` varchar(45),
`event_count` int,
`event_time` bigint,
`created_time` bgint,
`updated_time` bigint
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id, event_name,group_id) BUCKETS 6;
修改后的
CREATE TABLE mars_micro_user_events
(
`id` bigint,
`user_id` bigint ,
`group_type` int,
`group_id` int,
`event_name` varchar(45),
`event_count` int,
`event_time` bigint,
`created_time` bigint,
`updated_time` bigint
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 6
首先了解DUPLICATE KEY 数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。
分桶列可以是多列,但必须为Key 列。在此建表语句(DUPLICATE KEY)模型下,建表是不会报错的,如果选择的是其他聚合的模型则会直接报错。
- EOF -
关注「大数据与机器学习文摘」
看精选技术文章和最新行业资讯
点赞和在看就是最大的支持❤️










