Hi,大家好,我是晨曦
今天这期推文的主题来源于群里小伙伴的提问,这个小伙伴向晨曦提出了一个问题
A同学:晨曦,平时我们评价预测模型的时候遵循的就是区分度、校准度、临床决策曲线,那么我在网上很多教程上看到的DCA都是基于Logistic回归以及Cox回归,而且我在文章中也很少看到机器学习模型应用DCA的情况,那么究竟机器学习模型可否应用DCA来评价模型呢?
晨曦:........
那么,本期推文将着重临床决策曲线DCA在机器学习模型中的应用为主题,来看一看临床决策曲线如何应用在机器学习模型中以及我们究竟应该如何调整我们的代码逻辑
那么,我们开始吧
临床决策曲线DCA的相关概念以及应用场景在这里就不过多赘述了,如果对这方面知识还没有基本的了解,请各位小伙伴先阅读下面这篇推文,然后再阅读本期推文
解析临床决策曲线(DCA)
临床预测模型评价,不只有ROC,这个指标你遗漏了吗?
那么,我们接下来就以集成学习算法中的随机森林作为演示,来带领大家通过随机森林构建模型,然后通过DCA来评价模型
#准备工作library(mlr3)library(mlr3viz)library(mlr3learners)library(mlr3verse)library(mlr3tuning)library(data.table)library("magrittr")library(randomForest)
library(varSelRF)library(reshape2)source("ML讲席营/dca.R")
相信听过晨曦讲席营的小伙伴已经了解了进行机器学习更加先进的体系——mlr3体系,那么本期推文晨曦将采用双轨制代码的形式,那么首先我们就来演示如何通过基础R包来完成机器学习算法并且进行DCA曲线的绘制
#准备输入数据breast_cancer_task "breast_cancer")df $data()
如果有的小伙伴不知道mlr3体系的话,那么就把上面的代码当成获取输入数据即可,我们的输入数据如下所示

#划分数据集(留出交叉验证)index 2,nrow(df),replace = TRUE,prob=c(0.7,0.3))#划分训练集和测试集traindata 1,]#获取训练集testdata 2,]#获取测试集
#运用训练集构建随机森林模型df_rf class ~ ., data=traindata, ntree=400,important=TRUE,proximity=TRUE)
其实前面的步骤基本上都是基本建模的流程,我们重点其实是需要知道,我们想要绘制DCA只需要两类数据,一个是结局的编码(这里我们需要我们的编码是二分类并且是0和1的形式),然后我们需要提供我们机器学习模型预测阳性结局的概率
#获取预测数据并整理数据outcome = ifelse(testdata$class == "benign",0,1)#重编码响应变量,我们一般习惯阳性结局为1,阴性结局为0prob "outcome" = outcome, "rf_prob" = as.data.frame(prob)$malignant) head(prob)# outcome rf_prob#1 0 0.5150#2 0 0.0000#3 0 0.0400#4 0 0.0000#5 0 0.0000#6 1 0.9275
也就是说我们只要获得预测概率就可以绘制DCA,那么其实也就可以类比成ROC,我们可以做出以下总结:
1.绘制ROC:我们只需要两类数据——实际值 and 预测值
2.绘制DCA:我们只需要两类数据——实际值(重编码成0或者1的形式) and 预测概率(阳性结局)
#绘制DCAdcaoutput <- dca(data = prob, outcome = "outcome", predictors = c("rf_prob"), xstart = 0, xstop = 1, ymin = 0)
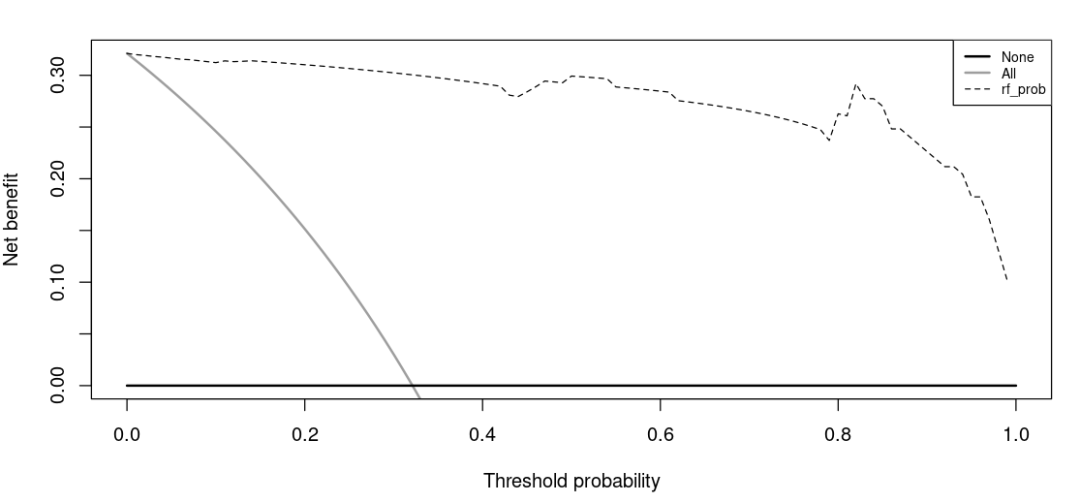
注意:这个自创函数并没有提供修改图例的参数,但是我们可以通过修改底层代码来修改图例的位置以及大小(在代码的最后几行)
#当然我们也可以通过导入到ggplot2来进行DIYdcadf $net.benefit)# 宽数据转长数据temp "threshold",measure=c("rf_prob","all","none"))
ggplot(temp,aes(x=threshold,y=value,colour=variable))+geom_line()+ coord_cartesian(xlim=c(0,1), ylim=c(-0.05,0.5))+ scale_color_discrete(name="Model",labels=c("ranger","all","none"))+ labs(x="Threshold probability (%)")+labs(y="Net benefit")+ theme_bw()+ theme(panel.grid.major=element_blank(), panel.grid.minor=element_blank(), legend.title=element_blank())
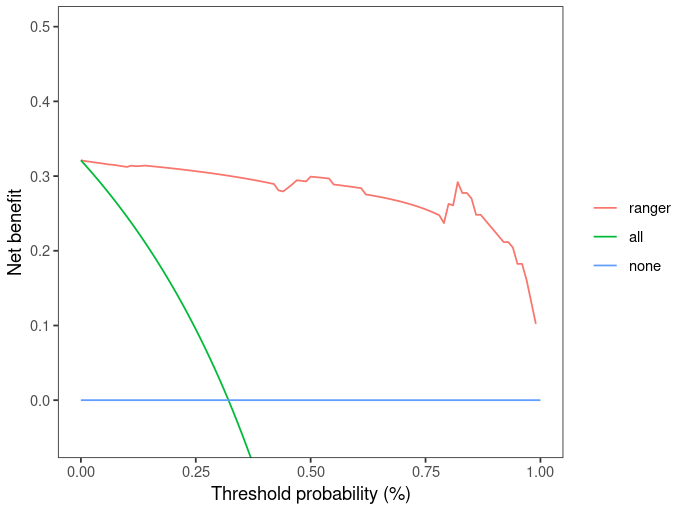
好,那么到这里就演示完了基础R包如何完成机器学习模型的构建并进行DCA的绘制,那么我们接下来再快速来一遍mlr3体系
reast_cancer_task "breast_cancer")breast_cancer_task$positive
train_set $nrow,0.8*breast_cancer_task$nrow)test_set $nrow),train_set)lrn "classif.ranger",predict_type = "prob")lrn$train(breast_cancer_task,row_ids = train_set)pred $predict(breast_cancer_task,row_ids = test_set)outcome $truth == "malignant",1,0)prob "outcome" = outcome, "rf_prob" = pred$prob[,1])dcaoutput "outcome", predictors = c("rf_prob"), xstart = 0, xstop = 1, ymin = 0)
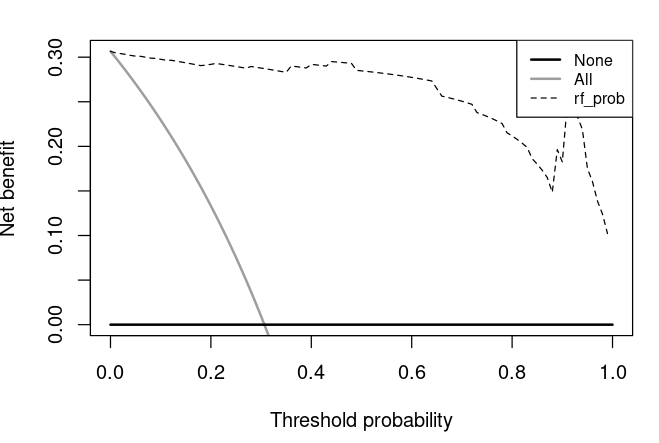
当然有了结果我们后期DIY也是可以按照前面的流程进行的
那么到这里本期推文到这里就结束了,这篇推文算的上是对前面推文的一个扩展,解决了我们针对机器学习模型绘制DCA的问题,还是那句话,我们只需要知道绘制可视化需要什么样的数据,那么我们只需要准备好相关的数据即可
还是那句比较重要的总结:
1.绘制ROC:我们只需要两类数据——实际值 and 预测值
2.绘制DCA:我们只需要两类数据——实际值(重编码成0或者1的形式) and 预测概率(阳性结局)
那么,本期推文到这里就结束啦~
我是晨曦,我们下期再见QAQ
Ps:回复“机器学习DCA”可以得到本期推文内的“dca.R"脚本
1.R语言超详细Logistic回归模型进行临床决策曲线绘制(DCA) - 简书 (jianshu.com)3.决策曲线(Decision Curve Analysis)的绘制(R语言) - 简书 (jianshu.com)4.DCA source: R/dca.R (rdrr.io)


欢迎大家关注解螺旋生信频道-挑圈联靠公号~